diff --git a/PyPi/LICENSE b/PyPi/LICENSE
deleted file mode 100644
index fd91e63..0000000
--- a/PyPi/LICENSE
+++ /dev/null
@@ -1,21 +0,0 @@
-MIT License
-
-Copyright (c) 2021 Evil0ctal
-
-Permission is hereby granted, free of charge, to any person obtaining a copy
-of this software and associated documentation files (the "Software"), to deal
-in the Software without restriction, including without limitation the rights
-to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-copies of the Software, and to permit persons to whom the Software is
-furnished to do so, subject to the following conditions:
-
-The above copyright notice and this permission notice shall be included in all
-copies or substantial portions of the Software.
-
-THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-SOFTWARE.
diff --git a/PyPi/README.md b/PyPi/README.md
deleted file mode 100644
index dca615b..0000000
--- a/PyPi/README.md
+++ /dev/null
@@ -1,502 +0,0 @@
-
-
-  -
-
- Douyin_TikTok_Download_API(抖音/TikTok无水印解析API)
-
-
-
-
- 运行说明 •
- API使用 •
- 手动部署 •
- Docker部署 •
- Docker镜像 •
- 贡献者
-
-
-
-
-
-[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/blob/main/LICENSE)
-[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/issues)
-[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/network)
-[](https://github.com/Evil0ctal/TikTokDownloader_PyWebIO/stargazers)
-[](https://hub.docker.com/repository/docker/evil0ctal/douyin_tiktok_download_api)
-
-Language: [[English](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.en.md)] [[简体中文](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.md)] [[繁体中文](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.zh-TW.md)]
-
-> Note: This API is applicable to Douyin and TikTok. Douyin is TikTok in China. You can distribute or modify the code at
-> will, but please mark the original author.
-
-## 👻介绍
-
-> 出于稳定性的考虑,暂时关闭演示站的/video(返回mp4文件)和/music(返回mp3文件)
-> 这两个功能,同时结果页面的批量下载功能也暂时不可用,如有需求请自行部署,其他功能在演示站上仍正常使用,API服务器保证99%的时间正常运行,但不保证解析100%成功,如果解析失败请等一两分钟后重试。
-
-🚀演示地址:[https://douyin.wtf/](https://douyin.wtf/)
-
-🛰API演示:[https://api.douyin.wtf/](https://api.douyin.wtf/)
-
-💾iOS快捷指令(中文): [点击获取](https://www.icloud.com/shortcuts/331073aca78345cf9ab4f73b6a457f97) (
-更新于2022/07/18,快捷指令可自动检查更新,安装一次即可。)
-
-🌎iOS Shortcut(English): [Click to get](https://www.icloud.com/shortcuts/83548306bc0c4f8ea563108f79c73f8d) (Updated on
-2022/07/18, this shortcut will automatically check for updates, only need to install it once.)
-
-🗂快捷指令历史版本: [Shortcuts release](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/53)
-
-📦️Tiktok/抖音下载器(桌面应用):[TikDown](https://github.com/Tairraos/TikDown/)
-
-本项目使用 [PyWebIO](https://github.com/pywebio/PyWebIO)、[Flask](https://github.com/pallets/flask)
-,利用Python实现在线批量解析抖音的无水印视频/图集。
-
-可用于下载作者禁止下载的视频,或者进行数据爬取等等,同时可搭配[iOS自带的快捷指令APP](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)
-配合本项目API实现应用内下载。
-
-快捷指令需要在抖音或TikTok的APP内,选择你想要保存的视频,点击分享按钮,然后找到 "抖音TikTok无水印下载"
-这个选项,如遇到通知询问是否允许快捷指令访问xxxx (域名或服务器),需要点击允许才可以正常使用,下载成功的视频或图集会保存在一个专门的相册中以方便浏览。
-
-## 💡项目文件结构
-
-```
-# 请根据需要自行修改config.ini中的内容
-.
