mirror of
https://github.com/Evil0ctal/Douyin_TikTok_Download_API.git
synced 2025-04-23 00:29:23 +08:00
Compare commits
54 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
8c98fb7032 | ||
|
|
56f4ce44a2 | ||
|
|
9ab8e11672 | ||
|
|
ab87be43af | ||
|
|
f197efd21d | ||
|
|
03e7be054f | ||
|
|
3c5e38234f | ||
|
|
945aa3d46d | ||
|
|
3b491db03e | ||
|
|
39f3abb5df | ||
|
|
492bf1693b | ||
|
|
f79f67c4db | ||
|
|
400edfad22 | ||
|
|
911d8bf086 | ||
|
|
a1cc2b6056 | ||
|
|
680339db15 | ||
|
|
c1cd8b8863 | ||
|
|
774b6b2890 | ||
|
|
32755dd86b | ||
|
|
16ed4eba5e | ||
|
|
71d6c64490 | ||
|
|
8ae46f7ad7 | ||
|
|
d67aed6f2b | ||
|
|
b438d69f84 | ||
|
|
be7752a812 | ||
|
|
a054dd4276 | ||
|
|
3d25688269 | ||
|
|
ad4e9c2694 | ||
|
|
fd5b7287ee | ||
|
|
54afe5bd9e | ||
|
|
72220dc0c2 | ||
|
|
3b526220dd | ||
|
|
dd8c567978 | ||
|
|
6c09b4181b | ||
|
|
f9b19d3527 | ||
|
|
d224556c69 | ||
|
|
a8be475f94 | ||
|
|
72ea6966fa | ||
|
|
00b227b3ba | ||
|
|
adcd379a8d | ||
|
|
a7f87dff00 | ||
|
|
d641f0340c | ||
|
|
b659af881b | ||
|
|
7d467ee269 | ||
|
|
4f322212a9 | ||
|
|
ca05f11953 | ||
|
|
a6933088e2 | ||
|
|
3221c41135 | ||
|
|
1587b7da77 | ||
|
|
89e2a59f22 | ||
|
|
530d856872 | ||
|
|
f61d362bf9 | ||
|
|
2cdef7c921 | ||
|
|
2980490444 |
33
Dockerfile
33
Dockerfile
@ -1,33 +1,26 @@
|
|||||||
# Use the official Ubuntu base image
|
# 使用官方 Python 3.11 的轻量版镜像
|
||||||
FROM ubuntu:jammy
|
FROM python:3.11-slim
|
||||||
|
|
||||||
LABEL maintainer="Evil0ctal"
|
LABEL maintainer="Evil0ctal"
|
||||||
|
|
||||||
# Set non-interactive frontend (useful for Docker builds)
|
# 设置非交互模式,避免 Docker 构建时的交互问题
|
||||||
ENV DEBIAN_FRONTEND=noninteractive
|
ENV DEBIAN_FRONTEND=noninteractive
|
||||||
|
|
||||||
# Update the package list and install Python and pip
|
# 设置工作目录
|
||||||
RUN apt-get update && apt-get install -y --no-install-recommends \
|
|
||||||
python3.11 \
|
|
||||||
python3-pip \
|
|
||||||
python3.11-dev \
|
|
||||||
&& apt-get clean \
|
|
||||||
&& rm -rf /var/lib/apt/lists/*
|
|
||||||
|
|
||||||
# Set a working directory
|
|
||||||
WORKDIR /app
|
WORKDIR /app
|
||||||
|
|
||||||
# Copy the application source code to the container
|
# 复制应用代码到容器
|
||||||
COPY . /app
|
COPY . /app
|
||||||
|
|
||||||
# Install pip and set the PyPI mirror (Aliyun)
|
# 使用 Aliyun 镜像源加速 pip
|
||||||
RUN pip3 install -i https://mirrors.aliyun.com/pypi/simple/ -U pip \
|
RUN pip install -i https://mirrors.aliyun.com/pypi/simple/ -U pip \
|
||||||
&& pip3 config set global.index-url https://mirrors.aliyun.com/pypi/simple/
|
&& pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
|
||||||
|
|
||||||
# Install dependencies directly
|
# 安装依赖
|
||||||
RUN pip3 install --no-cache-dir -r requirements.txt
|
RUN pip install --no-cache-dir -r requirements.txt
|
||||||
|
|
||||||
# Make the start script executable
|
# 确保启动脚本可执行
|
||||||
RUN chmod +x start.sh
|
RUN chmod +x start.sh
|
||||||
|
|
||||||
# Command to run on container start
|
# 设置容器启动命令
|
||||||
CMD ["./start.sh"]
|
CMD ["./start.sh"]
|
||||||
|
|||||||
317
README.en.md
317
README.en.md
@ -7,123 +7,121 @@
|
|||||||
|
|
||||||
[English](./README.en.md)\|[Simplified Chinese](./README.md)
|
[English](./README.en.md)\|[Simplified Chinese](./README.md)
|
||||||
|
|
||||||
🚀"Douyin_TikTok_Download_API" is a high-performance asynchronous API that can be used out of the box[Tik Tok](https://www.douyin.com)\|[TikTok](https://www.tiktok.com)\|[Bilibili](https://www.bilibili.com)Data crawling tool supports API calling, online batch analysis and downloading.
|
🚀 "Douyin_TikTok_Download_API" is a high-performance asynchronous out-of-the-box[Tik Tok](https://www.douyin.com)\|[Tiktok](https://www.tiktok.com)\|[Biliable](https://www.bilibili.com)Data crawling tool, supports API calls, online batch analysis and download.
|
||||||
|
|
||||||
[](LICENSE)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/releases/latest)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/stargazers)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/network/members)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues?q=is%3Aissue+is%3Aclosed)<br>[](https://pypi.org/project/douyin-tiktok-scraper/)[](https://pypi.org/project/douyin-tiktok-scraper/#files)[](https://pypi.org/project/douyin-tiktok-scraper/)[](https://pypi.org/project/douyin-tiktok-scraper/)<br>[](https://api.douyin.wtf/docs)[](https://api.tikhub.io/docs)<br>[](https://afdian.net/@evil0ctal)[](https://ko-fi.com/evil0ctal)[](https://www.patreon.com/evil0ctal)
|
[](LICENSE)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/releases/latest)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/stargazers)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/network/members)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues?q=is%3Aissue+is%3Aclosed)<br>[](https://pypi.org/project/douyin-tiktok-scraper/)[](https://pypi.org/project/douyin-tiktok-scraper/#files)[](https://pypi.org/project/douyin-tiktok-scraper/)[](https://pypi.org/project/douyin-tiktok-scraper/)<br>[](https://api.douyin.wtf/docs)[](https://api.tikhub.io/docs)<br>[](https://afdian.net/@evil0ctal)[](https://ko-fi.com/evil0ctal)[](https://www.patreon.com/evil0ctal)
|
||||||
|
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
## Sponsor
|
## Sponsors
|
||||||
|
|
||||||
These sponsors have paid to be placed here,**Douyin_TikTok_Download_API**The project will always be free and open source. If you would like to become a sponsor of this project, please check out my[GitHub Sponsor Page](https://github.com/sponsors/evil0ctal)。
|
These sponsors have paid to place them here,**Doinan_tics_download_api**The project will always be free and open source. If you wish to be a sponsor of this project, please check out my[GitHub Sponsor Page](https://github.com/sponsors/evil0ctal)。
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<hr>
|
|
||||||
<br>
|
|
||||||
<a href="https://www.tikhub.io/" target="_blank">
|
<a href="https://www.tikhub.io/" target="_blank">
|
||||||
<img src="https://tikhub.io/wp-content/uploads/2024/06/cropped-Logo_TikHub-60-300x300px.png" width="100" alt="TikHub.io API Marketplace">
|
<img src="https://tikhub.io/wp-content/uploads/2024/11/Main-Logo.webp" width="100" alt="TikHub.io - Global Social Data & API Marketplace">
|
||||||
<b></b>
|
|
||||||
<div>
|
|
||||||
<b>TikHub.io API:</b> is the leading API provider for scraping Douyin, Xiaohongshu, TikTok, Instagram, Youtube, and more. <br> Trusted by the major influencer marketing and social media listening platforms.
|
|
||||||
</div>
|
|
||||||
</a>
|
</a>
|
||||||
<br/>
|
|
||||||
<a href="https://www.sadcaptcha.com?ref=eviloctal" target="_blank">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktok3d.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktokrotate.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktokpuzzle.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktokicon.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<br/>
|
|
||||||
<div>
|
<div>
|
||||||
<b>TikTok Captcha Solver: </b> Bypass any TikTok captcha in just two lines of code.<br> Scale your TikTok automation and get unblocked with SadCaptcha.
|
<h2><b>TikHub.io</b></h2>
|
||||||
|
<p>Your Ultimate Social Media Data & API Marketplace</p>
|
||||||
|
<p>
|
||||||
|
Professional data solutions for Douyin, Xiaohongshu, TikTok, Instagram, YouTube,
|
||||||
|
Twitter, and more.<br>
|
||||||
|
Real-time Data | Flexible APIs | Seamless Integration | Competitive Pricing with Discounts
|
||||||
|
</p>
|
||||||
|
<p>
|
||||||
|
<b>Discover TikHub.io Marketplace</b><br>
|
||||||
|
Buy and sell custom APIs, services, and social media solutions.<br>
|
||||||
|
Join a thriving ecosystem of developers, businesses, and content creators.
|
||||||
|
</p>
|
||||||
|
<p><em>Trusted by leading global influencer marketing and social media intelligence platforms</em></p>
|
||||||
</div>
|
</div>
|
||||||
</a>
|
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
## 👻Introduction
|
## 👻 Introduction
|
||||||
|
|
||||||
> 🚨If you need to use a private server to run this project, please refer to:[Deployment preparations](./README.md#%EF%B8%8F%E9%83%A8%E7%BD%B2%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C%E8%AF%B7%E4%BB%94%E7%BB%86%E9%98%85%E8%AF%BB),[Docker deployment](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker),[One-click deployment](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-linux)
|
> 🚨If you want to use a private server to run this project, please refer to:[Deployment preparations](./README.md#%EF%B8%8F%E9%83%A8%E7%BD%B2%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C%E8%AF%B7%E4%BB%94%E7%BB%86%E9%98%85%E8%AF%BB),[Docker deployment](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker),[One-click deployment](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-linux)
|
||||||
|
|
||||||
This project is based on[PyWebIO](https://github.com/pywebio/PyWebIO),[FastAPI](https://fastapi.tiangolo.com/),[HTTPX](https://www.python-httpx.org/), fast and asynchronous[Tik Tok](https://www.douyin.com/)/[TikTok](https://www.tiktok.com/)Data crawling tool, and realizes online batch parsing and downloading of videos or photo albums without watermarks, data crawling API, and iOS shortcut commands without watermark downloads through the Web. You can deploy or modify this project yourself to achieve more functions, or you can call it directly in your project[scraper.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/Stable/scraper.py)or install an existing[pip package](https://pypi.org/project/douyin-tiktok-scraper/)As a parsing library, it is easy to crawl data, etc.....
