mirror of
https://github.com/Evil0ctal/Douyin_TikTok_Download_API.git
synced 2025-04-22 10:21:03 +08:00
Delete PyPi directory
This commit is contained in:
parent
bb56468667
commit
c87f6978c5
21
PyPi/LICENSE
21
PyPi/LICENSE
@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2021 Evil0ctal
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
502
PyPi/README.md
502
PyPi/README.md
@ -1,502 +0,0 @@
|
||||
<h1 align="center">
|
||||
<br>
|
||||
<a href="https://douyin.wtf/" alt="logo" ><img src="https://raw.githubusercontent.com/Evil0ctal/Douyin_TikTok_Download_API/main/logo/logo192.png" width="150"/></a>
|
||||
<br>
|
||||
Douyin_TikTok_Download_API(抖音/TikTok无水印解析API)
|
||||
<br>
|
||||
</h1>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/Evil0ctal/Douyin_TikTok_Download_API#%E8%BF%90%E8%A1%8C%E8%AF%B4%E6%98%8E%E7%BB%8F%E8%BF%87%E6%B5%8B%E8%AF%95%E8%BF%87%E7%9A%84python%E7%89%88%E6%9C%AC%E4%B8%BA38">运行说明</a> •
|
||||
<a href="https://github.com/Evil0ctal/Douyin_TikTok_Download_API/#%EF%B8%8Fapi使用">API使用</a> •
|
||||
<a href="https://github.com/Evil0ctal/Douyin_TikTok_Download_API#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-%E6%89%8B%E5%8A%A8%E9%83%A8%E7%BD%B2">手动部署</a> •
|
||||
<a href="https://github.com/Evil0ctal/Douyin_TikTok_Download_API#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker">Docker部署</a> •
|
||||
<a href="https://hub.docker.com/repository/docker/evil0ctal/douyin_tiktok_download_api">Docker镜像</a> •
|
||||
<a href="https://github.com/Evil0ctal/Douyin_TikTok_Download_API#%EF%B8%8F-贡献者">贡献者</a>
|
||||
</p>
|
||||
|
||||
<hr>
|
||||
|
||||

|
||||
[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/blob/main/LICENSE)
|
||||
[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/issues)
|
||||
[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/network)
|
||||
[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/stargazers)
|
||||
[](https://hub.docker.com/repository/docker/evil0ctal/douyin_tiktok_download_api)
|
||||
|
||||
Language: [[English](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.en.md)] [[简体中文](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.md)] [[繁体中文](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.zh-TW.md)]
|
||||
|
||||
> Note: This API is applicable to Douyin and TikTok. Douyin is TikTok in China. You can distribute or modify the code at
|
||||
> will, but please mark the original author.
|
||||
|
||||
## 👻介绍
|
||||
|
||||
> 出于稳定性的考虑,暂时关闭演示站的/video(返回mp4文件)和/music(返回mp3文件)
|
||||
> 这两个功能,同时结果页面的批量下载功能也暂时不可用,如有需求请自行部署,其他功能在演示站上仍正常使用,API服务器保证99%的时间正常运行,但不保证解析100%成功,如果解析失败请等一两分钟后重试。
|
||||
|
||||
🚀演示地址:[https://douyin.wtf/](https://douyin.wtf/)
|
||||
|
||||
🛰API演示:[https://api.douyin.wtf/](https://api.douyin.wtf/)
|
||||
|
||||
💾iOS快捷指令(中文): [点击获取](https://www.icloud.com/shortcuts/331073aca78345cf9ab4f73b6a457f97) (
|
||||
更新于2022/07/18,快捷指令可自动检查更新,安装一次即可。)
|
||||
|
||||
🌎iOS Shortcut(English): [Click to get](https://www.icloud.com/shortcuts/83548306bc0c4f8ea563108f79c73f8d) (Updated on
|
||||
2022/07/18, this shortcut will automatically check for updates, only need to install it once.)
|
||||
|
||||
🗂快捷指令历史版本: [Shortcuts release](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/53)
|
||||
|
||||
📦️Tiktok/抖音下载器(桌面应用):[TikDown](https://github.com/Tairraos/TikDown/)
|
||||
|
||||
本项目使用 [PyWebIO](https://github.com/pywebio/PyWebIO)、[Flask](https://github.com/pallets/flask)
|
||||
,利用Python实现在线批量解析抖音的无水印视频/图集。
|
||||
|
||||
可用于下载作者禁止下载的视频,或者进行数据爬取等等,同时可搭配[iOS自带的快捷指令APP](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)
|
||||
配合本项目API实现应用内下载。
|
||||
|
||||
快捷指令需要在抖音或TikTok的APP内,选择你想要保存的视频,点击分享按钮,然后找到 "抖音TikTok无水印下载"
|
||||
这个选项,如遇到通知询问是否允许快捷指令访问xxxx (域名或服务器),需要点击允许才可以正常使用,下载成功的视频或图集会保存在一个专门的相册中以方便浏览。
|
||||
|
||||
## 💡项目文件结构
|
||||
|
||||
```
|
||||
# 请根据需要自行修改config.ini中的内容
|
||||
.
|
||||
└── Douyin_TikTok_Download_API/
|
||||
├── /static(静态前端资源)
|
||||
├── web_zh.py(网页入口)
|
||||
├── web_api.py(API)
|
||||
├── scraper.py(解析库)
|
||||
├── config.ini(所有项目的配置文件,包含端口及代理等,如需请自行修改该文件。)
|
||||
├── logs.txt(错误日志,自动生成。)
|
||||
└── API_logs.txt(API调用日志,自动生成。)
|
||||
```
|
||||
|
||||
## 💯已支持功能:
|
||||
|
||||
- 支持抖音视频/图集解析
|
||||
- 支持海外TikTok视频解析
|
||||
- 支持批量解析(支持抖音/TikTok混合解析)
|
||||
- 解析结果页批量下载无水印视频
|
||||
- 制作[pip包](https://pypi.org/project/DT-Scraper/)方便使用
|
||||
- 支持API调用