-└── Douyin_TikTok_Download_API/
- ├── /static(静态前端资源)
- ├── web_zh.py(网页入口)
- ├── web_api.py(API)
- ├── scraper.py(解析库)
- ├── config.ini(所有项目的配置文件,包含端口及代理等,如需请自行修改该文件。)
- ├── logs.txt(错误日志,自动生成。)
- └── API_logs.txt(API调用日志,自动生成。)
-```
-
-## 💯已支持功能:
-
-- 支持抖音视频/图集解析
-- 支持海外TikTok视频解析
-- 支持批量解析(支持抖音/TikTok混合解析)
-- 解析结果页批量下载无水印视频
-- 制作[pip包](https://pypi.org/project/DT-Scraper/)方便使用
-- 支持API调用
-- 支持使用代理解析
-- 支持[iOS快捷指令](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)实现应用内下载无水印视频/图集
-
----
-
-## 🤦后续功能:
-
-- [ ] 支持输入(抖音/TikTok)作者主页链接实现批量解析
-
----
-
-## 🧭运行说明(经过测试过的Python版本为3.8):
-> 🚨如果你要部署本项目,请参考部署方式([Docker部署](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker "Docker部署"), [手动部署](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-%E6%89%8B%E5%8A%A8%E9%83%A8%E7%BD%B2 "手动部署"))
-
-- 克隆本仓库:
-
-```console
-git clone https://github.com/Evil0ctal/Douyin_TikTok_Download_API.git
-```
-
-- 移动至仓库目录:
-
-```console
-cd Douyin_TikTok_Download_API
-```
-
-- 安装依赖库:
-
-```console
-pip install -r requirements.txt
-```
-
-- 修改config.ini(可选):
-
-```console
-vim config.ini
-```
-
-- 网页解析
-
-```console
-# 运行web_zh.py
-python3 web_zh.py
-```
-
-- API
-
-```console
-# 运行web_api.py
-python3 web_api.py
-```
-
-- 调用解析库
-
-```python
-# pip install DT-Scraper
-from DT_scraper.scraper import Scraper
-
-api = Scraper()
-
-# 解析Douyin视频/图集
-douyin_data = api.douyin(input('抖音视频链接:'))
-# 返回字典
-print(douyin_data)
-
-# Parsing TikTok Videos/Galleries
-tiktok_data = api.tiktok(input('TikTok video URL:'))
-# return dictionary
-print(tiktok_data)
-
-# 使用代理进行解析(Parse using a proxy)
-api.tiktok(input('TikTok video URL:'), proxies = {"all": "127.0.0.1:2333"})
-
-```
-
-- 入口(端口可在config.ini文件中修改)
-
-```text
-网页入口:
-http://localhost(服务器IP):5000/
-API入口:
-http://localhost(服务器IP):2333/
-```
-
-## 🗺️支持的提交格式(包含但不仅限于以下例子):
-
-- 抖音分享口令 (APP内复制)
-
-```text
-例子:7.43 pda:/ 让你在几秒钟之内记住我 https://v.douyin.com/L5pbfdP/ 复制此链接,打开Dou音搜索,直接观看视频!
-```
-
-- 抖音短网址 (APP内复制)
-
-```text
-例子:https://v.douyin.com/L4FJNR3/
-```
-
-- 抖音正常网址 (网页版复制)
-
-```text
-例子:
-https://www.douyin.com/video/6914948781100338440
-```
-
-- 抖音发现页网址 (APP复制)
-
-```text
-例子:
-https://www.douyin.com/discover?modal_id=7069543727328398622
-```
-
-- TikTok短网址 (APP内复制)
-
-```text
-例子:
-https://vm.tiktok.com/TTPdkQvKjP/
-```
-
-- TikTok正常网址 (网页版复制)
-
-```text
-例子:
-https://www.tiktok.com/@tvamii/video/7045537727743380782
-```
-
-- 抖音/TikTok批量网址(无需使用符合隔开)
-
-```text
-例子:
-2.84 nqe:/ 骑白马的也可以是公主%%百万转场变身 https://v.douyin.com/L4FJNR3/ 复制此链接,打开Dou音搜索,直接观看视频!