|
This project is based on[Pydebio](https://github.com/pywebio/PyWebIO),[Fasting](https://fastapi.tiangolo.com/),[HTTPX](https://www.python-httpx.org/), fast asynchronous[Tik Tok](https://www.douyin.com/)/[Tiktok](https://www.tiktok.com/)Data crawling tool, and online batch analysis and downloading of watermark-free videos or picture albums through the web, data crawling API, iOS shortcuts without watermark download and other functions. You can deploy or transform this project yourself to achieve more functions, or you can call it directly in your project[scraper.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/Stable/scraper.py)Or install an existing one[pip package](https://pypi.org/project/douyin-tiktok-scraper/)As a parsing library, easy to crawl data, etc....
|
||||||
|
|
||||||
_Some simple application scenarios:_
|
_Some simple application scenarios:_
|
||||||
|
|
||||||
_Download prohibited videos, perform data analysis, download without watermark on iOS (with[Shortcut command APP that comes with iOS](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)Cooperate with the API of this project to achieve in-app downloads or read clipboard downloads), etc....._
|
_Download videos that are prohibited from being downloaded, perform data analysis, and download without watermark on iOS (with[iOS's shortcut command APP](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)In conjunction with this project API, it can realize in-app download or read clipboard download, etc...._
|
||||||
|
|
||||||
## 🔊 V4 version notes
|
## 🔊 V4 version notes
|
||||||
|
|
||||||
- If you are interested in writing this project together, please add us on WeChat`Evil0ctal`Note: Github project reconstruction, everyone can communicate and learn from each other in the group. Advertising and illegal things are not allowed. It is purely for making friends and technical exchanges.
|
- If you are interested in writing this project, please add WeChat`Evil0ctal`Note: Github project reconstruction, everyone can communicate and learn from each other in the group, and do not allow advertisements or illegal things to be made purely friends and technical communication.
|
||||||
- This project uses`X-Bogus`Algorithms and`A_Bogus`The algorithm requests the Web API of Douyin and TikTok.
|
- This project uses`X-Bogus`Algorithm and`A_Bogus`The algorithm requests TikTok and TikTok's Web API.
|
||||||
- Due to Douyin's risk control, after deploying this project, please**Obtain the cookie of Douyin website in the browser and replace it in config.yaml.**
|
- Due to Douyin's risk control, please go to**Get the Douyin website cookies in the browser and replace them in config.yaml.**
|
||||||
- Please read the document below before raising an issue. Solutions to most problems will be included in the document.
|
- Please read the document below before asking for an issue, and most solutions to the problem will be included in the document.
|
||||||
- This project is completely free, but when using it, please comply with:[Apache-2.0 license](https://github.com/Evil0ctal/Douyin_TikTok_Download_API?tab=Apache-2.0-1-ov-file#readme)
|
- This project is completely free, but please follow it when using it:[Apache-2.0 license](https://github.com/Evil0ctal/Douyin_TikTok_Download_API?tab=Apache-2.0-1-ov-file#readme)
|
||||||
|
|
||||||
## 🔖TikHub.io API
|
## 🔖TikHub.io API
|
||||||
|
|
||||||
[TikHub.io](https://api.tikhub.io/)It is an API platform that provides various public data interfaces including Douyin and TikTok. If you want to support[Douyin_TikTok_Download_API](https://github.com/Evil0ctal/Douyin_TikTok_Download_API)For project development, we strongly recommend that you choose[TikHub.io](https://api.tikhub.io/)。
|
[TikHub.io](https://api.tikhub.io/)It is an API platform that provides various public data interfaces including Douyin and TikTok. If you want to support it[Doinan_tics_download_api](https://github.com/Evil0ctal/Douyin_TikTok_Download_API)We strongly recommend that you choose the project development[TikHub.io](https://api.tikhub.io/)。
|
||||||
|
|
||||||
#### Features:
|
#### Features:
|
||||||
|
|
||||||
> 📦 Ready to use right out of the box
|
> 📦 Out of the box
|
||||||
|
|
||||||
Simplify the use process and use the packaged SDK to quickly carry out development work. All API interfaces are designed based on RESTful architecture and are described and documented using OpenAPI specifications, with sample parameters included to ensure easier calling.
|
Simplify the usage process and quickly carry out development work using the encapsulated SDK. All API interfaces are designed according to the RESTful architecture and are described and documented using the OpenAPI specification, accompanied by example parameters to ensure that calls are easier.
|
||||||
|
|
||||||
> 💰 Cost advantage
|
> 💰 Cost Advantage
|
||||||
|
|
||||||
There are no preset package restrictions and no monthly usage thresholds. All consumption is billed immediately based on actual usage, and tiered billing is performed based on the user's daily requests. At the same time, free quota can be obtained through daily sign-in in the user backend. , and these free credits will not expire.
|
There is no preset package limit, no monthly usage threshold, all consumption is billed instantly based on the actual usage, and is billed step by step based on the user's daily request volume. At the same time, you can check in in the user's background through daily check-in, and these free amounts will not expire.
|
||||||
|
|
||||||
> ⚡️ Fast support
|
> ⚡️ Quick support
|
||||||
|
|
||||||
We have a large Discord community server, where administrators and other users will quickly reply to you and help you quickly solve current problems.
|
We have a huge Discord community server where administrators and other users will quickly reply to you to help you quickly resolve current issues.
|
||||||
|
|
||||||
> 🎉Embrace open source
|
> 🎉 Embrace open source
|
||||||
|
|
||||||
Part of TikHub's source code will be open sourced on Github, and it will sponsor authors of some open source projects.
|
Some of the source code of TikHub will be open sourced on Github and will sponsor some open source projects.
|
||||||
|
|
||||||
#### Link:
|
#### Link:
|
||||||
|
|
||||||
- Github:[TikHub Github](https://github.com/TikHubIO)
|
- Githubub:[TIKHOB GITUB](https://github.com/TikHubIO)
|
||||||
- Discord:[Tikhub discord](https://discord.com/invite/aMEAS8Xsvz)
|
- Discord:[Tachub](https://discord.com/invite/aMEAS8Xsvz)
|
||||||
- Register:[TikHub signup](https://beta-web.tikhub.io/en-us/users/signup)
|
- Register:[TikHub singnup](https://beta-web.tikhub.io/en-us/users/signup)
|
||||||
- API Docs:[Cheers to my father, Dex](https://api.tikhub.io/)
|
- API Docs:[TickHub API Docs](https://api.tikhub.io/)
|
||||||
|
|
||||||
## 🖥Demo site: I am very vulnerable...please do not stress test (·•᷄ࡇ•᷅ )
|
## 🖥 Demo site: I am very fragile... Please do not press test (·•᷄ࡇ•᷅ )
|
||||||
|
|
||||||
> 😾The online download function of the demo site has been turned off, and due to cookie reasons, the availability of Douyin's parsing and API services cannot be guaranteed on the Demo site.
|
> 😾The online download function of the demo site has been turned off, and Douyin's parsing and API services cannot be guaranteed for availability on the Demo site due to cookies.
|
||||||
|
|
||||||
🍔Web APP:<https://douyin.wtf/>
|
🍔Web APP:<https://douyin.wtf/>
|
||||||
|
|
||||||
🍟API Document:<https://douyin.wtf/docs>
|
🍟API Document:<https://douyin.wtf/docs>
|
||||||
|
|
||||||
🌭TikHub API Document:<https://api.tikhub.io/docs>
|
🌭tikub APU Docuration:<https://api.tikhub.io/docs>
|
||||||
|
|
||||||
💾iOS Shortcut (shortcut command):[Shortcut release](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/discussions/104?sort=top)
|
💾 iOS Shortcut:[Shortcut release](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/discussions/104?sort=top)
|
||||||
|
|
||||||
📦️Desktop downloader (recommended by warehouse):
|
📦️Desktop downloader (recommended warehouse):
|
||||||
|
|
||||||
- [Johnserf-Seed/TikTokDownload](https://github.com/Johnserf-Seed/TikTokDownload)
|
- [Johnserf-Seed/Tiktokdownload](https://github.com/Johnserf-Seed/TikTokDownload)
|
||||||
- [HFrost0/bilix](https://github.com/HFrost0/bilix)
|
- [HFrost0/bilix](https://github.com/HFrost0/bilix)
|
||||||
- [Tairraos/TikDown - \[needs update\]](https://github.com/Tairraos/TikDown/)
|
- [Tairraos/TikDown - \[Updated to be\]](https://github.com/Tairraos/TikDown/)
|
||||||
|
|
||||||
## ⚗️Technology stack
|
## ⚗️Technology Stack
|
||||||
|
|
||||||
- [/app/web](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/app/web)-[PyWebIO](https://www.pyweb.io/)
|
- [/app/web](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/app/web)-[Pydebio](https://www.pyweb.io/)
|
||||||
- [/app/api](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/app/api)-[FastAPI](https://fastapi.tiangolo.com/)
|
- [/app/api](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/app/api)-[Fasting](https://fastapi.tiangolo.com/)
|
||||||
- [/crawlers](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/crawlers)-[HTTPX](https://www.python-httpx.org/)
|
- [/crawlers](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/crawlers)-[HTTPX](https://www.python-httpx.org/)
|
||||||
|
|
||||||
> **_/crawlers_**
|
> **_/crawlers_**
|
||||||
|
|
||||||
- Submit requests to APIs on different platforms and retrieve data. After processing, a dictionary (dict) is returned, and asynchronous support is supported.
|
- Submit requests to APIs of different platforms and retrieve data, and return dictionary (dict) after processing, supports asynchronousness.
|
||||||
|
|
||||||
> **_/app/api_**
|
> **_/app/api_**
|
||||||
|
|
||||||
- Get request parameters and use`Crawlers`The related classes process the data and return it in JSON form, download the video, and cooperate with iOS shortcut commands to achieve fast calling and support asynchronous.
|
- Obtain the request parameters and use`Crawlers`After processing data, the related classes return in JSON form, download videos, and implement fast calls with iOS shortcuts, and support asynchronous.