|
||||
- 支持使用代理解析
|
||||
- 支持[iOS快捷指令](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)实现应用内下载无水印视频/图集
|
||||
|
||||
---
|
||||
|
||||
## 🤦后续功能:
|
||||
|
||||
- [ ] 支持输入(抖音/TikTok)作者主页链接实现批量解析
|
||||
|
||||
---
|
||||
|
||||
## 🧭运行说明(经过测试过的Python版本为3.8):
|
||||
> 🚨如果你要部署本项目,请参考部署方式([Docker部署](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker "Docker部署"), [手动部署](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-%E6%89%8B%E5%8A%A8%E9%83%A8%E7%BD%B2 "手动部署"))
|
||||
|
||||
- 克隆本仓库:
|
||||
|
||||
```console
|
||||
git clone https://github.com/Evil0ctal/Douyin_TikTok_Download_API.git
|
||||
```
|
||||
|
||||
- 移动至仓库目录:
|
||||
|
||||
```console
|
||||
cd Douyin_TikTok_Download_API
|
||||
```
|
||||
|
||||
- 安装依赖库:
|
||||
|
||||
```console
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
- 修改config.ini(可选):
|
||||
|
||||
```console
|
||||
vim config.ini
|
||||
```
|
||||
|
||||
- 网页解析
|
||||
|
||||
```console
|
||||
# 运行web_zh.py
|
||||
python3 web_zh.py
|
||||
```
|
||||
|
||||
- API
|
||||
|
||||
```console
|
||||
# 运行web_api.py
|
||||
python3 web_api.py
|
||||
```
|
||||
|
||||
- 调用解析库
|
||||
|
||||
```python
|
||||
# pip install DT-Scraper
|
||||
from DT_scraper.scraper import Scraper
|
||||
|
||||
api = Scraper()
|
||||
|
||||
# 解析Douyin视频/图集
|
||||
douyin_data = api.douyin(input('抖音视频链接:'))
|
||||
# 返回字典
|
||||
print(douyin_data)
|
||||
|
||||
# Parsing TikTok Videos/Galleries
|
||||
tiktok_data = api.tiktok(input('TikTok video URL:'))
|
||||
# return dictionary
|
||||
print(tiktok_data)
|
||||
|
||||
# 使用代理进行解析(Parse using a proxy)
|
||||
api.tiktok(input('TikTok video URL:'), proxies = {"all": "127.0.0.1:2333"})
|
||||
|
||||
```
|
||||
|
||||
- 入口(端口可在config.ini文件中修改)
|
||||
|
||||
```text
|
||||
网页入口:
|
||||
http://localhost(服务器IP):5000/
|
||||
API入口:
|
||||
http://localhost(服务器IP):2333/
|
||||
```
|
||||
|
||||
## 🗺️支持的提交格式(包含但不仅限于以下例子):
|
||||
|
||||
- 抖音分享口令 (APP内复制)
|
||||
|
||||
```text
|
||||
例子:7.43 pda:/ 让你在几秒钟之内记住我 https://v.douyin.com/L5pbfdP/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
```
|
||||
|
||||
- 抖音短网址 (APP内复制)
|
||||
|
||||
```text
|
||||
例子:https://v.douyin.com/L4FJNR3/
|
||||
```
|
||||
|
||||
- 抖音正常网址 (网页版复制)
|
||||
|
||||
```text
|
||||
例子:
|
||||
https://www.douyin.com/video/6914948781100338440
|
||||
```
|
||||
|
||||
- 抖音发现页网址 (APP复制)
|
||||
|
||||
```text
|
||||
例子:
|
||||
https://www.douyin.com/discover?modal_id=7069543727328398622
|
||||
```
|
||||
|
||||
- TikTok短网址 (APP内复制)
|
||||
|
||||
```text
|
||||
例子:
|
||||
https://vm.tiktok.com/TTPdkQvKjP/
|
||||
```
|
||||
|
||||
- TikTok正常网址 (网页版复制)
|
||||
|
||||
```text
|
||||
例子:
|
||||
https://www.tiktok.com/@tvamii/video/7045537727743380782
|
||||
```
|
||||
|
||||
- 抖音/TikTok批量网址(无需使用符合隔开)
|
||||
|
||||
```text
|
||||
例子:
|
||||
2.84 nqe:/ 骑白马的也可以是公主%%百万转场变身 https://v.douyin.com/L4FJNR3/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
8.94 mDu:/ 让你在几秒钟之内记住我 https://v.douyin.com/L4NpDJ6/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
9.94 LWz:/ ok我坦白交代 %%knowknow https://v.douyin.com/L4NEvNn/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
https://www.tiktok.com/@gamer/video/7054061777033628934
|
||||
https://www.tiktok.com/@off.anime_rei/video/7059609659690339586
|
||||
https://www.tiktok.com/@tvamii/video/7045537727743380782
|
||||
```
|
||||
|
||||
## 🛰️API使用
|
||||
|
||||
API可将请求参数转换为需要提取的无水印视频/图片直链,配合IOS捷径可实现应用内下载。
|
||||
|
||||
- 解析请求参数
|
||||
|
||||
```text
|
||||
http://localhost(服务器IP):2333/api?url="复制的(抖音/TikTok)口令/链接"
|
||||
```
|
||||
|
||||
- 返回参数
|
||||
|
||||
> 抖音视频
|
||||
|
||||
```json
|
||||
{
|
||||
"analyze_time": "1.9043s",
|
||||
"api_url": "https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6918273131559881997",
|
||||
"nwm_video_url": "http://v3-dy-o.zjcdn.com/23f0dec312ede563bef881af9a88bdc7/624dd965/video/tos/cn/tos-cn-ve-15/eccedcf4386948f5b5a1f0bcfb3dcde9/?a=1128&br=2537&bt=2537&cd=0%7C0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=sYGC~3E7nz7Th1PZSDXq&l=202204070118030102080650132A21E31F&lr=&mime_type=video_mp4&net=0&pl=0&qs=0&rc=M3hleDRsODlkMzMzaGkzM0ApODpmNWc4ODs5N2lmNzg5aWcpaGRqbGRoaGRmLi4ybnBrbjYuYC0tYy0wc3MtYmJjNTM2NjAtNDFjMzJgOmNwb2wrbStqdDo%3D&vl=&vr=",
|
||||
"original_url": "https://v.douyin.com/L4FJNR3/",
|
||||
"platform": "douyin",
|
||||
"status": "success",
|
||||