-8.94 mDu:/ 让你在几秒钟之内记住我 https://v.douyin.com/L4NpDJ6/ 复制此链接,打开Dou音搜索,直接观看视频!
-9.94 LWz:/ ok我坦白交代 %%knowknow https://v.douyin.com/L4NEvNn/ 复制此链接,打开Dou音搜索,直接观看视频!
-https://www.tiktok.com/@gamer/video/7054061777033628934
-https://www.tiktok.com/@off.anime_rei/video/7059609659690339586
-https://www.tiktok.com/@tvamii/video/7045537727743380782
-```
-
-## 🛰️API使用
-
-API可将请求参数转换为需要提取的无水印视频/图片直链,配合IOS捷径可实现应用内下载。
-
-- 解析请求参数
-
-```text
-http://localhost(服务器IP):2333/api?url="复制的(抖音/TikTok)口令/链接"
-```
-
-- 返回参数
-
-> 抖音视频
-
-```json
-{
- "analyze_time": "1.9043s",
- "api_url": "https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6918273131559881997",
- "nwm_video_url": "http://v3-dy-o.zjcdn.com/23f0dec312ede563bef881af9a88bdc7/624dd965/video/tos/cn/tos-cn-ve-15/eccedcf4386948f5b5a1f0bcfb3dcde9/?a=1128&br=2537&bt=2537&cd=0%7C0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=sYGC~3E7nz7Th1PZSDXq&l=202204070118030102080650132A21E31F&lr=&mime_type=video_mp4&net=0&pl=0&qs=0&rc=M3hleDRsODlkMzMzaGkzM0ApODpmNWc4ODs5N2lmNzg5aWcpaGRqbGRoaGRmLi4ybnBrbjYuYC0tYy0wc3MtYmJjNTM2NjAtNDFjMzJgOmNwb2wrbStqdDo%3D&vl=&vr=",
- "original_url": "https://v.douyin.com/L4FJNR3/",
- "platform": "douyin",
- "status": "success",
- "url_type": "video",
- "video_author": "Real机智张",
- "video_author_id": "Rea1yaoyue",
- "video_author_signature": "",