|
||||||
|
|
||||||
> **_/app/web_**
|
> **_/app/web_**
|
||||||
|
|
||||||
- use`PyWebIO`A simple web program created to process the values entered on the web page and use them`Crawlers`The related class processing interface outputs related data on the web page.
|
- use`PyWebIO`A simple web program created, process the value entered on the web page and use it`Crawlers`The related class processing interface outputs related data on the web page.
|
||||||
|
|
||||||
**_Most of the parameters of the above files can be found in the corresponding`config.yaml`Make changes in_**
|
**_Most of the parameters of the above files can be in the corresponding`config.yaml`Make modifications in_**
|
||||||
|
|
||||||
## 💡Project file structure
|
## 💡Project file structure
|
||||||
|
|
||||||
@ -146,78 +144,83 @@ Part of TikHub's source code will be open sourced on Github, and it will sponsor
|
|||||||
│ └─web
|
│ └─web
|
||||||
└─utils
|
└─utils
|
||||||
|
|
||||||
## ✨Supported functions:
|
## ✨Support functions:
|
||||||
|
|
||||||
- Batch parsing on the web page (supports Douyin/TikTok mixed parsing)
|
- Batch analysis on the web side (supports Douyin/TikTok hybrid analysis)
|
||||||
- Download videos or photo albums online.
|
- Download videos or albums online.
|
||||||
- make[pip package](https://pypi.org/project/douyin-tiktok-scraper/)Conveniently and quickly import your projects
|
- Production[pip package](https://pypi.org/project/douyin-tiktok-scraper/)方便快速导入你的项目
|
||||||
- [iOS shortcut commands to quickly call API](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)Achieve in-app download of watermark-free videos/photo albums
|
- [iOS shortcuts to quickly call API](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)Implement watermark-free videos/pictures in-app download
|
||||||
- Complete API documentation ([Demo/Demonstration](https://api.douyin.wtf/docs))
|
- Complete API documentation ([Demo/Demo](https://api.douyin.wtf/docs))
|
||||||
- Rich API interface:
|
- Rich API interfaces:
|
||||||
- Douyin web version API
|
- TikTok web version API
|
||||||
|
|
||||||
- [x] Video data analysis
|
- [x] Video data analysis
|
||||||
- [x] Get user homepage work data
|
- [x] Obtain user's homepage work data
|
||||||
- [x] Obtain the data of works liked by the user's homepage
|
- [x] Obtain data on the user's homepage liked works
|
||||||
- [x] Obtain the data of collected works on the user's homepage
|
- [x] Obtain data on the user's homepage collection of works
|
||||||
- [x] Get user homepage information
|
- [x] Get user homepage information
|
||||||
- [x] Get user collection work data
|
- [x] Obtain user compiled works data
|
||||||
- [x] Get user live stream data
|
- [x] Obtain user live streaming data
|
||||||
- [x] Get the live streaming data of a specified user
|
- [x] Get live streaming data for the specified user
|
||||||
- [x] Get the ranking of users who give gifts in the live broadcast room
|
- [x] Get the ranking of gift-giving users in the live broadcast room
|
||||||
- [x] Get single video comment data
|
- [x] Get individual video comment data
|
||||||
- [x] Get the comment reply data of the specified video
|
- [x] Get comments and response data for specified videos
|
||||||
- [x] Generate msToken
|
- [x] Generate msToken
|
||||||
- [x] Generate verify_fp
|
- [x] Generate verification_fp
|
||||||
- [x] Generate s_v_web_id
|
- [x] Generate s_v_web_id
|
||||||
- [x] Generate X-Bogus parameters using interface URL
|
- [x] Generate X-Bogus parameters using interface URL
|
||||||
- [x] Generate A_Bogus parameters using interface URL
|
- [x] Generate A_Bogus parameters using interface URL
|
||||||
- [x] Extract a single user id
|
- [x] Extract a single user id
|
||||||
- [x] Extract list user id
|
- [x] Extract list user id
|
||||||
- [x] Extract a single work id
|
- [x] Extract individual works id
|
||||||
- [x] Extract list work id
|
- [x] Extract list work id
|
||||||
- [x] Extract live broadcast room number from list
|
- [x] Extract list live broadcast room number
|
||||||
- [x] Extract live broadcast room number from list
|
- [x] Extract list live broadcast room number
|
||||||
- TikTok web version API
|
- TikTok web version API
|
||||||
|
|
||||||
- [x] Video data analysis
|
- [x] Video data analysis
|
||||||
- [x] Get user homepage work data
|
- [x] Obtain user's homepage work data
|
||||||
- [x] Obtain the data of works liked by the user's homepage
|
- [x] Obtain data on the user's homepage liked works
|
||||||
- [x] Get user homepage information
|
- [x] Get user homepage information
|
||||||
- [x] Get fan data on user homepage
|
- [x] Get the user's homepage fan data
|
||||||
- [x] Get user homepage follow data
|
- [x] Get user's homepage follow data
|
||||||
- [x] Get user homepage collection work data
|
- [x] 获取用户主页合辑作品数据
|
||||||
- [x] Get user homepage collection data
|
- [x] Get search data for users' homepage
|
||||||
- [x] Get user homepage playlist data
|
- [x] Get user homepage playlist data
|
||||||
- [x] Get single video comment data
|
- [x] Get individual video comment data
|
||||||
- [x] Get the comment reply data of the specified video
|
- [x] Get comments and response data for specified videos
|
||||||
- [x] Generate msToken
|
- [x] Generate msToken
|
||||||
- [x] Generate ttwid
|
- [x] Generate ttwid
|
||||||
- [x] Generate X-Bogus parameters using interface URL
|
- [x] Generate X-Bogus parameters using interface URL
|
||||||
- [x] Extract a single user sec_user_id
|
- [x] Extract individual user sec_user_id
|
||||||
- [x] Extract list user sec_user_id
|
- [x] Extract list user sec_user_id
|
||||||
- [x] Extract a single work id
|
- [x] Extract individual works id
|
||||||
- [x] Extract list work id
|
- [x] Extract list work id
|
||||||
- [x] Get user unique_id
|
- [x] Get user unique_id
|
||||||
- [x] Get list unique_id
|
- [x] Get the list unique_id
|
||||||
- Bilibili web version API
|
- Bilibili web version API
|
||||||
- [x] Get individual video details
|
- [x] Get individual video details
|
||||||
- [x] Obtain user-published video work data
|
- [x] Get the video streaming address
|
||||||
- [x] Get all the user's favorites information
|
- [x] Obtain data on video works published by users
|
||||||
- [x] Get video data in specified favorites
|
- [x] Get all user favorites information
|
||||||
- [x] Get information about a specified user
|
- [x] Get video data in the specified favorites
|
||||||
|
- [x] Get information about the specified user
|
||||||
- [x] Get comprehensive popular video information
|
- [x] Get comprehensive popular video information
|
||||||
- [x] Get comments for specified video
|
- [x] Get comments for the specified video
|
||||||
- [x] Get the reply to the specified comment under the video
|
- [x] Get a reply to the specified comment under the video
|
||||||
- [x] Get the specified user's updates
|
- [x] Get the specified user dynamics
|
||||||
- [x] Get specified live broadcast room information
|
- [x] Get real-time video barrage
|
||||||
- [x] Get a list of all live broadcast partitions
|
- [x] Get information about the specified live broadcast room
|
||||||
|
- [x] Get live video streaming
|
||||||
|
- [x] Get the anchor who is currently broadcasting in the specified partition
|
||||||
|
- [x] Get a list of all live partitions
|
||||||
|
- [x] Obtain video score information through bv number
|
||||||
|
|
||||||
* * *
|
* * *
|
||||||
|
|
||||||
## 📦Call the parsing library (obsolete and needs to be updated):
|
## 📦 Call the parsing library (deprecated and needs to be updated):
|
||||||
|
|
||||||
> 💡PyPi:<https://pypi.org/project/douyin-tiktok-scraper/>
|
> 💡PIPI :<https://pypi.org/project/douyin-tiktok-scraper/>
|
||||||
|
|
||||||
Install the parsing library:`pip install douyin-tiktok-scraper`
|
Install the parsing library:`pip install douyin-tiktok-scraper`
|
||||||
|
|
||||||
@ -238,45 +241,45 @@ asyncio.run(hybrid_parsing(url=input("Paste Douyin/TikTok/Bilibili share URL her
|
|||||||
|
|
||||||
## 🗺️Supported submission formats:
|
## 🗺️Supported submission formats:
|
||||||
|
|
||||||
> 💡Tip: Including but not limited to the following examples, if you encounter link parsing failure, please open a new one[issue](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)
|
> 💡 Tip: Includes but is not limited to the following examples. If you encounter link resolution failure, please enable a new one.[issue](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)
|
||||||
|
|
||||||
- Douyin sharing password (copy in APP)
|
- TikTok Sharing Password (Copy within the APP)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
7.43 pda:/ 让你在几秒钟之内记住我 https://v.douyin.com/L5pbfdP/ 复制此链接,打开Dou音搜索,直接观看视频!