"url_type": "video",
|
||||
"video_author": "Real机智张",
|
||||
"video_author_id": "Rea1yaoyue",
|
||||
"video_author_signature": "",
|
||||
"video_author_uid": "59840491348",
|
||||
"video_aweme_id": "6918273131559881997",
|
||||
"video_comment_count": "89145",
|
||||
"video_create_time": "1610786002",
|
||||
"video_digg_count": "2968195",
|
||||
"video_hashtags": [
|
||||
"百万转场变身"
|
||||
],
|
||||
"video_music": "https://sf3-cdn-tos.douyinstatic.com/obj/ies-music/6910889805266504461.mp3",
|
||||
"video_music_author": "梅尼耶",
|
||||
"video_music_id": "6910889820861451000",
|
||||
"video_music_mid": "6910889820861451021",
|
||||
"video_music_title": "@梅尼耶创作的原声",
|
||||
"video_play_count": "0",
|
||||
"video_share_count": "74857",
|
||||
"video_title": "骑白马的也可以是公主#百万转场变身",
|
||||
"wm_video_url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300ffe0000c01a96q5nis1qu5b1u10&ratio=720p&line=0"
|
||||
}
|
||||
```
|
||||
|
||||
> 抖音图集
|
||||
|
||||
```json
|
||||
{
|
||||
"album_author": "治愈图集",
|
||||
"album_author_id": "ZYTJ2002",
|
||||
"album_author_signature": "取无水印图",
|
||||
"album_author_uid": "449018054867063",
|
||||
"album_aweme_id": "7015137063141920030",
|
||||
"album_comment_count": "5436",
|
||||
"album_create_time": "1633338878",
|
||||
"album_digg_count": "193734",
|
||||
"album_hashtags": [
|
||||
"晚霞",
|
||||
"治愈系",
|
||||
"落日余晖",
|
||||
"日落🌄"
|
||||
],
|
||||
"album_list": [
|
||||
"https://p26-sign.douyinpic.com/tos-cn-i-0813/5223757a7bef4f8480cd25d0fa2d2d94~noop.webp?x-expires=1651856400&x-signature=K1VjJdWTHCAaYSz14y6NumjjtfI%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47",
|
||||
"https://p26-sign.douyinpic.com/tos-cn-i-0813/d99467672da840908acccf2d2b4b7ef7~noop.webp?x-expires=1651856400&x-signature=ncBb8Tt7z4PmpUyiCNr%2FJYnwRSA%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47",
|
||||
"https://p26-sign.douyinpic.com/tos-cn-i-0813/5c2562210b1a4d4c99d6d4dbd2f23f2b~noop.webp?x-expires=1651856400&x-signature=Rsmplb53IKfvKd3mmIb4iQNhlIE%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47",
|
||||
"https://p26-sign.douyinpic.com/tos-cn-i-0813/9bb74c0c6aff4217bd1491a077b2c817~noop.webp?x-expires=1651856400&x-signature=BLRyHoKP0ybIci57yneOca62dxI%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47"
|
||||
],
|
||||
"album_music": "https://sf6-cdn-tos.douyinstatic.com/obj/ies-music/6978805801733442341.mp3",
|
||||
"album_music_author": "魏同学",
|
||||
"album_music_id": "6978805810365271000",
|
||||
"album_music_mid": "6978805810365270791",
|
||||
"album_music_title": "@魏同学创作的原声",
|
||||
"album_play_count": "0",
|
||||
"album_share_count": "30717",
|
||||
"album_title": "“山海自有归期 风雨自有相逢 意难平终将和解 万事终将如意”#晚霞 #治愈系 #落日余晖 #日落🌄",
|
||||
"analyze_time": "1.0726s",
|
||||
"api_url": "https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=7015137063141920030",
|
||||
"original_url": "https://v.douyin.com/Nb8jysN/",
|
||||
"platform": "douyin",
|
||||
"status": "success",
|
||||
"url_type": "album"
|
||||
}
|
||||
```
|
||||
|
||||
> TikTok视频
|
||||
|
||||
```JSON
|
||||
{
|
||||
"analyze_time": "5.0863s",
|
||||
"nwm_video_url": "https://v19.tiktokcdn-us.com/cfa357dadd8f913f013a6d0b0dca293f/624e20fa/video/tos/useast5/tos-useast5-ve-0068c003-tx/3296231486014755a1b81aa70c349a53/?a=1233&br=6498&bt=3249&cd=0%7C0%7C0%7C3&ch=0&cr=3&cs=0&cv=1&dr=0&ds=6&er=&ft=bY1KJnB4TJBS6BMy-L1iVKP&l=20220406172333010113135214232FAB56&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=MzpsaGY6Zjo7PDMzZzczNEApNjY6ZTtkOzxpN2Q3PDo5OmdgZ2BtcjQwai9gLS1kMS9zczJhLTEzYjEuMTJeXzQyLmM6Yw%3D%3D&vl=&vr=",
|
||||
"original_url": "https://www.tiktok.com/@oregonzoo/video/7080938094823738666",
|
||||
"platform": "tiktok",
|
||||
"status": "success",
|
||||
"url_type": "video",
|
||||
"video_author": "oregonzoo",
|
||||
"video_author_SecId": "MS4wLjABAAAArWNQ8-AZN6CxWOkqdeWsMBUuLDmJt8TWUAk0S4aWDW5V5EoqRbuczhaLnxJHCGob",
|
||||
"video_author_diggCount": 94,
|
||||
"video_author_followerCount": 1800000,
|
||||
"video_author_followingCount": 39,
|
||||
"video_author_heartCount": 29700000,
|
||||
"video_author_id": "6699816060206171141",
|
||||
"video_author_nickname": "Oregon Zoo",
|
||||
"video_author_videoCount": 264,
|
||||
"video_aweme_id": "7080938094823738666",
|
||||
"video_comment_count": 61,
|
||||
"video_create_time": "1648659375",
|
||||
"video_digg_count": 11800,