- "video_author_uid": "59840491348",
- "video_aweme_id": "6918273131559881997",
- "video_comment_count": "89145",
- "video_create_time": "1610786002",
- "video_digg_count": "2968195",
- "video_hashtags": [
- "百万转场变身"
- ],
- "video_music": "https://sf3-cdn-tos.douyinstatic.com/obj/ies-music/6910889805266504461.mp3",
- "video_music_author": "梅尼耶",
- "video_music_id": "6910889820861451000",
- "video_music_mid": "6910889820861451021",
- "video_music_title": "@梅尼耶创作的原声",
- "video_play_count": "0",
- "video_share_count": "74857",
- "video_title": "骑白马的也可以是公主#百万转场变身",
- "wm_video_url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300ffe0000c01a96q5nis1qu5b1u10&ratio=720p&line=0"
-}
-```
-
-> 抖音图集
-
-```json
-{
- "album_author": "治愈图集",
- "album_author_id": "ZYTJ2002",
- "album_author_signature": "取无水印图",
- "album_author_uid": "449018054867063",
- "album_aweme_id": "7015137063141920030",
- "album_comment_count": "5436",
- "album_create_time": "1633338878",
- "album_digg_count": "193734",
- "album_hashtags": [
- "晚霞",
- "治愈系",
- "落日余晖",
- "日落🌄"
- ],
- "album_list": [
- "https://p26-sign.douyinpic.com/tos-cn-i-0813/5223757a7bef4f8480cd25d0fa2d2d94~noop.webp?x-expires=1651856400&x-signature=K1VjJdWTHCAaYSz14y6NumjjtfI%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47",