|
7.43 pda:/ 让你在几秒钟之内记住我 https://v.douyin.com/L5pbfdP/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||||
```
|
```
|
||||||
|
|
||||||
- Douyin short URL (copy within APP)
|
- TikTok short URL (copy within the APP)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
https://v.douyin.com/L4FJNR3/
|
https://v.douyin.com/L4FJNR3/
|
||||||
```
|
```
|
||||||
|
|
||||||
- Douyin normal URL (copy from web version)
|
- Douyin Normal URL (web version copy)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
https://www.douyin.com/video/6914948781100338440
|
https://www.douyin.com/video/6914948781100338440
|
||||||
```
|
```
|
||||||
|
|
||||||
- Douyin discovery page URL (APP copy)
|
- TikTok Discovery Page URL (APP Copy)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
https://www.douyin.com/discover?modal_id=7069543727328398622
|
https://www.douyin.com/discover?modal_id=7069543727328398622
|
||||||
```
|
```
|
||||||
|
|
||||||
- TikTok short URL (copy within APP)
|
- TikTok short URL (copy within the APP)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
https://www.tiktok.com/t/ZTR9nDNWq/
|
https://www.tiktok.com/t/ZTR9nDNWq/
|
||||||
```
|
```
|
||||||
|
|
||||||
- TikTok normal URL (copy from web version)
|
- TikTok normal website address (web version copy)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||||
```
|
```
|
||||||
|
|
||||||
- Douyin/TikTok batch URL (no need to use matching separation)
|
- TikTok batch URL (no need to use matching separation)
|
||||||
|
|
||||||
```text
|
```text
|
||||||
https://v.douyin.com/L4NpDJ6/
|
https://v.douyin.com/L4NpDJ6/
|
||||||
@ -287,7 +290,7 @@ https://www.tiktok.com/t/ZTR9nDNWq/
|
|||||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||||
```
|
```
|
||||||
|
|
||||||
## 🛰️API documentation
|
## 🛰️API Documentation
|
||||||
|
|
||||||
**_API documentation:_**
|
**_API documentation:_**
|
||||||
|
|
||||||
@ -295,71 +298,71 @@ local:<http://localhost/docs>
|
|||||||
|
|
||||||
Online:<https://api.douyin.wtf/docs>
|
Online:<https://api.douyin.wtf/docs>
|
||||||
|
|
||||||
**_API demo:_**
|
**_API Demo:_**
|
||||||
|
|
||||||
- Crawl video data (TikTok or Douyin hybrid analysis)`https://api.douyin.wtf/api/hybrid/video_data?url=[视频链接/Video URL]&minimal=false`
|
- Crawl video data (TikTok or Douyin mixed analysis)`https://api.douyin.wtf/api/hybrid/video_data?url=[视频链接/Video URL]&minimal=false`
|
||||||
- Download videos/photo albums (TikTok or Douyin hybrid analysis)`https://api.douyin.wtf/api/download?url=[视频链接/Video URL]&prefix=true&with_watermark=false`
|
- Download video/picture album (TikTok or Douyin mixed analysis)`https://api.douyin.wtf/api/download?url=[视频链接/Video URL]&prefix=true&with_watermark=false`
|
||||||
|
|
||||||
**_For more demonstrations, please see the documentation..._**
|
**_For more demonstrations, please check the document content..._**
|
||||||
|
|
||||||
## ⚠️Preparation work before deployment (please read carefully):
|
## ⚠️Preparation before deployment (please read carefully):
|
||||||
|
|
||||||
- You need to solve the problem of crawler cookie risk control by yourself, otherwise the interface may become unusable. After modifying the configuration file, you need to restart the service for it to take effect, and it is best to use cookies from accounts that you have already logged in to.
|
- You need to solve the risk control problem of crawler cookies by yourself, otherwise the interface may be unavailable. After modifying the configuration file, you need to restart the service before it takes effect. It is best to use cookies from the account you have logged in.
|
||||||
- Douyin web cookie (obtain and replace the cookie in the configuration file below):
|
- Douyin web cookies (acquire and replace cookies in the following configuration files):
|
||||||
- <https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/30e56e5a7f97f87d60b1045befb1f6db147f8590/crawlers/douyin/web/config.yaml#L7>
|
- <https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/30e56e5a7f97f87d60b1045befb1f6db147f8590/crawlers/douyin/web/config.yaml#L7>
|
||||||
- TikTok web-side cookies (obtain and replace the cookies in the configuration file below):
|
- TikTok web cookies (acquire and replace cookies in the following configuration files):
|
||||||
- <https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/30e56e5a7f97f87d60b1045befb1f6db147f8590/crawlers/tiktok/web/config.yaml#L6>
|
- <https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/30e56e5a7f97f87d60b1045befb1f6db147f8590/crawlers/tiktok/web/config.yaml#L6>
|
||||||
- I turned off the online download function of the demo site. The video someone downloaded was so huge that it crashed the server. You can right-click on the web page parsing results page to save the video...
|
- I turned off the online download function of the demonstration site. Someone downloaded a huge video and it crashed directly on my server. You can right-click to save the video on the web parsing result page...
|
||||||
- The cookies of the demo site are my own and are not guaranteed to be valid for a long time. They only serve as a demonstration. If you deploy it yourself, please obtain the cookies yourself.
|
- The cookies on the demo site are my own and are not guaranteed to be valid for a long time. They only serve as a demonstration. If you deploy it yourself, please get the cookies yourself.
|
||||||
- If you need to directly access the video link returned by TikTok Web API, an HTTP 403 error will occur. Please use the API in this project.`/api/download`The interface downloads TikTok videos. This interface has been manually closed in the demo site, and you need to deploy this project by yourself.
|
- HTTP 403 error will occur if you need to access the video link returned by TikTok Web API. Please use the API in this project`/api/download`The interface downloads TikTok videos. This interface has been manually closed in the demonstration site, and you need to deploy this project yourself.
|
||||||
- here is one**Video tutorial**You can refer to:**_<https://www.bilibili.com/video/BV1vE421j7NR/>_**
|
- There is one here**Video tutorial**You can refer to:**_<https://www.bilibili.com/video/BV1vE421j7NR/>_**
|
||||||
|
|
||||||
## 💻Deployment (Method 1 Linux)
|
## 💻Deployment (Method 1 Linux)
|
||||||
|
|
||||||
> 💡Tips: It is best to deploy this project to a server in the United States, otherwise strange BUGs may occur.
|
> 💡Tip: It is best to deploy this project to a server in the United States, otherwise strange bugs may occur.
|
||||||
|
|
||||||
Recommended for everyone to use[Digitalocean](https://www.digitalocean.com/)server, because you can have sex for free.
|
Recommended to use[DigitalOcean](https://www.digitalocean.com/)server, because it can be free.
|
||||||
|
|
||||||
Use my invitation link to sign up and you can get a $200 credit, and when you spend $25 on it, I can also get a $25 reward.
|
Sign up with my invitation link and you can get a credit of $200, and I can get a reward of $25 when you spend $25 on it.
|
||||||
|
|
||||||
My invitation link:
|
My invitation link:
|
||||||
|
|
||||||
<https://m.do.co/c/9f72a27dec35>
|
<https://m.do.co/c/9f72a27dec35>
|
||||||
|
|
||||||
> Use script to deploy this project with one click
|
> Use scripts to deploy this project in one click
|
||||||
|
|
||||||
- This project provides a one-click deployment script that can quickly deploy this project on the server.
|
- This project provides one-click deployment scripts to quickly deploy the project on the server.
|
||||||
- The script was tested on Ubuntu 20.04 LTS. Other systems may have problems. If there are any problems, please solve them yourself.
|
- The script was tested on Ubuntu 20.04 LTS, and other systems may have problems. If there are any problems, please solve them yourself.
|
||||||
- Download using wget command[install.sh](https://raw.githubusercontent.com/Evil0ctal/Douyin_TikTok_Download_API/main/bash/install.sh)to the server and run
|
- Download using wget command[install.sh](https://raw.githubusercontent.com/Evil0ctal/Douyin_TikTok_Download_API/main/bash/install.sh)Go to the server and run
|
||||||
|
|
||||||
|
|
||||||
wget -O install.sh https://raw.githubusercontent.com/Evil0ctal/Douyin_TikTok_Download_API/main/bash/install.sh && sudo bash install.sh
|
wget -O install.sh https://raw.githubusercontent.com/Evil0ctal/Douyin_TikTok_Download_API/main/bash/install.sh && sudo bash install.sh
|
||||||
|
|
||||||
> Start/stop service
|
> Turn on/stop service
|
||||||
|
|
||||||
- Use the following commands to control running or stopping the service:
|
- Use the following command to control the operation or stop of the service:
|
||||||
- `sudo systemctl start Douyin_TikTok_Download_API.service`
|
- `sudo systemctl start Douyin_TikTok_Download_API.service`
|
||||||
- `sudo systemctl stop Douyin_TikTok_Download_API.service`
|
- `sudo systemctl stop Douyin_TikTok_Download_API.service`
|
||||||
|
|
||||||
> 开启/关闭开机自动运行
|
> Turn on/off automatically
|
||||||
|
|
||||||
- Use the following commands to set the service to run automatically at boot or cancel automatic run at boot:
|
- Use the following command to set the service to automatically run on or cancel the automatic run on:
|
||||||
- `sudo systemctl enable Douyin_TikTok_Download_API.service`
|
- `sudo systemctl enable Douyin_TikTok_Download_API.service`
|
||||||
- `sudo systemctl disable Douyin_TikTok_Download_API.service`
|
- `sudo systemctl disable Douyin_TikTok_Download_API.service`
|
||||||
|
|
||||||
> Update project
|
> Update the project
|
||||||
|
|
||||||
- When the project is updated, ensure that the update script is executed in the virtual environment and all dependencies are updated. Enter the project bash directory and run update.sh:
|
- When the project is updated, make sure that the update script is executed in the virtual environment and update all dependencies. Enter the project bash directory and run update.sh:
|
||||||
- `cd /www/wwwroot/Douyin_TikTok_Download_API/bash && sudo bash update.sh`
|
- `cd /www/wwwroot/Douyin_TikTok_Download_API/bash && sudo bash update.sh`
|
||||||
|
|
||||||
## 💽Deployment (Method 2 Docker)
|
## 💽Deployment (Method 2 Docker)
|
||||||
|
|
||||||
> 💡Tip: Docker deployment is the simplest deployment method and is suitable for users who are not familiar with Linux. This method is suitable for ensuring environment consistency, isolation and quick setup.
|
> 💡 Tip: Docker deployment is the easiest way to deploy, suitable for users who are not familiar with Linux. This method is suitable for ensuring environmental consistency, isolation and quick settings.
|
||||||
> Please use a server that can normally access Douyin or TikTok, otherwise strange BUG may occur.
|
> Please use a server that can access Douyin or TikTok normally, otherwise strange bugs may occur.
|
||||||
|
|
||||||
### Preparation
|
### Preparation
|
||||||
|
|
||||||
Before you begin, make sure Docker is installed on your system. If you haven't installed Docker yet, you can install it from[Docker official website](https://www.docker.com/products/docker-desktop/)Download and install.
|
Before you begin, make sure your system has Docker installed. If Docker is not installed, you can[Docker official website](https://www.docker.com/products/docker-desktop/)Download and install.
|
||||||
|
|
||||||
### Step 1: Pull the Docker image
|
### Step 1: Pull the Docker image
|
||||||
|
|
||||||
@ -369,40 +372,40 @@ First, pull the latest Douyin_TikTok_Download_API image from Docker Hub.
|
|||||||
docker pull evil0ctal/douyin_tiktok_download_api:latest
|
docker pull evil0ctal/douyin_tiktok_download_api:latest
|
||||||
```
|
```
|
||||||
|
|
||||||
Can be replaced if needed`latest`Label the specific version you need to deploy.
|
If necessary, you can replace it`latest`Tags for the specific version you need to deploy.