|
||||
"video_hashtags": [
|
||||
"redpanda",
|
||||
"boop",
|
||||
"sunshine"
|
||||
],
|
||||
"video_music": "https://sf16.tiktokcdn-us.com/obj/ies-music-tx/7075363935741856558.mp3",
|
||||
"video_music_author": "Gilderoy Dauterive",
|
||||
"video_music_id": "7075363884613356330",
|
||||
"video_music_title": "Be the Sunshine",
|
||||
"video_music_url": "https://sf16.tiktokcdn-us.com/obj/ies-music-tx/7075363935741856558.mp3",
|
||||
"video_play_count": 60100,
|
||||
"video_ratio": "720p",
|
||||
"video_share_count": 298,
|
||||
"video_title": "Moshu ✨ #redpanda #boop #sunshine",
|
||||
"wm_video_url": "https://v16m-webapp.tiktokcdn-us.com/0394b9183a5852d4392a7e804bf78c55/624e20f6/video/tos/useast5/tos-useast5-ve-0068c001-tx/fc63ae232e70466398b55ccf97eb3c67/?a=1988&br=6468&bt=3234&cd=0%7C0%7C1%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=XY53A3E7nz7Th-pZSDXq&l=202204061723290101131351171341B9BB&lr=tiktok_m&mime_type=video_mp4&net=0&pl=0&qs=0&rc=MzpsaGY6Zjo7PDMzZzczNEApOjo4aDMzZmRlN2loOWk6ZWdgZ2BtcjQwai9gLS1kMS9zczBhNGA0LTIwNjNiYDQ2YmE6Yw%3D%3D&vl=&vr="
|
||||
}
|
||||
```
|
||||
|
||||
- 下载视频请求参数
|
||||
|
||||
```text
|
||||
http://localhost(服务器IP):2333/video?url="复制的(抖音/TikTok)口令/链接"
|
||||
# 返回无水印mp4文件
|
||||
```
|
||||
|
||||
- 下载音频请求参数
|
||||
|
||||
```text
|
||||
http://localhost(服务器IP):2333/music?url="复制的(抖音/TikTok)口令/链接"
|
||||
# 返回mp3文件
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 💾部署(方式一 手动部署)
|
||||
|
||||
> 注:
|
||||
> 截图可能因更新问题与文字不符,一切请优先参照文字叙述。
|
||||
|
||||
> 最好将本项目部署至海外服务器(优先选择美国地区的服务器),否则可能会出现奇怪的问题。
|
||||
|
||||
例子:
|
||||
项目部署在国内服务器,而人在美国,点击结果页面链接报错403 ,目测与抖音CDN有关系。
|
||||
项目部署在韩国服务器,解析TikTok报错 ,目测TikTok对某些地区或IP进行了限制。
|
||||
|
||||
> 使用宝塔Linux面板进行部署(
|
||||
> 中文宝塔要强制绑定手机号了,很流氓且无法绕过,建议使用宝塔国际版,谷歌搜索关键字aapanel自行安装,部署步骤相似。)
|
||||
|
||||
- 首先要去安全组开放5000和2333端口(Web默认5000,API默认2333,可以在文件config.ini中修改。)
|
||||
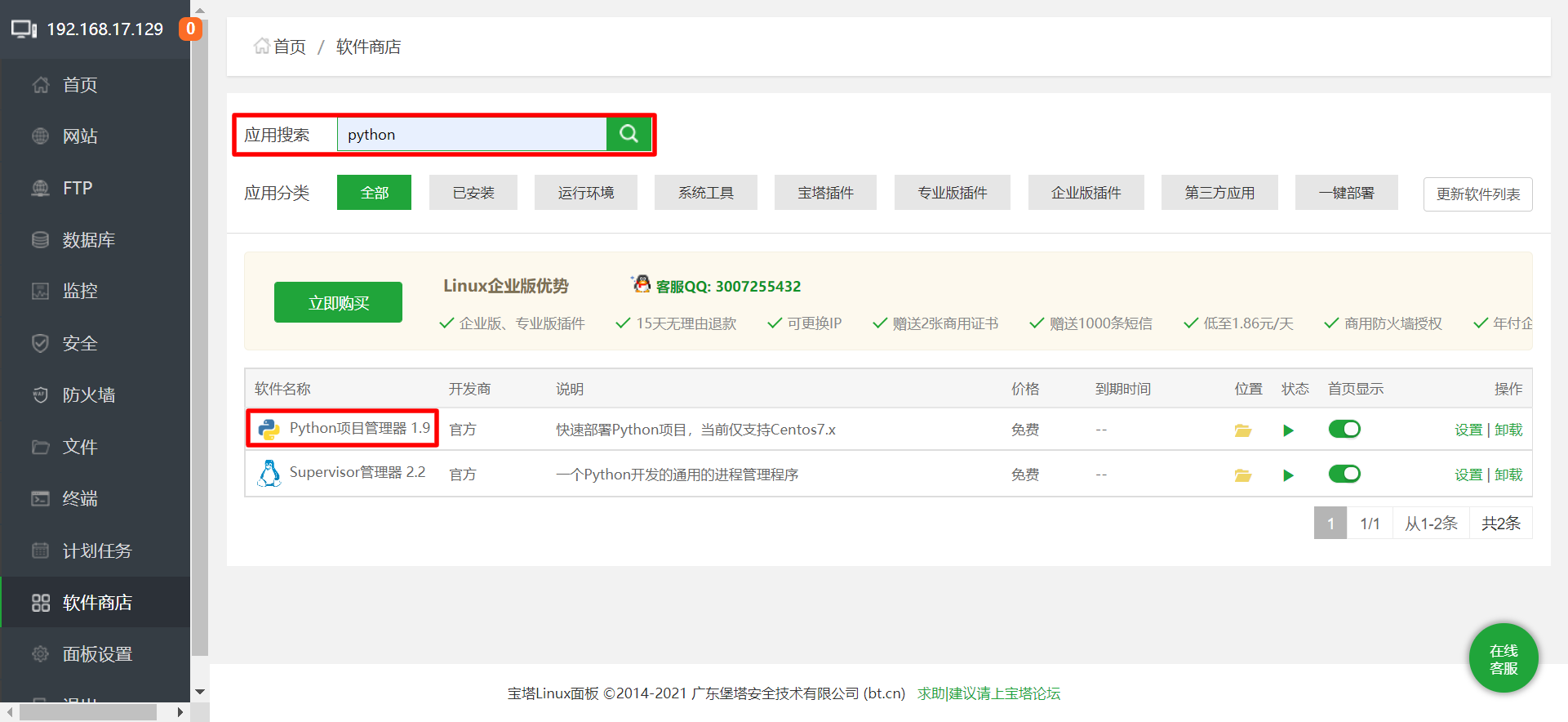
- 在宝塔应用商店内搜索python并安装项目管理器 (推荐使用1.9版本)
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
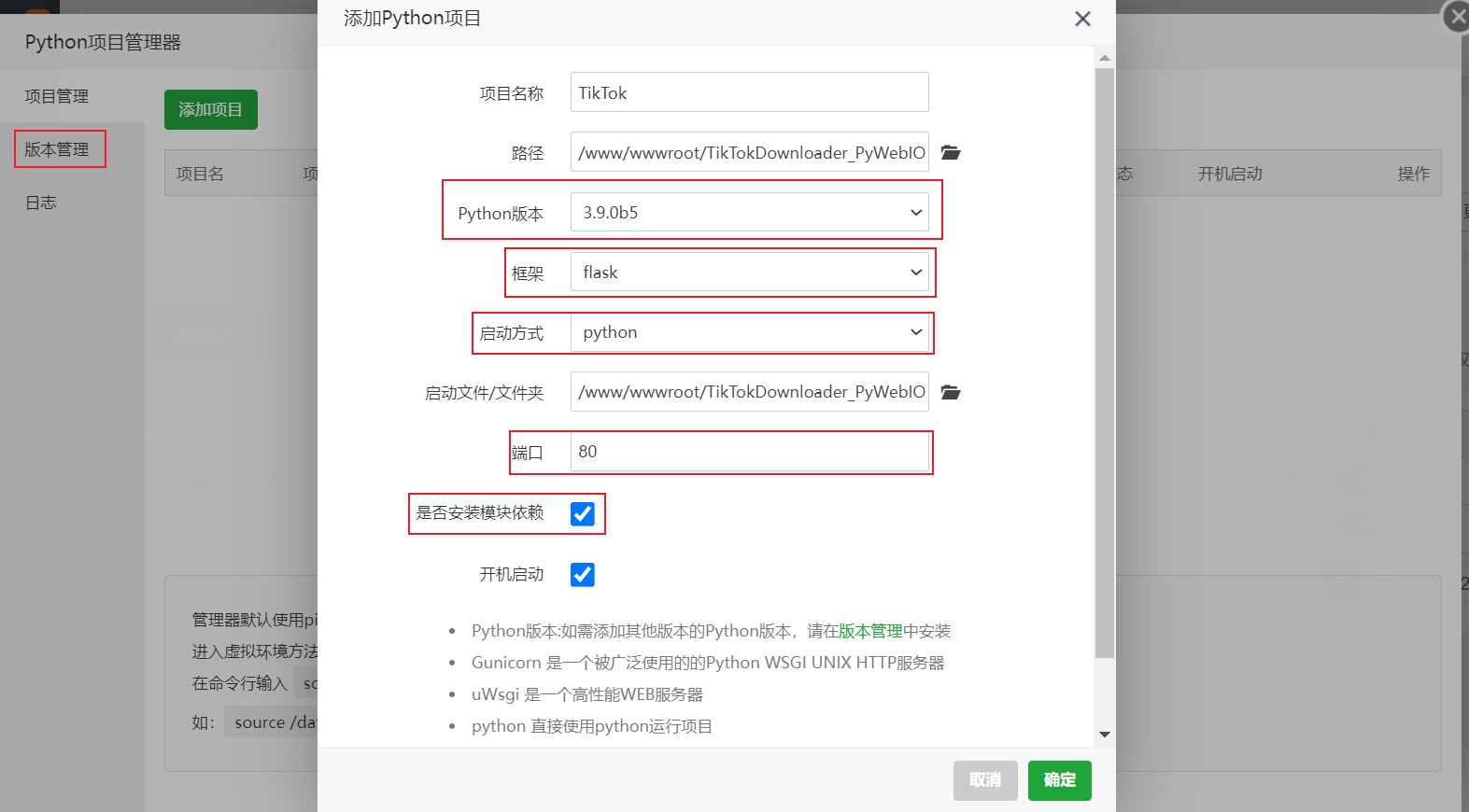
- 创建一个项目名字随意
|
||||
- 路径选择你上传文件的路径
|
||||
- Python版本需要至少3以上(在左侧版本管理中自行安装)
|
||||
- 框架修改为`Flask`
|
||||
- 启动方式修改为`python`
|
||||
- Web启动文件选择`web_zh.py`
|
||||
- API启动文件选择`web_api.py`
|
||||
- 勾选安装模块依赖
|
||||
- 开机启动随意
|
||||
- 如果宝塔运行了`Nginx`等其他服务时请自行判断端口是否被占用,运行端口可在文件config.ini中修改。
|
||||
|
||||
|
||||
|
||||
- 如果有大量请求请使用进程守护启动防止进程关闭
|
||||
|
||||
---
|
||||
|
||||
## 💾部署(方式二 Docker)
|
||||
|
||||
- 安装docker
|
||||
|
||||
```yaml
|
||||
curl -fsSL get.docker.com -o get-docker.sh&&sh get-docker.sh &&systemctl enable docker&&systemctl start docker
|
||||
```
|
||||
|
||||
- 留下config.int和docker-compose.yml文件即可
|
||||
- 运行命令,让容器在后台运行
|
||||
|
||||
```yaml
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
- 查看容器日志
|
||||
|
||||
```yaml
|
||||
docker logs -f douyin_tiktok_download_api
|
||||
```
|
||||
|
||||
- 删除容器
|
||||
|
||||
```yaml
|
||||
docker rm -f douyin_tiktok_download_api
|
||||
```
|
||||
|
||||
- 更新
|
||||
|
||||
```yaml
|
||||
docker compose pull && docker compose down && docker compose up -d
|
||||
```
|
||||
|
||||
## ❤️ 贡献者
|
||||
|
||||
[](https://github.com/Evil0ctal)
|
||||
[](https://github.com/jw-star)
|
||||
[](https://github.com/Jeffrey-deng)
|
||||
[](https://github.com/chris-ss)
|
||||
[](https://github.com/weixuan00)
|
||||
[](https://github.com/Tairraos)
|
||||
|
||||
## 🎉截图
|
||||
|
||||
> 注:
|
||||
> 截图可能因更新问题与文字不符,一切请优先参照文字叙述。
|
||||
|
||||
<details><summary>点击展开截图</summary>
|
||||
|
||||
<hr>
|
||||
|
||||
- 主界面
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
- 解析完成
|
||||
|
||||
> 单个
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
> 批量
|
||||
|
||||

|
||||
|
||||
---
|
||||
|
||||
- API提交/返回
|
||||
|
||||
> 视频返回值
|
||||
|
||||

|
||||
|
||||
> 图集返回值
|
||||
|
||||

|
||||
|
||||
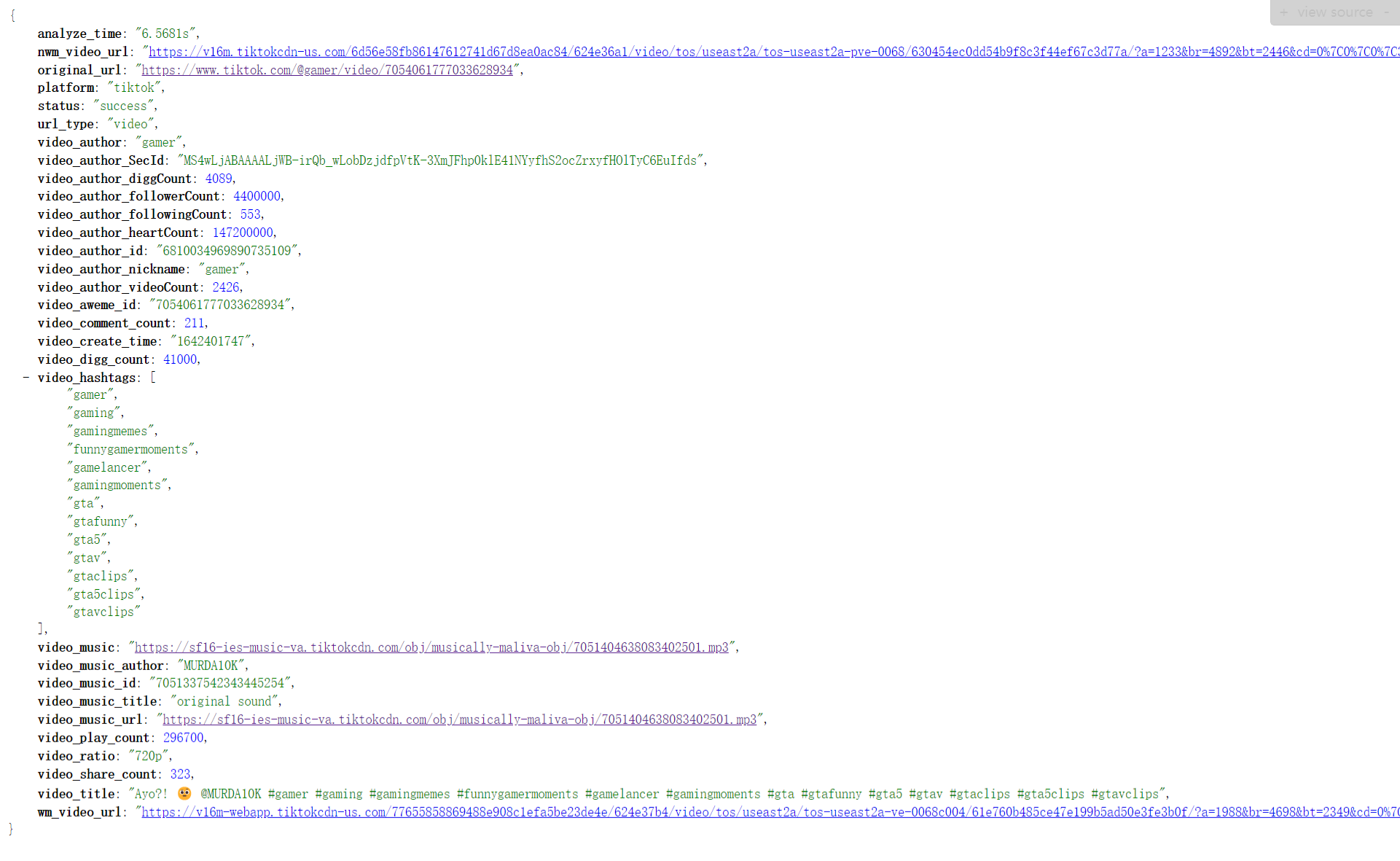
> TikTok返回值
|
||||
|
||||
|
||||
|
||||
---
|
||||
|
||||
</details>
|
||||
|
||||
## :alembic: 技术栈
|
||||
|
||||
* [PyWebIO](https://www.pyweb.io/) + [Flask](https://flask.palletsprojects.com/)
|
||||
|
||||
## :scroll: 许可证
|
||||
|
||||
MIT License
|
||||
|
||||
---
|
||||
> GitHub [@Evil0ctal](https://github.com/Evil0ctal) ·
|
||||
> Email Evil0ctal1985@gmail.com
|
||||
BIN
PyPi/dist/DT_Scraper-1.0.0.tar.gz
vendored
BIN
PyPi/dist/DT_Scraper-1.0.0.tar.gz
vendored
Binary file not shown.