- "https://p26-sign.douyinpic.com/tos-cn-i-0813/d99467672da840908acccf2d2b4b7ef7~noop.webp?x-expires=1651856400&x-signature=ncBb8Tt7z4PmpUyiCNr%2FJYnwRSA%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47",
- "https://p26-sign.douyinpic.com/tos-cn-i-0813/5c2562210b1a4d4c99d6d4dbd2f23f2b~noop.webp?x-expires=1651856400&x-signature=Rsmplb53IKfvKd3mmIb4iQNhlIE%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47",
- "https://p26-sign.douyinpic.com/tos-cn-i-0813/9bb74c0c6aff4217bd1491a077b2c817~noop.webp?x-expires=1651856400&x-signature=BLRyHoKP0ybIci57yneOca62dxI%3D&from=4257465056&s=PackSourceEnum_DOUYIN_REFLOW&se=false&biz_tag=aweme_images&l=202204070120460102101050412A210A47"
- ],
- "album_music": "https://sf6-cdn-tos.douyinstatic.com/obj/ies-music/6978805801733442341.mp3",
- "album_music_author": "魏同学",
- "album_music_id": "6978805810365271000",
- "album_music_mid": "6978805810365270791",
- "album_music_title": "@魏同学创作的原声",
- "album_play_count": "0",
- "album_share_count": "30717",
- "album_title": "“山海自有归期 风雨自有相逢 意难平终将和解 万事终将如意”#晚霞 #治愈系 #落日余晖 #日落🌄",
- "analyze_time": "1.0726s",
- "api_url": "https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=7015137063141920030",
- "original_url": "https://v.douyin.com/Nb8jysN/",
- "platform": "douyin",
- "status": "success",
- "url_type": "album"
-}
-```
-
-> TikTok视频
-
-```JSON
-{
- "analyze_time": "5.0863s",