|
||||||
|
|
||||||
### Step 2: Run the Docker container
|
### Step 2: Run the Docker container
|
||||||
|
|
||||||
After pulling the image, you can start a container from this image. Here are the commands to run the container, including basic configuration:
|
After pulling the image, you can start a container from this image. The following are the commands to run the container, including the basic configuration:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker run -d --name douyin_tiktok_api -p 80:80 evil0ctal/douyin_tiktok_download_api
|
docker run -d --name douyin_tiktok_api -p 80:80 evil0ctal/douyin_tiktok_download_api
|
||||||
```
|
```
|
||||||
|
|
||||||
Each part of this command does the following:
|
Each part of this command works as follows:
|
||||||
|
|
||||||
- `-d`: Run the container in the background (detached mode).
|
- `-d`: Run containers in the background (separated mode).
|
||||||
- `--name douyin_tiktok_api `: Name the container`douyin_tiktok_api `。
|
- `--name douyin_tiktok_api `: Name the container`douyin_tiktok_api `。
|
||||||
- `-p 80:80`: Map port 80 on the host to port 80 of the container. Adjust the port number based on your configuration or port availability.
|
- `-p 80:80`: Map port 80 on the host to port 80 of the container. Adjust the port number according to your configuration or port availability.
|
||||||
- `evil0ctal/douyin_tiktok_download_api`: The name of the Docker image to use.
|
- `evil0ctal/douyin_tiktok_download_api`: The name of the Docker image to be used.
|
||||||
|
|
||||||
### Step 3: Verify the container is running
|
### Step 3: Verify that the container is running
|
||||||
|
|
||||||
Check if your container is running using the following command:
|
Use the following command to check if your container is running:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker ps
|
docker ps
|
||||||
```
|
```
|
||||||
|
|
||||||
This will list all active containers. Find`douyin_tiktok_api `to confirm that it is functioning properly.
|
这将列出所有活动容器。查找`douyin_tiktok_api `to confirm its normal operation.
|
||||||
|
|
||||||
### Step 4: Access the App
|
### Step 4: Access the application
|
||||||
|
|
||||||
Once the container is running, you should be able to pass`http://localhost`Or API client access Douyin_TikTok_Download_API. Adjust the URL if a different port is configured or accessed from a remote location.
|
After the container runs, you should be able to pass`http://localhost`Or the API client access Douyin_TikTok_Download_API. If you have a different port configured or accessed from a remote location, adjust the URL.
|
||||||
|
|
||||||
### Optional: Custom Docker commands
|
### Optional: Custom Docker commands
|
||||||
|
|
||||||
For more advanced deployments, you may wish to customize Docker commands to include environment variables, volume mounts for persistent data, or other Docker parameters. Here is an example:
|
For more advanced deployments, you may want to customize Docker commands, including environment variables, volume mounts for persistent data, or other Docker parameters. Here is an example:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
docker run -d --name douyin_tiktok_api -p 80:80 \
|
docker run -d --name douyin_tiktok_api -p 80:80 \
|
||||||
@ -411,12 +414,12 @@ docker run -d --name douyin_tiktok_api -p 80:80 \
|
|||||||
evil0ctal/douyin_tiktok_download_api
|
evil0ctal/douyin_tiktok_download_api
|
||||||
```
|
```
|
||||||
|
|
||||||
- `-v /path/to/your/data:/data`: Change the`/path/to/your/data`Directory mounted to the container`/data`Directory for persisting or sharing data.
|
- `-v /path/to/your/data:/data`: Turn on the host`/path/to/your/data`The directory mounted to the container`/data`Directory, used to persist or share data.
|
||||||
- `-e MY_ENV_VAR=my_value`: Set environment variables within the container`MY_ENV_VAR`, whose value is`my_value`。
|
- `-e MY_ENV_VAR=my_value`: Set environment variables in the container`MY_ENV_VAR`, its value is`my_value`。
|
||||||
|
|
||||||
### Configuration file modification
|
### Configuration file modification
|
||||||
|
|
||||||
Most of the project configuration can be found in the following directories:`config.yaml`File modification:
|
Most of the configurations of the project can be found in the following directories`config.yaml`Modify the file:
|
||||||
|
|
||||||
- `/crawlers/douyin/web/config.yaml`
|
- `/crawlers/douyin/web/config.yaml`
|
||||||
- `/crawlers/tiktok/web/config.yaml`
|
- `/crawlers/tiktok/web/config.yaml`
|
||||||
@ -424,7 +427,7 @@ Most of the project configuration can be found in the following directories:`con
|
|||||||
|
|
||||||
### Step 5: Stop and remove the container
|
### Step 5: Stop and remove the container
|
||||||
|
|
||||||
When you need to stop and remove containers, use the following commands:
|
When you need to stop and remove the container, use the following command:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# Stop
|
# Stop
|
||||||
@ -436,17 +439,17 @@ docker rm douyin_tiktok_api
|
|||||||
|
|
||||||
## 📸Screenshot
|
## 📸Screenshot
|
||||||
|
|
||||||
**_API speed test (compared to official API)_**
|
**_API speed test (compare the official API)_**
|
||||||
|
|
||||||
<details><summary>🔎点击展开截图</summary>
|
<details><summary>🔎点击展开截图</summary>
|
||||||
|
|
||||||
Douyin official API:
|
TikTok official API:
|
||||||
|
|
||||||
API of this project: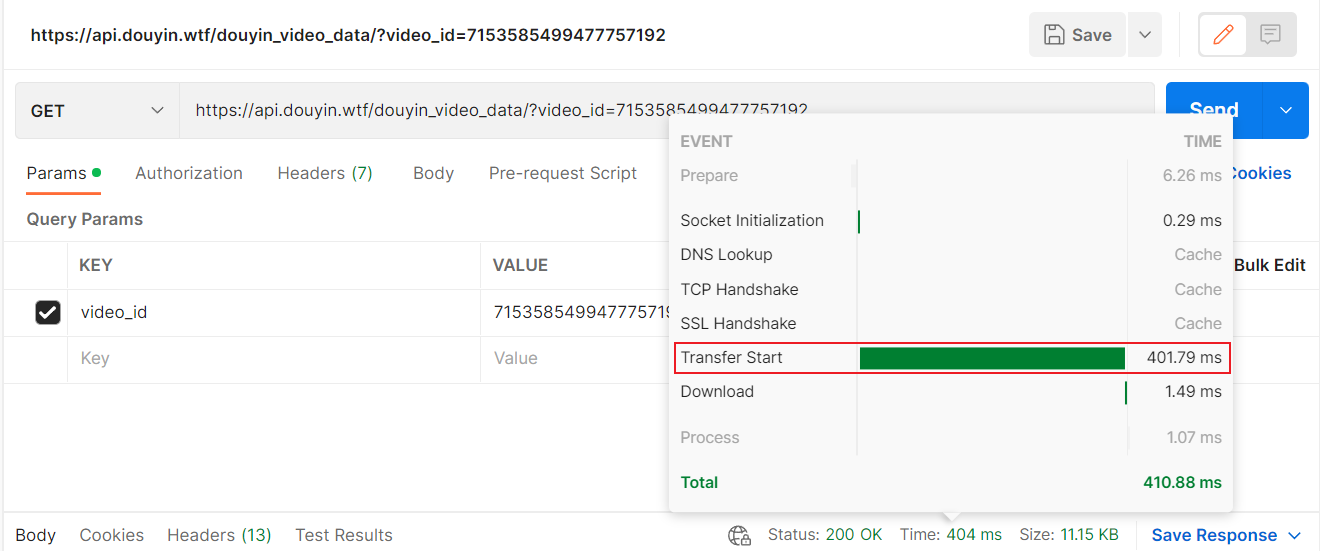
|
This project API:
|
||||||
|
|
||||||
TikTok官方API:
|
TikTok official API:
|
||||||
|
|
||||||
API of this project:
|
This project API:
|
||||||
|
|
||||||
</details>
|
</details>
|
||||||
<hr>
|
<hr>
|
||||||
@ -474,4 +477,4 @@ Web main interface:
|
|||||||
|
|
||||||
> Start: 2021/11/06
|
> Start: 2021/11/06
|
||||||
|
|
||||||
> GitHub:[@Evil0ctal](https://github.com/Evil0ctal)
|
> Githubub:[@Evil0ctal](https://github.com/Evil0ctal)
|
||||||
|
|||||||
36
README.md
36
README.md
@ -36,28 +36,27 @@
|
|||||||
这些赞助商已付费放置在这里,**Douyin_TikTok_Download_API** 项目将永远免费且开源。如果您希望成为该项目的赞助商,请查看我的 [GitHub 赞助商页面](https://github.com/sponsors/evil0ctal)。
|
这些赞助商已付费放置在这里,**Douyin_TikTok_Download_API** 项目将永远免费且开源。如果您希望成为该项目的赞助商,请查看我的 [GitHub 赞助商页面](https://github.com/sponsors/evil0ctal)。
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<hr>
|
|
||||||
<br>
|
|
||||||
<a href="https://www.tikhub.io/" target="_blank">
|
<a href="https://www.tikhub.io/" target="_blank">
|
||||||
<img src="https://tikhub.io/wp-content/uploads/2024/06/cropped-Logo_TikHub-60-300x300px.png" width="100" alt="TikHub.io API Marketplace">
|
<img src="https://tikhub.io/wp-content/uploads/2024/11/Main-Logo.webp" width="100" alt="TikHub.io - Global Social Data & API Marketplace">
|
||||||
<b></b>
|
|
||||||
<div>
|
|
||||||
<b>TikHub.io API:</b> is the leading API provider for scraping Douyin, Xiaohongshu, TikTok, Instagram, Youtube, and more. <br> Trusted by the major influencer marketing and social media listening platforms.
|
|
||||||
</div>
|
|
||||||
</a>
|
</a>
|
||||||
<br/>
|
|
||||||
<a href="https://www.sadcaptcha.com?ref=eviloctal" target="_blank">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktok3d.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktokrotate.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktokpuzzle.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<img src="https://sadcaptcha.b-cdn.net/tiktokicon.webp" width="100" alt="TikTok Captcha Solver">
|
|
||||||
<br/>
|
|
||||||
<div>
|
<div>
|
||||||
<b>TikTok Captcha Solver: </b> Bypass any TikTok captcha in just two lines of code.<br> Scale your TikTok automation and get unblocked with SadCaptcha.