BIN
PyPi/dist/DT_Scraper-1.0.1.tar.gz
vendored
BIN
PyPi/dist/DT_Scraper-1.0.1.tar.gz
vendored
Binary file not shown.
@ -1,6 +0,0 @@
|
||||
[build-system]
|
||||
requires = [
|
||||
"setuptools>=42",
|
||||
"wheel"
|
||||
]
|
||||
build-backend = "setuptools.build_meta"
|
||||
@ -1,53 +0,0 @@
|
||||
#! /usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# RUN Command Line:
|
||||
# python3 setup.py sdist (Build-check dist folder)
|
||||
# python3 -m twine upload --repository pypi dist/* (Upload to PyPi)
|
||||
|
||||
try:
|
||||
from setuptools import setup
|
||||
except ImportError:
|
||||
from distutils.core import setup
|
||||
import setuptools
|
||||
|
||||
setup(
|
||||
name='DT_Scraper', # 包的名字
|
||||
author='Evil0ctal', # 作者
|
||||
version='1.0.1', # 版本号
|
||||
license='MIT',
|
||||
|
||||
description='Douyin/TikTok crawler and no watermark video download.', # 描述
|
||||
long_description='''Douyin/TikTok crawler and no watermark video download.''',
|
||||
author_email='evil0ctal1985@gmail.com', # 你的邮箱**
|
||||
url='https://github.com/Evil0ctal/Douyin_TikTok_Download_API', # 可以写github上的地址,或者其他地址
|
||||
# 包内需要引用的文件夹
|
||||
# packages=setuptools.find_packages(exclude=['url2io',]),
|
||||
packages=["src/DT_scraper"],
|
||||
# keywords='NLP,tokenizing,Chinese word segementation',
|
||||
# package_dir={'jieba':'jieba'},
|
||||
# package_data={'jieba':['*.*','finalseg/*','analyse/*','posseg/*']},
|
||||
|
||||
# 依赖包
|
||||
install_requires=[
|
||||
'requests',
|
||||
"tenacity",
|
||||
],
|
||||
classifiers=[
|
||||
# 'Development Status :: 4 - Beta',
|
||||
# 'Operating System :: Microsoft' # 你的操作系统 OS Independent Microsoft
|
||||
'Intended Audience :: Developers',
|
||||
# 'License :: OSI Approved :: MIT License',
|
||||
# 'License :: OSI Approved :: BSD License', # BSD认证
|
||||
'Programming Language :: Python', # 支持的语言
|
||||
'Programming Language :: Python :: 3', # python版本 。。。
|
||||
'Programming Language :: Python :: 3.4',
|
||||
'Programming Language :: Python :: 3.5',
|
||||
'Programming Language :: Python :: 3.6',
|
||||
'Programming Language :: Python :: 3.7',
|
||||
'Programming Language :: Python :: 3.8',
|
||||
'Programming Language :: Python :: 3.9',
|
||||
'Programming Language :: Python :: 3.10',
|
||||
'Topic :: Software Development :: Libraries'
|
||||
],
|
||||
zip_safe=True,
|
||||
)
|
||||
@ -1,27 +0,0 @@
|
||||
Metadata-Version: 2.1
|
||||
Name: DT-Scraper
|
||||
Version: 1.0.0
|
||||
Summary: Douyin/TikTok crawler and no watermark video download.
|
||||
Home-page: https://github.com/Evil0ctal/Douyin_TikTok_Download_API
|
||||
Author: Evil0ctal
|
||||
Author-email: evil0ctal1985@gmail.com
|
||||
License: MIT
|
||||
Project-URL: Bug Tracker, https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues
|
||||
Platform: UNKNOWN
|
||||
Classifier: Intended Audience :: Developers
|
||||
Classifier: Programming Language :: Python
|
||||
Classifier: Programming Language :: Python :: 3
|
||||
Classifier: Programming Language :: Python :: 3.4
|
||||
Classifier: Programming Language :: Python :: 3.5
|
||||
Classifier: Programming Language :: Python :: 3.6
|
||||
Classifier: Programming Language :: Python :: 3.7
|
||||
Classifier: Programming Language :: Python :: 3.8
|
||||
Classifier: Programming Language :: Python :: 3.9
|
||||
Classifier: Programming Language :: Python :: 3.10
|
||||
Classifier: Topic :: Software Development :: Libraries
|
||||
Requires-Python: >=3.6
|
||||
Description-Content-Type: text/markdown
|
||||
License-File: LICENSE
|
||||
|
||||
Douyin/TikTok crawler and no watermark video download.
|
||||
|
||||
@ -1,13 +0,0 @@
|
||||
LICENSE
|
||||
README.md
|
||||
pyproject.toml
|
||||
setup.cfg
|
||||
setup.py
|
||||
src/DT_Scraper.egg-info/PKG-INFO
|
||||
src/DT_Scraper.egg-info/SOURCES.txt
|
||||
src/DT_Scraper.egg-info/dependency_links.txt
|
||||
src/DT_Scraper.egg-info/requires.txt
|
||||
src/DT_Scraper.egg-info/top_level.txt
|
||||
src/DT_Scraper.egg-info/zip-safe
|
||||
src/DT_scraper/__init__.py
|
||||
src/DT_scraper/scraper.py
|
||||
@ -1 +0,0 @@
|
||||
|
||||
@ -1,2 +0,0 @@
|
||||
requests
|
||||
tenacity
|
||||
@ -1 +0,0 @@
|
||||
DT_scraper
|
||||
@ -1 +0,0 @@
|
||||
|
||||
@ -1,2 +0,0 @@
|
||||
requests==2.28.0
|
||||
tenacity==8.0.1
|
||||
@ -1,552 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- encoding: utf-8 -*-
|
||||
# @Author: https://github.com/Evil0ctal/
|
||||
# @Time: 2021/11/06
|
||||
# @Update: 2022/09/04
|
||||
# @Function:
|
||||
# 核心代码,估值1块(๑•̀ㅂ•́)و✧
|
||||
# 用于爬取Douyin/TikTok数据并以字典形式返回。
|
||||
# input link, output dictionary.
|
||||
|
||||
|
||||
import re
|
||||
import json
|
||||
import requests
|
||||
from tenacity import *
|
||||
|
||||
|
||||
class Scraper:
|
||||
"""
|
||||
Scraper.douyin(link):
|
||||
输入参数为抖音视频/图集链接,完成解析后返回字典。
|
||||
|
||||
Scraper.tiktok(link):
|
||||
输入参数为TikTok视频/图集链接,完成解析后返回字典。
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.headers = {
|
||||
'user-agent': 'Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36 Edg/87.0.664.66'
|
||||
}
|
||||
self.tiktok_headers = {
|
||||
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
|
||||
"authority": "www.tiktok.com",
|
||||
"Accept-Encoding": "gzip, deflate",
|
||||
"Connection": "keep-alive",
|
||||
"Host": "www.tiktok.com",
|
||||
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) coc_coc_browser/86.0.170 Chrome/80.0.3987.170 Safari/537.36",
|
||||
}
|
||||
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
def douyin(self, original_url: str, proxies: dict = None):
|
||||
"""
|
||||
利用官方接口解析抖音链接信息
|
||||
:param proxies: pip install DT-Scraper, Default not use proxy.