- "nwm_video_url": "https://v19.tiktokcdn-us.com/cfa357dadd8f913f013a6d0b0dca293f/624e20fa/video/tos/useast5/tos-useast5-ve-0068c003-tx/3296231486014755a1b81aa70c349a53/?a=1233&br=6498&bt=3249&cd=0%7C0%7C0%7C3&ch=0&cr=3&cs=0&cv=1&dr=0&ds=6&er=&ft=bY1KJnB4TJBS6BMy-L1iVKP&l=20220406172333010113135214232FAB56&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=MzpsaGY6Zjo7PDMzZzczNEApNjY6ZTtkOzxpN2Q3PDo5OmdgZ2BtcjQwai9gLS1kMS9zczJhLTEzYjEuMTJeXzQyLmM6Yw%3D%3D&vl=&vr=",
- "original_url": "https://www.tiktok.com/@oregonzoo/video/7080938094823738666",
- "platform": "tiktok",
- "status": "success",
- "url_type": "video",
- "video_author": "oregonzoo",
- "video_author_SecId": "MS4wLjABAAAArWNQ8-AZN6CxWOkqdeWsMBUuLDmJt8TWUAk0S4aWDW5V5EoqRbuczhaLnxJHCGob",
- "video_author_diggCount": 94,
- "video_author_followerCount": 1800000,
- "video_author_followingCount": 39,
- "video_author_heartCount": 29700000,
- "video_author_id": "6699816060206171141",
- "video_author_nickname": "Oregon Zoo",
- "video_author_videoCount": 264,
- "video_aweme_id": "7080938094823738666",
- "video_comment_count": 61,
- "video_create_time": "1648659375",
- "video_digg_count": 11800,
- "video_hashtags": [
- "redpanda",
- "boop",
- "sunshine"
- ],
- "video_music": "https://sf16.tiktokcdn-us.com/obj/ies-music-tx/7075363935741856558.mp3",
- "video_music_author": "Gilderoy Dauterive",
- "video_music_id": "7075363884613356330",