|
<h2><b>TikHub.io</b></h2>
|
||||||
|
<p>Your Ultimate Social Media Data & API Marketplace</p>
|
||||||
|
<p>
|
||||||
|
Professional data solutions for Douyin, Xiaohongshu, TikTok, Instagram, YouTube,
|
||||||
|
Twitter, and more.<br>
|
||||||
|
Real-time Data | Flexible APIs | Seamless Integration | Competitive Pricing with Discounts
|
||||||
|
</p>
|
||||||
|
<p>
|
||||||
|
<b>Discover TikHub.io Marketplace</b><br>
|
||||||
|
Buy and sell custom APIs, services, and social media solutions.<br>
|
||||||
|
Join a thriving ecosystem of developers, businesses, and content creators.
|
||||||
|
</p>
|
||||||
|
<p><em>Trusted by leading global influencer marketing and social media intelligence platforms</em></p>
|
||||||
</div>
|
</div>
|
||||||
</a>
|
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|
||||||
## 👻介绍
|
## 👻介绍
|
||||||
|
|
||||||
> 🚨如需使用私有服务器运行本项目,请参考:[部署准备工作](./README.md#%EF%B8%8F%E9%83%A8%E7%BD%B2%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C%E8%AF%B7%E4%BB%94%E7%BB%86%E9%98%85%E8%AF%BB), [Docker部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker), [一键部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-linux)
|
> 🚨如需使用私有服务器运行本项目,请参考:[部署准备工作](./README.md#%EF%B8%8F%E9%83%A8%E7%BD%B2%E5%89%8D%E7%9A%84%E5%87%86%E5%A4%87%E5%B7%A5%E4%BD%9C%E8%AF%B7%E4%BB%94%E7%BB%86%E9%98%85%E8%AF%BB), [Docker部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker), [一键部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-linux)
|
||||||
@ -223,6 +222,7 @@ TikHub的部分源代码会开源在Github上,并且会赞助一些开源项
|
|||||||
- [x] 获取列表unique_id
|
- [x] 获取列表unique_id
|
||||||
- 哔哩哔哩网页版API
|
- 哔哩哔哩网页版API
|
||||||
- [x] 获取单个视频详情信息
|
- [x] 获取单个视频详情信息
|
||||||
|
- [x] 获取视频流地址
|
||||||
- [x] 获取用户发布视频作品数据
|
- [x] 获取用户发布视频作品数据
|
||||||
- [x] 获取用户所有收藏夹信息
|
- [x] 获取用户所有收藏夹信息
|
||||||
- [x] 获取指定收藏夹内视频数据
|
- [x] 获取指定收藏夹内视频数据
|
||||||
@ -231,8 +231,12 @@ TikHub的部分源代码会开源在Github上,并且会赞助一些开源项
|
|||||||
- [x] 获取指定视频的评论
|
- [x] 获取指定视频的评论
|
||||||
- [x] 获取视频下指定评论的回复
|
- [x] 获取视频下指定评论的回复
|
||||||
- [x] 获取指定用户动态
|
- [x] 获取指定用户动态
|
||||||
|
- [x] 获取视频实时弹幕
|
||||||
- [x] 获取指定直播间信息
|
- [x] 获取指定直播间信息
|
||||||
|
- [x] 获取直播间视频流
|
||||||
|
- [x] 获取指定分区正在直播的主播
|
||||||
- [x] 获取所有直播分区列表
|
- [x] 获取所有直播分区列表
|
||||||
|
- [x] 通过bv号获得视频分p信息
|
||||||
---
|
---
|
||||||
|
|
||||||
## 📦调用解析库(已废弃需要更新):
|
## 📦调用解析库(已废弃需要更新):
|
||||||
|
|||||||
@ -46,6 +46,48 @@ async def fetch_one_video(request: Request,
|
|||||||
raise HTTPException(status_code=status_code, detail=detail.dict())
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
|
# 获取视频流地址
|
||||||
|
@router.get("/fetch_video_playurl", response_model=ResponseModel, summary="获取视频流地址/Get video playurl")
|
||||||
|
async def fetch_one_video(request: Request,
|
||||||
|
bv_id: str = Query(example="BV1y7411Q7Eq", description="作品id/Video id"),
|
||||||
|
cid:str = Query(example="171776208", description="作品cid/Video cid")):
|
||||||
|
"""
|
||||||
|
# [中文]
|
||||||
|
### 用途:
|
||||||
|
- 获取视频流地址
|
||||||
|
### 参数:
|
||||||
|
- bv_id: 作品id
|
||||||
|
- cid: 作品cid
|
||||||
|
### 返回:
|
||||||
|
- 视频流地址
|
||||||
|
|
||||||
|
# [English]
|
||||||
|
### Purpose:
|
||||||
|
- Get video playurl
|
||||||
|
### Parameters:
|
||||||
|
- bv_id: Video id
|
||||||
|
- cid: Video cid
|
||||||
|
### Return:
|
||||||
|
- Video playurl
|
||||||
|
|
||||||
|
# [示例/Example]
|
||||||
|
bv_id = "BV1y7411Q7Eq"
|
||||||
|
cid = "171776208"
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
data = await BilibiliWebCrawler.fetch_video_playurl(bv_id, cid)
|
||||||
|
return ResponseModel(code=200,
|
||||||
|
router=request.url.path,
|
||||||
|
data=data)
|
||||||
|
except Exception as e:
|
||||||
|
status_code = 400
|
||||||
|
detail = ErrorResponseModel(code=status_code,
|
||||||
|
router=request.url.path,
|
||||||
|
params=dict(request.query_params),
|
||||||
|
)
|
||||||
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
# 获取用户发布视频作品数据
|
# 获取用户发布视频作品数据
|
||||||
@router.get("/fetch_user_post_videos", response_model=ResponseModel,
|
@router.get("/fetch_user_post_videos", response_model=ResponseModel,
|
||||||
summary="获取用户主页作品数据/Get user homepage video data")
|
summary="获取用户主页作品数据/Get user homepage video data")
|
||||||
@ -385,6 +427,44 @@ async def fetch_collect_folders(request: Request,
|
|||||||
raise HTTPException(status_code=status_code, detail=detail.dict())
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
|
# 获取视频实时弹幕
|
||||||
|
@router.get("/fetch_video_danmaku", response_model=ResponseModel, summary="获取视频实时弹幕/Get Video Danmaku")
|
||||||
|
async def fetch_one_video(request: Request,
|
||||||
|
cid: str = Query(example="1639235405", description="作品cid/Video cid")):
|
||||||
|
"""
|
||||||
|
# [中文]
|
||||||
|
### 用途:
|
||||||
|
- 获取视频实时弹幕
|
||||||
|
### 参数:
|
||||||
|
- cid: 作品cid
|
||||||
|
### 返回:
|
||||||
|
- 视频实时弹幕
|
||||||
|
|
||||||
|
# [English]
|
||||||
|
### Purpose:
|
||||||
|
- Get Video Danmaku
|
||||||
|
### Parameters:
|
||||||
|
- cid: Video cid
|
||||||
|
### Return:
|
||||||
|
- Video Danmaku
|
||||||
|
|
||||||
|
# [示例/Example]
|
||||||
|
cid = "1639235405"
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
data = await BilibiliWebCrawler.fetch_video_danmaku(cid)
|
||||||
|
return ResponseModel(code=200,
|
||||||
|
router=request.url.path,
|
||||||
|
data=data)
|
||||||
|
except Exception as e:
|
||||||
|
status_code = 400
|
||||||
|
detail = ErrorResponseModel(code=status_code,
|
||||||
|
router=request.url.path,
|
||||||
|
params=dict(request.query_params),
|
||||||
|
)
|
||||||
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
# 获取指定直播间信息
|
# 获取指定直播间信息
|
||||||
@router.get("/fetch_live_room_detail", response_model=ResponseModel,
|
@router.get("/fetch_live_room_detail", response_model=ResponseModel,
|
||||||
summary="获取指定直播间信息/Get information of specified live room")
|
summary="获取指定直播间信息/Get information of specified live room")
|
||||||
@ -424,43 +504,86 @@ async def fetch_collect_folders(request: Request,
|
|||||||
raise HTTPException(status_code=status_code, detail=detail.dict())
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
# # 获取指定直播间视频流
|
# 获取指定直播间视频流
|
||||||
# @router.get("/fetch_live_videos", response_model=ResponseModel,
|
@router.get("/fetch_live_videos", response_model=ResponseModel,
|
||||||
# summary="获取直播间视频流/Get live video data of specified room")
|
summary="获取直播间视频流/Get live video data of specified room")
|
||||||
# async def fetch_collect_folders(request: Request,
|
async def fetch_collect_folders(request: Request,
|
||||||
# room_id: str = Query(example="22816111", description="直播间ID/Live room ID")):
|
room_id: str = Query(example="1815229528", description="直播间ID/Live room ID")):
|
||||||
# """
|
"""
|
||||||
# # [中文]
|
# [中文]
|
||||||
# ### 用途:
|
### 用途:
|
||||||
# - 获取指定直播间视频流
|
- 获取指定直播间视频流
|
||||||
# ### 参数:
|
### 参数:
|
||||||
# - room_id: 直播间ID
|
- room_id: 直播间ID
|
||||||
# ### 返回:
|
### 返回:
|
||||||
# - 指定直播间视频流
|
- 指定直播间视频流
|
||||||
#
|
|
||||||
# # [English]
|
# [English]
|
||||||
# ### Purpose:
|
### Purpose:
|
||||||
# - Get live video data of specified room
|
- Get live video data of specified room
|
||||||
# ### Parameters:
|
### Parameters:
|
||||||
# - room_id: Live room ID
|
- room_id: Live room ID
|
||||||
# ### Return:
|
### Return:
|
||||||
# - live video data of specified room
|
- live video data of specified room
|
||||||
#
|
|
||||||
# # [示例/Example]
|
# [示例/Example]
|
||||||
# room_id = "22816111"
|
room_id = "1815229528"
|
||||||
# """
|
"""
|
||||||
# try:
|
try:
|
||||||
# data = await BilibiliWebCrawler.fetch_live_videos(room_id)
|
data = await BilibiliWebCrawler.fetch_live_videos(room_id)
|
||||||
# return ResponseModel(code=200,
|
return ResponseModel(code=200,
|
||||||
# router=request.url.path,
|
router=request.url.path,
|
||||||
# data=data)
|
data=data)
|
||||||
# except Exception as e:
|
except Exception as e:
|
||||||
# status_code = 400
|
status_code = 400
|
||||||