|
||||
:param original_url: 抖音/TikTok链接(支持长/短链接) TikTok&Douyin URL
|
||||
:return:包含信息的字典 Dictionary data
|
||||
"""
|
||||
headers = self.headers
|
||||
try:
|
||||
# 开始时间
|
||||
start = time.time()
|
||||
# 判断是否为个人主页链接
|
||||
if 'user' in original_url:
|
||||
return {'status': 'failed', 'reason': '暂不支持个人主页批量解析', 'function': 'Scraper.douyin()',
|
||||
'value': original_url}
|
||||
else:
|
||||
# 原视频链接
|
||||
r = requests.get(url=original_url, headers=headers, allow_redirects=False, proxies=proxies)
|
||||
try:
|
||||
# 2021/12/11 发现抖音做了限制,会自动重定向网址,但是可以从回执头中获取
|
||||
long_url = r.headers['Location']
|
||||
# 判断是否为个人主页链接
|
||||
if 'user' in long_url:
|
||||
return {'status': 'failed', 'reason': '暂不支持个人主页批量解析',
|
||||
'function': 'Scraper.douyin()',
|
||||
'value': original_url}
|
||||
except:
|
||||
# 报错后判断为长链接,直接截取视频id
|
||||
long_url = original_url
|
||||
# 正则匹配出视频ID
|
||||
try:
|
||||
# 第一种链接类型
|
||||
# https://www.douyin.com/video/7086770907674348841
|
||||
key = re.findall('/video/(\d+)?', long_url)[0]
|
||||
print('视频ID为: {}'.format(key))
|
||||
except Exception:
|
||||
# 第二种链接类型
|
||||
# https://www.douyin.com/discover?modal_id=7086770907674348841
|
||||
key = re.findall('modal_id=(\d+)', long_url)[0]
|
||||
print('视频ID为: {}'.format(key))
|
||||
# 构造抖音API链接
|
||||
api_url = f'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={key}'
|
||||
print("正在请求抖音API链接: " + '\n' + api_url)
|
||||
# 将回执以JSON格式处理
|
||||
js = json.loads(requests.get(url=api_url, headers=headers, proxies=proxies).text)
|
||||
aweme_id = str(js['item_list'][0]['aweme_id'])
|
||||
share_url = re.sub("/\\?.*", "", js['item_list'][0]['share_url'])
|
||||
if share_url is None:
|
||||
share_url = (
|
||||
"https://www.iesdouyin.com/share/video/" + aweme_id) if aweme_id is not None else original_url;
|
||||
try:
|
||||
music_share_url = "https://www.iesdouyin.com/share/music/" + str(js['item_list'][0]['music']['mid'])
|
||||
except:
|
||||
music_share_url = None
|
||||
# 判断是否为图集
|
||||
if js['item_list'][0]['images'] is not None:
|
||||
print("类型 = 图集")
|
||||
# 类型为图集
|
||||
url_type = 'album'
|
||||
# 图集标题
|
||||
album_title = str(js['item_list'][0]['desc'])
|
||||
# 图集作者昵称
|
||||
album_author = str(js['item_list'][0]['author']['nickname'])
|
||||
# 图集作者签名
|
||||
album_author_signature = str(js['item_list'][0]['author']['signature'])
|
||||
# 图集作者UID
|
||||
album_author_uid = str(js['item_list'][0]['author']['uid'])
|
||||
# 图集作者抖音号
|
||||
album_author_id = str(js['item_list'][0]['author']['unique_id'])
|
||||
if album_author_id == "":
|
||||
# 如果作者未修改过抖音号,应使用此值以避免无法获取其抖音ID
|
||||
album_author_id = str(js['item_list'][0]['author']['short_id'])
|
||||
# 尝试获取图集BGM信息
|
||||
for key in js['item_list'][0]:
|
||||
if key == 'music':
|
||||
# 图集BGM链接
|
||||
album_music = str(js['item_list'][0]['music']['play_url']['url_list'][0] if len(
|
||||
js['item_list'][0]['music']['play_url']['url_list']) > 0 else 'No BGM found')
|
||||
# 图集BGM标题
|
||||
album_music_title = str(js['item_list'][0]['music']['title'])
|
||||
# 图集BGM作者
|
||||
album_music_author = str(js['item_list'][0]['music']['author'])
|
||||
# 图集BGM ID
|
||||
album_music_id = str(js['item_list'][0]['music']['id'])
|
||||
# 图集BGM MID
|
||||
album_music_mid = str(js['item_list'][0]['music']['mid'])
|
||||
break;
|
||||
else:
|
||||
# 图集BGM链接
|
||||
album_music = album_music_title = album_music_author = album_music_id = album_music_mid = 'No BGM found '
|
||||
# 图集ID
|
||||
album_aweme_id = str(js['item_list'][0]['statistics']['aweme_id'])
|
||||
# 评论数量
|
||||
album_comment_count = str(js['item_list'][0]['statistics']['comment_count'])
|
||||
# 获赞数量
|
||||
album_digg_count = str(js['item_list'][0]['statistics']['digg_count'])
|
||||
# 播放次数
|
||||
album_play_count = str(js['item_list'][0]['statistics']['play_count'])
|
||||
# 分享次数
|
||||
album_share_count = str(js['item_list'][0]['statistics']['share_count'])
|
||||
# 上传时间戳
|
||||
album_create_time = str(js['item_list'][0]['create_time'])
|
||||
# 将话题保存在列表中
|
||||
album_hashtags = []
|
||||
for tag in js['item_list'][0]['text_extra']:
|
||||
album_hashtags.append(tag['hashtag_name'])
|
||||
# 将无水印图片链接保存在列表中
|
||||
images_list = []
|
||||
for data in js['item_list'][0]['images']:
|
||||
images_list.append(data['url_list'][0])
|
||||
# 结束时间
|
||||
end = time.time()
|
||||
# 解析时间
|
||||
analyze_time = format((end - start), '.4f')
|
||||
# 将信息储存在字典中
|
||||
album_data = {'status': 'success',
|
||||
'analyze_time': (analyze_time + 's'),
|
||||
'url_type': url_type,
|
||||
'platform': 'douyin',
|
||||
'original_url': original_url,
|
||||
'share_url': share_url,
|
||||
'music_share_url': music_share_url,
|
||||
'api_url': api_url,
|
||||
'album_aweme_id': album_aweme_id,
|
||||
'album_title': album_title,
|
||||
'album_author': album_author,
|
||||
'album_author_signature': album_author_signature,
|
||||
'album_author_uid': album_author_uid,
|
||||
'album_author_id': album_author_id,
|
||||
'album_music': album_music,
|
||||
'album_music_title': album_music_title,
|
||||
'album_music_author': album_music_author,
|
||||
'album_music_id': album_music_id,
|
||||
'album_music_mid': album_music_mid,
|
||||
'album_comment_count': album_comment_count,
|
||||
'album_digg_count': album_digg_count,
|
||||
'album_play_count': album_play_count,
|
||||
'album_share_count': album_share_count,
|
||||
'album_create_time': album_create_time,
|
||||
'album_list': images_list,
|
||||
'album_hashtags': album_hashtags}
|
||||
return album_data
|
||||
else:
|
||||
print("类型 = 视频")
|
||||
# 类型为视频
|
||||
url_type = 'video'
|
||||
# 视频标题
|
||||
video_title = str(js['item_list'][0]['desc'])
|
||||
# 视频作者昵称
|
||||
video_author = str(js['item_list'][0]['author']['nickname'])
|
||||
# 视频作者抖音号
|
||||
video_author_id = str(js['item_list'][0]['author']['unique_id'])
|
||||
if video_author_id == "":
|
||||
# 如果作者未修改过抖音号,应使用此值以避免无法获取其抖音ID
|
||||
video_author_id = str(js['item_list'][0]['author']['short_id'])
|
||||
# vid
|
||||
vid = str(js['item_list'][0]['video']['vid'])
|
||||
# 无水印1080p视频链接
|
||||
try:
|
||||
r = requests.get(
|
||||
"https://aweme.snssdk.com/aweme/v1/play/?video_id={}&radio=1080p&line=0".format(vid),
|
||||
headers=headers, allow_redirects=False, proxies=proxies)
|
||||
nwm_video_url_1080p = r.headers['Location']
|
||||
except:
|
||||
nwm_video_url_1080p = "None"
|
||||
# 有水印视频链接
|
||||
wm_video_url = str(js['item_list'][0]['video']['play_addr']['url_list'][0])
|
||||
# 无水印视频链接 (在回执JSON中将关键字'playwm'替换为'play'即可获得无水印地址)
|
||||
nwm_video_url = str(js['item_list'][0]['video']['play_addr']['url_list'][0]).replace('playwm',
|
||||
'play')
|
||||
# 去水印后视频链接(2022年1月1日抖音APi获取到的URL会进行跳转,需要在Location中获取直链)
|
||||
r = requests.get(url=nwm_video_url, headers=headers, allow_redirects=False, proxies=proxies)
|
||||