- "video_music_title": "Be the Sunshine",
- "video_music_url": "https://sf16.tiktokcdn-us.com/obj/ies-music-tx/7075363935741856558.mp3",
- "video_play_count": 60100,
- "video_ratio": "720p",
- "video_share_count": 298,
- "video_title": "Moshu ✨ #redpanda #boop #sunshine",
- "wm_video_url": "https://v16m-webapp.tiktokcdn-us.com/0394b9183a5852d4392a7e804bf78c55/624e20f6/video/tos/useast5/tos-useast5-ve-0068c001-tx/fc63ae232e70466398b55ccf97eb3c67/?a=1988&br=6468&bt=3234&cd=0%7C0%7C1%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=XY53A3E7nz7Th-pZSDXq&l=202204061723290101131351171341B9BB&lr=tiktok_m&mime_type=video_mp4&net=0&pl=0&qs=0&rc=MzpsaGY6Zjo7PDMzZzczNEApOjo4aDMzZmRlN2loOWk6ZWdgZ2BtcjQwai9gLS1kMS9zczBhNGA0LTIwNjNiYDQ2YmE6Yw%3D%3D&vl=&vr="
-}
-```
-
-- 下载视频请求参数
-
-```text
-http://localhost(服务器IP):2333/video?url="复制的(抖音/TikTok)口令/链接"
-# 返回无水印mp4文件
-```
-
-- 下载音频请求参数
-
-```text
-http://localhost(服务器IP):2333/music?url="复制的(抖音/TikTok)口令/链接"
-# 返回mp3文件
-```
-
----
-
-## 💾部署(方式一 手动部署)
-
-> 注:
-> 截图可能因更新问题与文字不符,一切请优先参照文字叙述。
-
-> 最好将本项目部署至海外服务器(优先选择美国地区的服务器),否则可能会出现奇怪的问题。
-
-例子:
-项目部署在国内服务器,而人在美国,点击结果页面链接报错403 ,目测与抖音CDN有关系。
-项目部署在韩国服务器,解析TikTok报错 ,目测TikTok对某些地区或IP进行了限制。
-
-> 使用宝塔Linux面板进行部署(
-> 中文宝塔要强制绑定手机号了,很流氓且无法绕过,建议使用宝塔国际版,谷歌搜索关键字aapanel自行安装,部署步骤相似。)
-
-- 首先要去安全组开放5000和2333端口(Web默认5000,API默认2333,可以在文件config.ini中修改。)