# detail = ErrorResponseModel(code=status_code,
|
detail = ErrorResponseModel(code=status_code,
|
||||||
# router=request.url.path,
|
router=request.url.path,
|
||||||
# params=dict(request.query_params),
|
params=dict(request.query_params),
|
||||||
# )
|
)
|
||||||
# raise HTTPException(status_code=status_code, detail=detail.dict())
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
|
# 获取指定分区正在直播的主播
|
||||||
|
@router.get("/fetch_live_streamers", response_model=ResponseModel,
|
||||||
|
summary="获取指定分区正在直播的主播/Get live streamers of specified live area")
|
||||||
|
async def fetch_collect_folders(request: Request,
|
||||||
|
area_id: str = Query(example="9", description="直播分区id/Live area ID"),
|
||||||
|
pn: int = Query(default=1, description="页码/Page number")):
|
||||||
|
"""
|
||||||
|
# [中文]
|
||||||
|
### 用途:
|
||||||
|
- 获取指定分区正在直播的主播
|
||||||
|
### 参数:
|
||||||
|
- area_id: 直播分区id
|
||||||
|
- pn: 页码
|
||||||
|
### 返回:
|
||||||
|
- 指定分区正在直播的主播
|
||||||
|
|
||||||
|
# [English]
|
||||||
|
### Purpose:
|
||||||
|
- Get live streamers of specified live area
|
||||||
|
### Parameters:
|
||||||
|
- area_id: Live area ID
|
||||||
|
- pn: Page number
|
||||||
|
### Return:
|
||||||
|
- live streamers of specified live area
|
||||||
|
|
||||||
|
# [示例/Example]
|
||||||
|
area_id = "9"
|
||||||
|
pn = 1
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
data = await BilibiliWebCrawler.fetch_live_streamers(area_id, pn)
|
||||||
|
return ResponseModel(code=200,
|
||||||
|
router=request.url.path,
|
||||||
|
data=data)
|
||||||
|
except Exception as e:
|
||||||
|
status_code = 400
|
||||||
|
detail = ErrorResponseModel(code=status_code,
|
||||||
|
router=request.url.path,
|
||||||
|
params=dict(request.query_params),
|
||||||
|
)
|
||||||
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
# 获取所有直播分区列表
|
# 获取所有直播分区列表
|
||||||
@ -496,3 +619,79 @@ async def fetch_collect_folders(request: Request,):
|
|||||||
params=dict(request.query_params),
|
params=dict(request.query_params),
|
||||||
)
|
)
|
||||||
raise HTTPException(status_code=status_code, detail=detail.dict())
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
|
# 通过bv号获得视频aid号
|
||||||
|
@router.get("/bv_to_aid", response_model=ResponseModel, summary="通过bv号获得视频aid号/Generate aid by bvid")
|
||||||
|
async def fetch_one_video(request: Request,
|
||||||
|
bv_id: str = Query(example="BV1M1421t7hT", description="作品id/Video id")):
|
||||||
|
"""
|
||||||
|
# [中文]
|
||||||
|
### 用途:
|
||||||
|
- 通过bv号获得视频aid号
|
||||||
|
### 参数:
|
||||||
|
- bv_id: 作品id
|
||||||
|
### 返回:
|
||||||
|
- 视频aid号
|
||||||
|
|
||||||
|
# [English]
|
||||||
|
### Purpose:
|
||||||
|
- Generate aid by bvid
|
||||||
|
### Parameters:
|
||||||
|
- bv_id: Video id
|
||||||
|
### Return:
|
||||||
|
- Video aid
|
||||||
|
|
||||||
|
# [示例/Example]
|
||||||
|
bv_id = "BV1M1421t7hT"
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
data = await BilibiliWebCrawler.bv_to_aid(bv_id)
|
||||||
|
return ResponseModel(code=200,
|
||||||
|
router=request.url.path,
|
||||||
|
data=data)
|
||||||
|
except Exception as e:
|
||||||
|
status_code = 400
|
||||||
|
detail = ErrorResponseModel(code=status_code,
|
||||||
|
router=request.url.path,
|
||||||
|
params=dict(request.query_params),
|
||||||
|
)
|
||||||
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|
||||||
|
|
||||||
|
# 通过bv号获得视频分p信息
|
||||||
|
@router.get("/fetch_video_parts", response_model=ResponseModel, summary="通过bv号获得视频分p信息/Get Video Parts By bvid")
|
||||||
|
async def fetch_one_video(request: Request,
|
||||||
|
bv_id: str = Query(example="BV1vf421i7hV", description="作品id/Video id")):
|
||||||
|
"""
|
||||||
|
# [中文]
|
||||||
|
### 用途:
|
||||||
|
- 通过bv号获得视频分p信息
|
||||||
|
### 参数:
|
||||||
|
- bv_id: 作品id
|
||||||
|
### 返回:
|
||||||
|
- 视频分p信息
|
||||||
|
|
||||||
|
# [English]
|
||||||
|
### Purpose:
|
||||||
|
- Get Video Parts By bvid
|
||||||
|
### Parameters:
|
||||||
|
- bv_id: Video id
|
||||||
|
### Return:
|
||||||
|
- Video Parts
|
||||||
|
|
||||||
|
# [示例/Example]
|
||||||
|
bv_id = "BV1vf421i7hV"
|
||||||
|
"""
|
||||||
|
try:
|
||||||
|
data = await BilibiliWebCrawler.fetch_video_parts(bv_id)
|
||||||
|
return ResponseModel(code=200,
|
||||||
|
router=request.url.path,
|
||||||
|
data=data)
|
||||||
|
except Exception as e:
|
||||||
|
status_code = 400
|
||||||
|
detail = ErrorResponseModel(code=status_code,
|
||||||
|
router=request.url.path,
|
||||||
|
params=dict(request.query_params),
|
||||||
|
)
|
||||||
|
raise HTTPException(status_code=status_code, detail=detail.dict())
|
||||||
|
|||||||
@ -4,7 +4,7 @@ import zipfile
|
|||||||
import aiofiles
|
import aiofiles
|
||||||
import httpx
|
import httpx
|
||||||
import yaml
|
import yaml
|
||||||
from fastapi import APIRouter, Request, Query # 导入FastAPI组件
|
from fastapi import APIRouter, Request, Query, HTTPException # 导入FastAPI组件
|
||||||
from starlette.responses import FileResponse
|
from starlette.responses import FileResponse
|
||||||
|
|
||||||
from app.api.models.APIResponseModel import ErrorResponseModel # 导入响应模型
|
from app.api.models.APIResponseModel import ErrorResponseModel # 导入响应模型
|
||||||
@ -18,7 +18,6 @@ config_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(os.pa
|
|||||||
with open(config_path, 'r', encoding='utf-8') as file:
|
with open(config_path, 'r', encoding='utf-8') as file:
|
||||||
config = yaml.safe_load(file)
|
config = yaml.safe_load(file)
|
||||||
|
|
||||||
|
|
||||||
async def fetch_data(url: str, headers: dict = None):
|
async def fetch_data(url: str, headers: dict = None):
|
||||||
headers = {
|
headers = {
|
||||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
|
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
|
||||||
@ -28,6 +27,26 @@ async def fetch_data(url: str, headers: dict = None):
|
|||||||
response.raise_for_status() # 确保响应是成功的
|
response.raise_for_status() # 确保响应是成功的
|
||||||
return response
|
return response
|
||||||
|
|
||||||
|
# 下载视频专用
|
||||||
|
async def fetch_data_stream(url: str, request:Request , headers: dict = None, file_path: str = None):
|
||||||
|
headers = {
|
||||||
|
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
|
||||||
|
} if headers is None else headers.get('headers')
|
||||||
|
async with httpx.AsyncClient() as client:
|
||||||
|
# 启用流式请求
|
||||||
|
async with client.stream("GET", url, headers=headers) as response:
|
||||||
|
response.raise_for_status()
|
||||||
|
|
||||||
|
# 流式保存文件
|
||||||
|
async with aiofiles.open(file_path, 'wb') as out_file:
|
||||||
|
async for chunk in response.aiter_bytes():
|
||||||
|
if await request.is_disconnected():
|
||||||
|
print("客户端断开连接,清理未完成的文件")
|
||||||
|
await out_file.close()
|
||||||
|
os.remove(file_path)
|
||||||
|
return False
|
||||||
|
await out_file.write(chunk)
|
||||||
|
return True
|
||||||
|
|
||||||
@router.get("/download", summary="在线下载抖音|TikTok视频/图片/Online download Douyin|TikTok video/image")
|
@router.get("/download", summary="在线下载抖音|TikTok视频/图片/Online download Douyin|TikTok video/image")
|
||||||
async def download_file_hybrid(request: Request,
|
async def download_file_hybrid(request: Request,
|
||||||
@ -104,11 +123,18 @@ async def download_file_hybrid(request: Request,
|
|||||||
|
|
||||||
# 获取视频文件
|
# 获取视频文件
|
||||||
__headers = await HybridCrawler.TikTokWebCrawler.get_tiktok_headers() if platform == 'tiktok' else await HybridCrawler.DouyinWebCrawler.get_douyin_headers()
|
__headers = await HybridCrawler.TikTokWebCrawler.get_tiktok_headers() if platform == 'tiktok' else await HybridCrawler.DouyinWebCrawler.get_douyin_headers()
|
||||||
response = await fetch_data(url, headers=__headers)
|
# response = await fetch_data(url, headers=__headers)
|
||||||
|
|
||||||
# 保存文件
|
success = await fetch_data_stream(url, request, headers=__headers, file_path=file_path)
|
||||||
async with aiofiles.open(file_path, 'wb') as out_file:
|
if not success:
|
||||||
await out_file.write(response.content)