video_url = r.headers['Location']
|
||||
# 视频作者签名
|
||||
video_author_signature = str(js['item_list'][0]['author']['signature'])
|
||||
# 视频作者UID
|
||||
video_author_uid = str(js['item_list'][0]['author']['uid'])
|
||||
# 尝试获取视频背景音乐
|
||||
for key in js['item_list'][0]:
|
||||
if key == 'music':
|
||||
if len(js['item_list'][0]['music']['play_url']['url_list']) != 0:
|
||||
# 视频BGM链接
|
||||
video_music = str(js['item_list'][0]['music']['play_url']['url_list'][0])
|
||||
else:
|
||||
video_music = 'No BGM found'
|
||||
# 视频BGM标题
|
||||
video_music_title = str(js['item_list'][0]['music']['title'])
|
||||
# 视频BGM作者
|
||||
video_music_author = str(js['item_list'][0]['music']['author'])
|
||||
# 视频BGM ID
|
||||
video_music_id = str(js['item_list'][0]['music']['id'])
|
||||
# 视频BGM MID
|
||||
video_music_mid = str(js['item_list'][0]['music']['mid'])
|
||||
break;
|
||||
else:
|
||||
video_music = video_music_title = video_music_author = video_music_id = video_music_mid = 'No BGM found'
|
||||
# 视频ID
|
||||
video_aweme_id = str(js['item_list'][0]['statistics']['aweme_id'])
|
||||
# 评论数量
|
||||
video_comment_count = str(js['item_list'][0]['statistics']['comment_count'])
|
||||
# 获赞数量
|
||||
video_digg_count = str(js['item_list'][0]['statistics']['digg_count'])
|
||||
# 播放次数
|
||||
video_play_count = str(js['item_list'][0]['statistics']['play_count'])
|
||||
# 分享次数
|
||||
video_share_count = str(js['item_list'][0]['statistics']['share_count'])
|
||||
# 上传时间戳
|
||||
video_create_time = str(js['item_list'][0]['create_time'])
|
||||
# 视频封面
|
||||
video_cover = js['item_list'][0]['video']['cover']['url_list'][0]
|
||||
# 视频动态封面
|
||||
video_dynamic_cover = js['item_list'][0]['video']['dynamic_cover']['url_list'][0]
|
||||
# 视频原始封面
|
||||
video_origin_cover = js['item_list'][0]['video']['origin_cover']['url_list'][0]
|
||||
# 将话题保存在列表中
|
||||
video_hashtags = []
|
||||
for tag in js['item_list'][0]['text_extra']:
|
||||
video_hashtags.append(tag['hashtag_name'])
|
||||
# 结束时间
|
||||
end = time.time()
|
||||
# 解析时间
|
||||
analyze_time = format((end - start), '.4f')
|
||||
# 返回包含数据的字典
|
||||
video_data = {'status': 'success',
|
||||
'analyze_time': (analyze_time + 's'),
|
||||
'url_type': url_type,
|
||||
'platform': 'douyin',
|
||||
'original_url': original_url,
|
||||
'share_url': share_url,
|
||||
'music_share_url': music_share_url,
|
||||
'api_url': api_url,
|
||||
'video_title': video_title,
|
||||
'nwm_video_url': video_url,
|
||||
'nwm_video_url_1080p': nwm_video_url_1080p,
|
||||
'wm_video_url': wm_video_url,
|
||||
'video_aweme_id': video_aweme_id,
|
||||
'video_author': video_author,
|
||||
'video_author_signature': video_author_signature,
|
||||
'video_author_uid': video_author_uid,
|
||||
'video_author_id': video_author_id,
|
||||
'video_music': video_music,
|
||||
'video_music_title': video_music_title,
|
||||
'video_music_author': video_music_author,
|
||||
'video_music_id': video_music_id,
|
||||
'video_music_mid': video_music_mid,
|
||||
'video_comment_count': video_comment_count,
|
||||
'video_digg_count': video_digg_count,
|
||||
'video_play_count': video_play_count,
|
||||
'video_share_count': video_share_count,
|
||||
'video_create_time': video_create_time,
|
||||
'video_cover': video_cover,
|
||||
'video_dynamic_cover': video_dynamic_cover,
|
||||
'video_origin_cover': video_origin_cover,
|
||||
'video_hashtags': video_hashtags}
|
||||
return video_data
|
||||
except Exception as e:
|
||||
# 返回异常
|
||||
return {'status': 'failed', 'reason': e, 'function': 'Scraper.douyin()', 'value': original_url}
|
||||
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
def tiktok(self, original_url: str, proxies: dict = None):
|
||||
"""
|
||||
解析TikTok链接
|
||||
:param proxies: {'all': 127.0.0.1:2333}, Default not use proxy.
|
||||
:param original_url:TikTok链接
|
||||
:return:包含信息的字典
|
||||
"""
|
||||
|
||||
headers = self.headers
|
||||
# 开始时间
|
||||
start = time.time()
|
||||
# 校验TikTok链接
|
||||
if '@' in original_url:
|
||||
print("目标链接: ", original_url)
|
||||
else:
|
||||
# 从请求头中获取原始链接
|
||||
response = requests.get(url=original_url, headers=headers, allow_redirects=False, proxies=proxies)
|
||||
true_link = response.headers['Location'].split("?")[0]
|
||||
original_url = true_link
|
||||
# TikTok请求头返回的第二种链接类型
|
||||
if '.html' in true_link:
|
||||
response = requests.get(url=true_link, headers=headers, allow_redirects=False, proxies=proxies)
|
||||
original_url = response.headers['Location'].split("?")[0]
|
||||
print("目标链接: ", original_url)
|
||||
try:
|
||||
# 获取视频ID
|
||||
video_id = re.findall('/video/(\d+)?', original_url)[0]
|
||||
print('获取到的TikTok视频ID是{}'.format(video_id))
|
||||
# 尝试从TikTok网页获取部分视频数据
|
||||
try:
|
||||
tiktok_headers = self.tiktok_headers
|
||||
html = requests.get(url=original_url, headers=tiktok_headers, proxies=proxies, timeout=1)
|
||||
# 正则检索网页中存在的JSON信息
|
||||
resp = re.search('"ItemModule":{(.*)},"UserModule":', html.text).group(1)
|
||||
resp_info = ('{"ItemModule":{' + resp + '}}')
|
||||
result = json.loads(resp_info)
|
||||
# 从网页中获得的视频JSON数据
|
||||
video_info = result["ItemModule"][video_id]
|
||||
except:
|
||||
video_info = None
|
||||
# 从TikTok官方API获取部分视频数据
|
||||
tiktok_api_link = 'https://api.tiktokv.com/aweme/v1/aweme/detail/?aweme_id={}'.format(
|
||||
video_id)
|
||||
print('正在请求API链接:{}'.format(tiktok_api_link))
|
||||
response = requests.get(url=tiktok_api_link, headers=headers, proxies=proxies).text
|
||||
# 将API获取到的内容格式化为JSON
|
||||
result = json.loads(response)
|
||||
if 'image_post_info' in response:
|
||||
# 判断链接是图集链接
|
||||
url_type = 'album'
|
||||
print('类型为图集/type album')
|
||||
# 视频标题
|
||||
album_title = result["aweme_detail"]["desc"]
|
||||
# 视频作者昵称
|
||||
album_author_nickname = result["aweme_detail"]['author']["nickname"]
|
||||
# 视频作者ID
|
||||
album_author_id = result["aweme_detail"]['author']["unique_id"]
|
||||
# 上传时间戳
|
||||
album_create_time = result["aweme_detail"]['create_time']
|
||||
# 视频ID
|
||||
album_aweme_id = result["aweme_detail"]['statistics']['aweme_id']
|
||||
try:
|
||||
# 视频BGM标题
|
||||
album_music_title = result["aweme_detail"]['music']['title']
|
||||
# 视频BGM作者
|
||||
album_music_author = result["aweme_detail"]['music']['author']
|
||||
# 视频BGM ID
|
||||
album_music_id = result["aweme_detail"]['music']['id']
|
||||
# 视频BGM链接
|
||||
album_music_url = result["aweme_detail"]['music']['play_url']['url_list'][0]
|
||||
except:
|
||||
album_music_title, album_music_author, album_music_id, album_music_url = "None", "None", "None", "None"
|
||||
# 评论数量
|
||||
album_comment_count = result["aweme_detail"]['statistics']['comment_count']
|
||||
# 获赞数量
|
||||
album_digg_count = result["aweme_detail"]['statistics']['digg_count']
|
||||
# 播放次数
|
||||
album_play_count = result["aweme_detail"]['statistics']['play_count']