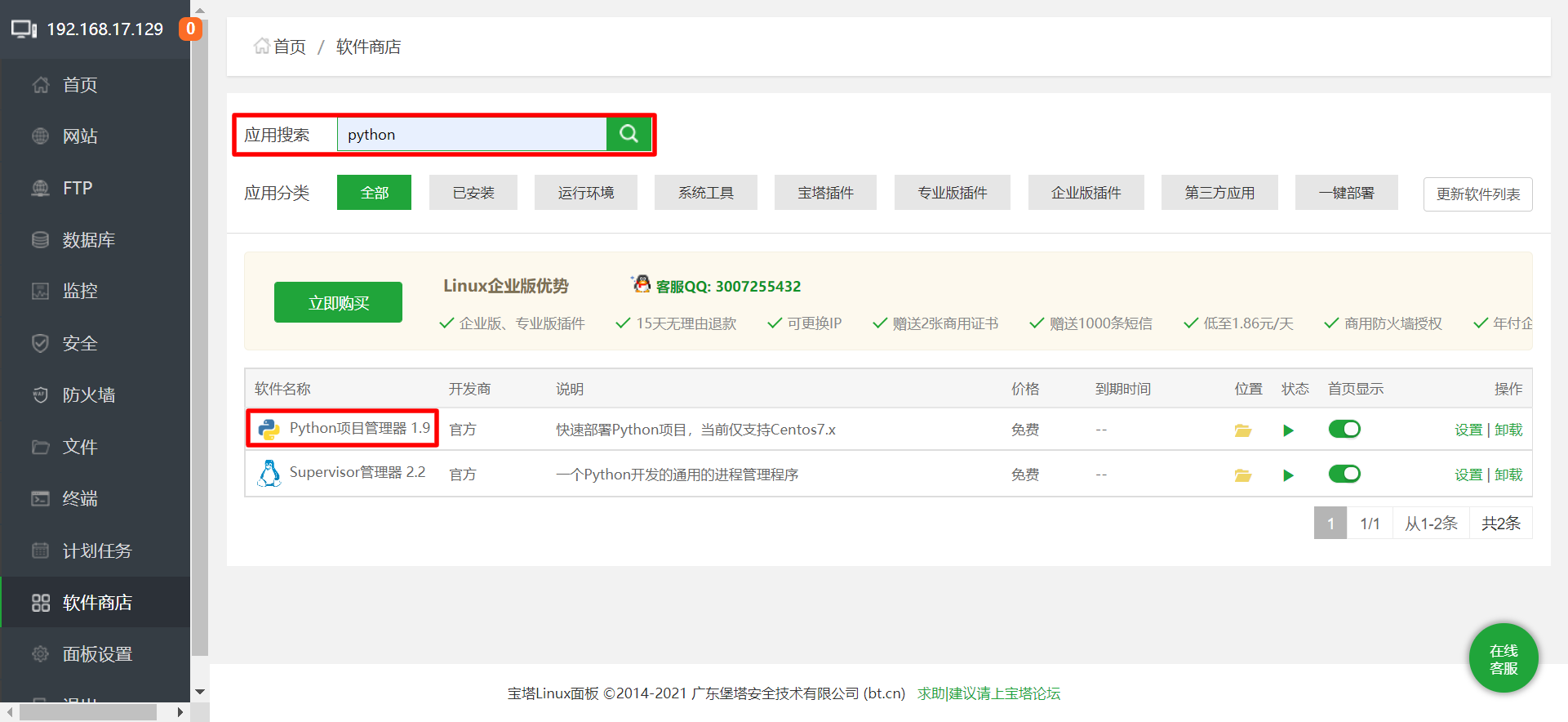
-- 在宝塔应用商店内搜索python并安装项目管理器 (推荐使用1.9版本)
-
-
-
----
-
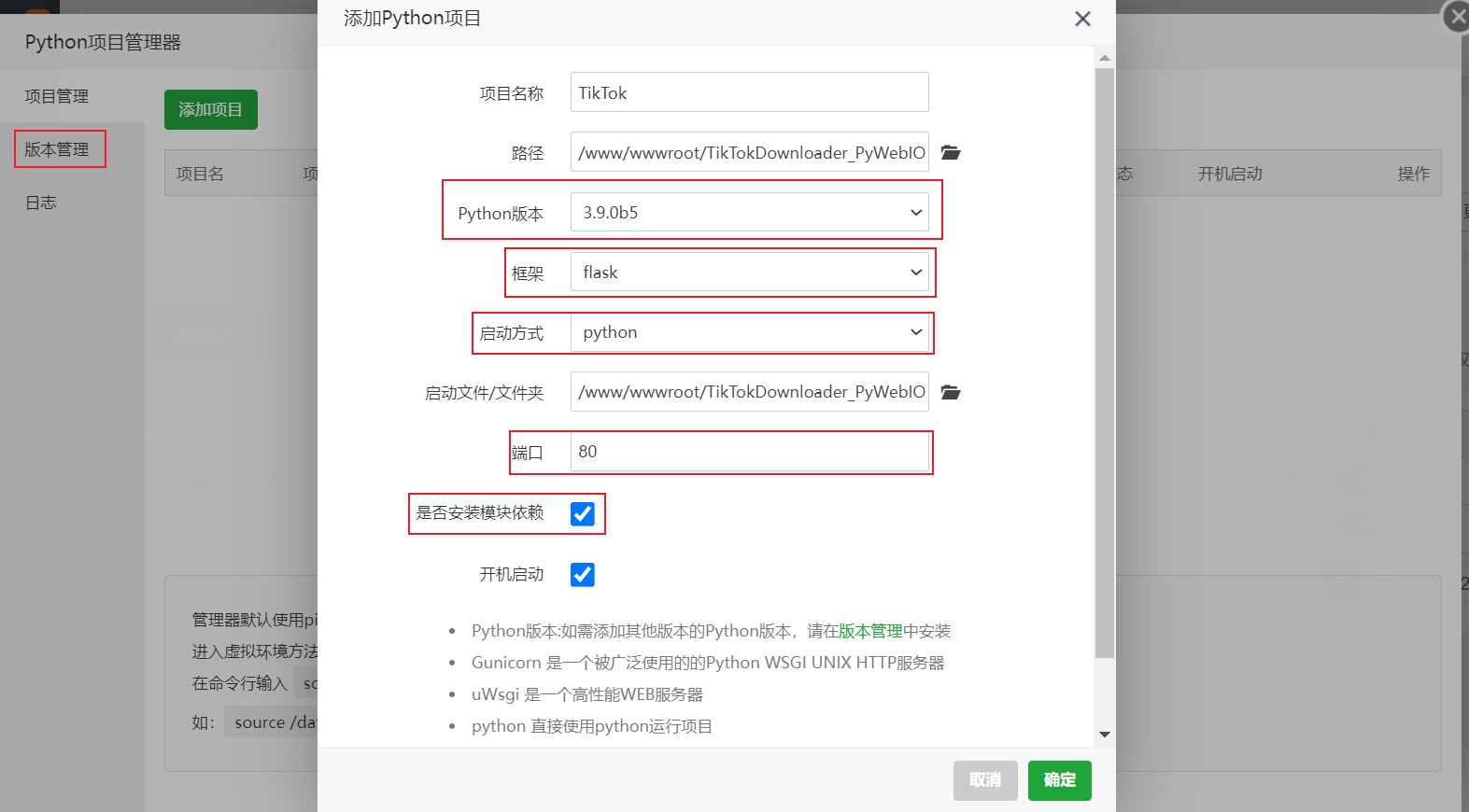
-- 创建一个项目名字随意
-- 路径选择你上传文件的路径
-- Python版本需要至少3以上(在左侧版本管理中自行安装)
-- 框架修改为`Flask`
-- 启动方式修改为`python`
-- Web启动文件选择`web_zh.py`
-- API启动文件选择`web_api.py`
-- 勾选安装模块依赖
-- 开机启动随意
-- 如果宝塔运行了`Nginx`等其他服务时请自行判断端口是否被占用,运行端口可在文件config.ini中修改。
-
-
-
-- 如果有大量请求请使用进程守护启动防止进程关闭
-
----
-
-## 💾部署(方式二 Docker)
-
-- 安装docker
-
-```yaml
-curl -fsSL get.docker.com -o get-docker.sh&&sh get-docker.sh &&systemctl enable docker&&systemctl start docker
-```
-
-- 留下config.int和docker-compose.yml文件即可
-- 运行命令,让容器在后台运行
-
-```yaml
-docker compose up -d
-```
-
-- 查看容器日志
-
-```yaml
-docker logs -f douyin_tiktok_download_api
-```
-
-- 删除容器
-
-```yaml
-docker rm -f douyin_tiktok_download_api
-```
-
-- 更新
-
-```yaml
-docker compose pull && docker compose down && docker compose up -d
-```
-
-## ❤️ 贡献者
-
-[](https://github.com/Evil0ctal)
-[](https://github.com/jw-star)
-[](https://github.com/Jeffrey-deng)
-[](https://github.com/chris-ss)
-[](https://github.com/weixuan00)
-[](https://github.com/Tairraos)
-
-## 🎉截图
-
-> 注:
-> 截图可能因更新问题与文字不符,一切请优先参照文字叙述。
-
-点击展开截图
-
-
-
-- 主界面
-
-
-
----
-
-- 解析完成
-
-> 单个
-
-
-
----
-
-> 批量
-
-
-
----
-
-- API提交/返回
-
-> 视频返回值
-
-
-
-> 图集返回值
-
-
-
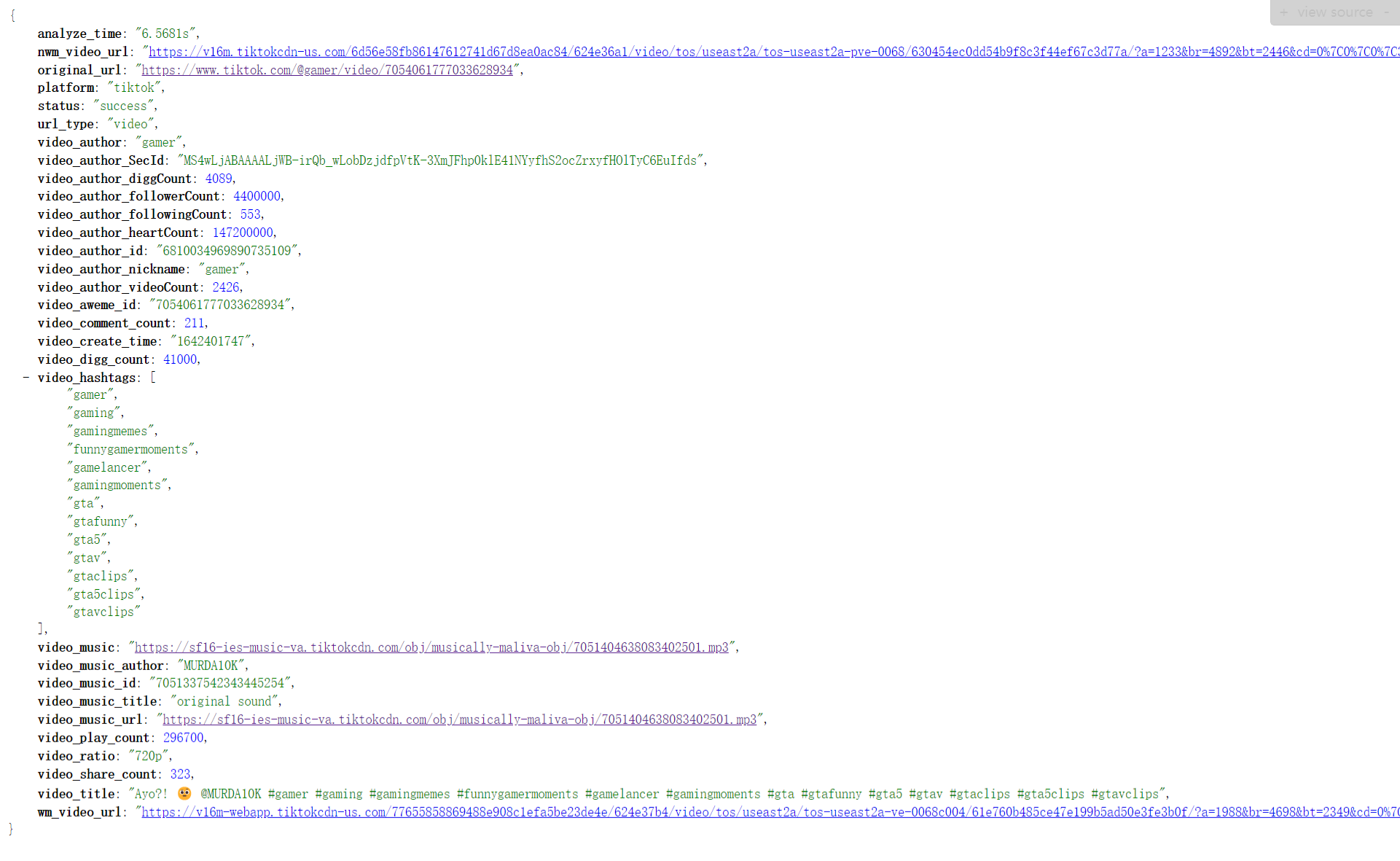
-> TikTok返回值
-
-
-
----
-
-