|
||||
# 下载次数
|
||||
album_download_count = result["aweme_detail"]['statistics']['download_count']
|
||||
# 分享次数
|
||||
album_share_count = result["aweme_detail"]['statistics']['share_count']
|
||||
# 无水印图集
|
||||
album_list = []
|
||||
for i in result["aweme_detail"]['image_post_info']['images']:
|
||||
album_list.append(i['display_image']['url_list'][0])
|
||||
# 结束时间
|
||||
end = time.time()
|
||||
# 解析时间
|
||||
analyze_time = format((end - start), '.4f')
|
||||
# 储存数据
|
||||
album_data = {'status': 'success',
|
||||
'analyze_time': (analyze_time + 's'),
|
||||
'url_type': url_type,
|
||||
'api_url': tiktok_api_link,
|
||||
'original_url': original_url,
|
||||
'platform': 'tiktok',
|
||||
'album_title': album_title,
|
||||
'album_list': album_list,
|
||||
'album_author_nickname': album_author_nickname,
|
||||
'album_author_id': album_author_id,
|
||||
'album_create_time': album_create_time,
|
||||
'album_aweme_id': album_aweme_id,
|
||||
'album_music_title': album_music_title,
|
||||
'album_music_author': album_music_author,
|
||||
'album_music_id': album_music_id,
|
||||
'album_music_url': album_music_url,
|
||||
'album_comment_count': album_comment_count,
|
||||
'album_digg_count': album_digg_count,
|
||||
'album_play_count': album_play_count,
|
||||
'album_share_count': album_share_count,
|
||||
'album_download_count': album_download_count
|
||||
}
|
||||
# 返回包含数据的字典
|
||||
return album_data
|
||||
else:
|
||||
# 类型为视频
|
||||
url_type = 'video'
|
||||
print('类型为视频/type video')
|
||||
# 无水印视频链接
|
||||
nwm_video_url = result["aweme_detail"]["video"]["play_addr"]["url_list"][0]
|
||||
try:
|
||||
# 有水印视频链接
|
||||
wm_video_url = result["aweme_detail"]["video"]['download_addr']['url_list'][0]
|
||||
except Exception:
|
||||
# 有水印视频链接
|
||||
wm_video_url = 'None'
|
||||
# 视频标题
|
||||
video_title = result["aweme_detail"]["desc"]
|
||||
# 视频作者昵称
|
||||
video_author_nickname = result["aweme_detail"]['author']["nickname"]
|
||||
# 视频作者ID
|
||||
video_author_id = result["aweme_detail"]['author']["unique_id"]
|
||||
# 上传时间戳
|
||||
video_create_time = result["aweme_detail"]['create_time']
|
||||
# 视频ID
|
||||
video_aweme_id = result["aweme_detail"]['statistics']['aweme_id']
|
||||
try:
|
||||
# 视频BGM标题
|
||||
video_music_title = result["aweme_detail"]['music']['title']
|
||||
# 视频BGM作者
|
||||
video_music_author = result["aweme_detail"]['music']['author']
|
||||
# 视频BGM ID
|
||||
video_music_id = result["aweme_detail"]['music']['id']
|
||||
# 视频BGM链接
|
||||
video_music_url = result["aweme_detail"]['music']['play_url']['url_list'][0]
|
||||
except:
|
||||
video_music_title, video_music_author, video_music_id, video_music_url = "None", "None", "None", "None"
|
||||
# 评论数量
|
||||
video_comment_count = result["aweme_detail"]['statistics']['comment_count']
|
||||
# 获赞数量
|
||||
video_digg_count = result["aweme_detail"]['statistics']['digg_count']
|
||||
# 播放次数
|
||||
video_play_count = result["aweme_detail"]['statistics']['play_count']
|
||||
# 下载次数
|
||||
video_download_count = result["aweme_detail"]['statistics']['download_count']
|
||||
# 分享次数
|
||||
video_share_count = result["aweme_detail"]['statistics']['share_count']
|
||||
# 视频封面
|
||||
video_cover = result["aweme_detail"]['video']['cover']['url_list'][0]
|
||||
# 视频动态封面
|
||||
video_dynamic_cover = result["aweme_detail"]['video']['dynamic_cover']['url_list'][0]
|
||||
# 视频原始封面
|
||||
video_origin_cover = result["aweme_detail"]['video']['origin_cover']['url_list'][0]
|
||||
# 将话题保存在列表中
|
||||
video_hashtags = []
|
||||
for tag in result["aweme_detail"]['text_extra']:
|
||||
if 'hashtag_name' in tag:
|
||||
video_hashtags.append(tag['hashtag_name'])
|
||||
else:
|
||||
continue
|
||||
if video_info != None:
|
||||
# 作者粉丝数量
|
||||
video_author_followerCount = video_info['authorStats']['followerCount']
|
||||
# 作者关注数量
|
||||
video_author_followingCount = video_info['authorStats']['followingCount']
|
||||
# 作者获赞数量
|
||||
video_author_heartCount = video_info['authorStats']['heartCount']
|
||||
# 作者视频数量
|
||||
video_author_videoCount = video_info['authorStats']['videoCount']
|
||||
# 作者已赞作品数量
|
||||
video_author_diggCount = video_info['authorStats']['diggCount']
|
||||
else:
|
||||
# 作者粉丝数量
|
||||
video_author_followerCount = 'None'
|
||||
# 作者关注数量
|
||||
video_author_followingCount = 'None'
|
||||
# 作者获赞数量
|
||||
video_author_heartCount = 'None'
|
||||
# 作者视频数量
|
||||
video_author_videoCount = 'None'
|
||||
# 作者已赞作品数量
|
||||
video_author_diggCount = 'None'
|
||||
# 结束时间
|
||||
end = time.time()
|
||||
# 解析时间
|
||||
analyze_time = format((end - start), '.4f')
|
||||
# 储存数据
|
||||
video_data = {'status': 'success',
|
||||
'analyze_time': (analyze_time + 's'),
|
||||
'url_type': url_type,
|
||||
'api_url': tiktok_api_link,
|
||||
'original_url': original_url,
|
||||
'platform': 'tiktok',
|
||||
'video_title': video_title,
|
||||
'nwm_video_url': nwm_video_url,
|
||||
'wm_video_url': wm_video_url,
|
||||
'video_author_nickname': video_author_nickname,
|
||||
'video_author_id': video_author_id,
|
||||
'video_create_time': video_create_time,
|
||||
'video_aweme_id': video_aweme_id,
|
||||
'video_music_title': video_music_title,
|
||||
'video_music_author': video_music_author,
|
||||
'video_music_id': video_music_id,
|
||||
'video_music_url': video_music_url,
|
||||
'video_comment_count': video_comment_count,
|
||||
'video_digg_count': video_digg_count,
|
||||
'video_play_count': video_play_count,
|
||||
'video_share_count': video_share_count,
|
||||
'video_download_count': video_download_count,
|
||||
'video_author_followerCount': video_author_followerCount,
|
||||
'video_author_followingCount': video_author_followingCount,
|
||||
'video_author_heartCount': video_author_heartCount,
|
||||
'video_author_videoCount': video_author_videoCount,
|
||||
'video_author_diggCount': video_author_diggCount,
|
||||
'video_cover': video_cover,
|
||||
'video_dynamic_cover': video_dynamic_cover,
|
||||
'video_origin_cover': video_origin_cover,
|
||||
'video_hashtags': video_hashtags
|
||||
}
|
||||
# 返回包含数据的字典
|
||||
return video_data
|
||||
except Exception as e:
|
||||
# 异常捕获
|
||||
return {'status': 'failed', 'reason': e, 'function': 'Scraper.tiktok()', 'value': original_url}
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
# 测试类
|
||||
scraper = Scraper()
|
||||
while True:
|
||||
url = re.findall('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+',
|
||||
input("Enter your Douyin/TikTok url here to test: "))[0]
|
||||
try:
|
||||
if 'douyin.com' in url:
|
||||
douyin_date = scraper.douyin(url)
|
||||
print(douyin_date)
|
||||
else:
|
||||
tiktok_date = scraper.tiktok(url)
|
||||
print(tiktok_date)
|
||||
except Exception as e:
|
||||
print("Error: " + str(e))
|
||||
Loading…
x
Reference in New Issue
Block a user