|
raise HTTPException(
|
||||||
|
status_code=500,
|
||||||
|
detail="An error occurred while fetching data"
|
||||||
|
)
|
||||||
|
|
||||||
|
# # 保存文件
|
||||||
|
# async with aiofiles.open(file_path, 'wb') as out_file:
|
||||||
|
# await out_file.write(response.content)
|
||||||
|
|
||||||
# 返回文件内容
|
# 返回文件内容
|
||||||
return FileResponse(path=file_path, filename=file_name, media_type="video/mp4")
|
return FileResponse(path=file_path, filename=file_name, media_type="video/mp4")
|
||||||
|
|||||||
@ -145,12 +145,15 @@ def parse_video():
|
|||||||
# 如果是视频/If it's video
|
# 如果是视频/If it's video
|
||||||
if url_type == ViewsUtils.t('视频', 'Video'):
|
if url_type == ViewsUtils.t('视频', 'Video'):
|
||||||
# 添加视频信息
|
# 添加视频信息
|
||||||
table_list.insert(4, [ViewsUtils.t('视频链接-水印', 'Video URL-Watermark'),
|
wm_video_url_HQ = data.get('video_data').get('wm_video_url_HQ')
|
||||||
put_link(ViewsUtils.t('点击查看', 'Click to view'),
|
nwm_video_url_HQ = data.get('video_data').get('nwm_video_url_HQ')
|
||||||
data.get('video_data').get('wm_video_url_HQ'), new_window=True)])
|
if wm_video_url_HQ and nwm_video_url_HQ:
|
||||||
table_list.insert(5, [ViewsUtils.t('视频链接-无水印', 'Video URL-No Watermark'),
|
table_list.insert(4, [ViewsUtils.t('视频链接-水印', 'Video URL-Watermark'),
|
||||||
put_link(ViewsUtils.t('点击查看', 'Click to view'),
|
put_link(ViewsUtils.t('点击查看', 'Click to view'),
|
||||||
data.get('video_data').get('nwm_video_url_HQ'), new_window=True)])
|
wm_video_url_HQ, new_window=True)])
|
||||||
|
table_list.insert(5, [ViewsUtils.t('视频链接-无水印', 'Video URL-No Watermark'),
|
||||||
|
put_link(ViewsUtils.t('点击查看', 'Click to view'),
|
||||||
|
nwm_video_url_HQ, new_window=True)])
|
||||||
table_list.insert(6, [ViewsUtils.t('视频下载-水印', 'Video Download-Watermark'),
|
table_list.insert(6, [ViewsUtils.t('视频下载-水印', 'Video Download-Watermark'),
|
||||||
put_link(ViewsUtils.t('点击下载', 'Click to download'),
|
put_link(ViewsUtils.t('点击下载', 'Click to download'),
|
||||||
f"/api/download?url={url}&prefix=true&with_watermark=true",
|
f"/api/download?url={url}&prefix=true&with_watermark=true",
|
||||||
|
|||||||
@ -30,8 +30,8 @@ API:
|
|||||||
Redoc_URL: /redoc # API documentation URL | API文档URL
|
Redoc_URL: /redoc # API documentation URL | API文档URL
|
||||||
|
|
||||||
# API Information
|
# API Information
|
||||||
Version: V4.0.7 # API version | API版本
|
Version: V4.1.2 # API version | API版本
|
||||||
Update_Time: 2024/09/14 # API update time | API更新时间
|
Update_Time: 2025/03/16 # API update time | API更新时间
|
||||||
Environment: Demo # API environment | API环境
|
Environment: Demo # API environment | API环境
|
||||||
|
|
||||||
# Download Configuration
|
# Download Configuration
|
||||||
|
|||||||
@ -5,7 +5,7 @@ TokenManager:
|
|||||||
'origin': https://www.bilibili.com
|
'origin': https://www.bilibili.com
|
||||||
'referer': https://space.bilibili.com/
|
'referer': https://space.bilibili.com/
|
||||||
'origin_2': https://space.bilibili.com
|
'origin_2': https://space.bilibili.com
|
||||||
'cookie': buvid3=D6E58E7B-E3A9-7CD3-7BE5-B5F255788A3020034infoc; b_nut=1723702120; _uuid=6E10D69A10-A711-9DA8-6833-1010262296C24B21337infoc; buvid_fp=6cf2ea8e143bbc49f3b7c0dcb2465fc2; buvid4=748EC8F0-82E2-1672-A286-8445DDB2A80C06110-023112304-; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MjM5NjEzMjIsImlhdCI6MTcyMzcwMjA2MiwicGx0IjotMX0.IWOEMLCDKqWAX24rePU-1Qgm9Isf5CU8Tz0O-j6GHfo; bili_ticket_expires=1723961262; CURRENT_FNVAL=4048; rpdid=|(JluY|JJ|RR0J'u~kJ~|kkuY; b_lsid=E10B83DC4_191552166D6; header_theme_version=CLOSE; enable_web_push=DISABLE; home_feed_column=5; browser_resolution=1488-714; sid=873ujj7i
|
'cookie': buvid4=748EC8F0-82E2-1672-A286-8445DDB2A80C06110-023112304-; buvid3=73EF1E2E-B7A9-78DD-F2AE-9AB2B476E27638524infoc; b_nut=1727075638; _uuid=77AA4910F-5C8F-9647-7DA3-F583C8108BD7942063infoc; buvid_fp=75b22e5d0c3dbc642b1c80956c62c7da; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MjczNDI1NTYsImlhdCI6MTcyNzA4MzI5NiwicGx0IjotMX0.G3pvk6OC4FDWBL7GNgKkkVtUMl29UtNdgok_cANoKsw; bili_ticket_expires=1727342496; header_theme_version=CLOSE; enable_web_push=DISABLE; home_feed_column=5; browser_resolution=1488-712; b_lsid=5B4EDF8A_1921EAA1BDA
|
||||||
'user-agent': Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
|
'user-agent': Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
|
||||||
|
|
||||||
proxies:
|
proxies:
|
||||||
|
|||||||
@ -11,8 +11,11 @@ class BilibiliAPIEndpoints:
|
|||||||
# 作品信息 (Post Detail)
|
# 作品信息 (Post Detail)
|
||||||
POST_DETAIL = f"{BILIAPI_DOMAIN}/x/web-interface/view"
|
POST_DETAIL = f"{BILIAPI_DOMAIN}/x/web-interface/view"
|
||||||
|
|
||||||
# 用户播放列表 (用于爬取用户所有视频数据)
|
# 作品视频流
|
||||||
USER_POST = f"{BILIAPI_DOMAIN}/x/v2/medialist/resource/list"
|
VIDEO_PLAYURL = f"{BILIAPI_DOMAIN}/x/player/wbi/playurl"
|
||||||
|
|
||||||
|
# 用户发布视频作品数据
|
||||||
|
USER_POST = f"{BILIAPI_DOMAIN}/x/space/wbi/arc/search"
|
||||||
|
|
||||||
# 收藏夹列表
|
# 收藏夹列表
|
||||||
COLLECT_FOLDERS = f"{BILIAPI_DOMAIN}/x/v3/fav/folder/created/list-all"
|
COLLECT_FOLDERS = f"{BILIAPI_DOMAIN}/x/v3/fav/folder/created/list-all"
|
||||||
@ -35,9 +38,15 @@ class BilibiliAPIEndpoints:
|
|||||||
# 视频评论
|
# 视频评论
|
||||||
VIDEO_COMMENTS = f"{BILIAPI_DOMAIN}/x/v2/reply"
|
VIDEO_COMMENTS = f"{BILIAPI_DOMAIN}/x/v2/reply"
|
||||||
|
|
||||||
|
# 用户动态
|
||||||
|
USER_DYNAMIC = f"{BILIAPI_DOMAIN}/x/polymer/web-dynamic/v1/feed/space"
|
||||||
|
|
||||||
# 评论的回复
|
# 评论的回复
|
||||||
COMMENT_REPLY = f"{BILIAPI_DOMAIN}/x/v2/reply/reply"
|
COMMENT_REPLY = f"{BILIAPI_DOMAIN}/x/v2/reply/reply"
|
||||||
|
|
||||||
|
# 视频分p信息
|
||||||
|
VIDEO_PARTS = f"{BILIAPI_DOMAIN}/x/player/pagelist"
|
||||||
|
|
||||||
# 直播间信息
|
# 直播间信息
|
||||||
LIVEROOM_DETAIL = f"{LIVE_DOMAIN}/room/v1/Room/get_info"
|
LIVEROOM_DETAIL = f"{LIVE_DOMAIN}/room/v1/Room/get_info"
|
||||||
|
|
||||||
@ -47,4 +56,7 @@ class BilibiliAPIEndpoints:
|
|||||||
# 直播间视频流
|
# 直播间视频流
|
||||||
LIVE_VIDEOS = f"{LIVE_DOMAIN}/room/v1/Room/playUrl"
|
LIVE_VIDEOS = f"{LIVE_DOMAIN}/room/v1/Room/playUrl"
|
||||||
|
|
||||||
|
# 正在直播的主播
|
||||||
|
LIVE_STREAMER = f"{LIVE_DOMAIN}/xlive/web-interface/v1/second/getList"
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
39
crawlers/bilibili/web/models.py
Normal file
39
crawlers/bilibili/web/models.py
Normal file
@ -0,0 +1,39 @@
|
|||||||
|
import time
|
||||||
|
from pydantic import BaseModel
|
||||||
|
|
||||||
|
|
||||||
|
class BaseRequestsModel(BaseModel):
|
||||||
|
wts: str = str(round(time.time()))
|
||||||
|
|
||||||
|
|
||||||
|
class UserPostVideos(BaseRequestsModel):
|
||||||
|
dm_img_inter: str = '{"ds":[],"wh":[3557,5674,5],"of":[154,308,154]}'
|
||||||
|
dm_img_list: list = []
|
||||||
|
mid: str
|
||||||
|
pn: int
|
||||||
|
ps: str = "20"
|
||||||
|
|
||||||
|
|
||||||
|
class UserProfile(BaseRequestsModel):
|
||||||
|
mid: str
|
||||||
|
|
||||||
|
|
||||||
|
class UserDynamic(BaseRequestsModel):
|
||||||
|
host_mid: str
|
||||||
|
offset: str
|
||||||
|
wts: str = str(round(time.time()))
|
||||||
|
|
||||||
|
|
||||||
|
class ComPopular(BaseRequestsModel):
|
||||||
|
pn: int
|
||||||
|
ps: str = "20"
|
||||||
|
web_location: str = "333.934"
|
||||||
|
|
||||||
|
|
||||||
|
class PlayUrl(BaseRequestsModel):
|
||||||
|
qn: str
|
||||||
|
fnval: str = '4048'
|
||||||
|
bvid: str
|
||||||
|
cid: str
|
||||||
|
|
||||||
|
|
||||||
@ -1,159 +1,58 @@
|
|||||||
import time
|
|
||||||
from urllib.parse import urlencode
|
from urllib.parse import urlencode
|
||||||
import random
|
|
||||||
from crawlers.bilibili.web import wrid
|
from crawlers.bilibili.web import wrid
|
||||||
from crawlers.utils.logger import logger
|
from crawlers.utils.logger import logger
|
||||||
|
from crawlers.bilibili.web.endpoints import BilibiliAPIEndpoints
|
||||||
|
|
||||||
# 装饰器 检查是否正确生成endpoint
|
|
||||||
def Check_gen(func):
|
|
||||||
def checker(*args, **kwargs):
|
|
||||||
try:
|
|
||||||
result = func(*args, **kwargs)
|
|
||||||
return result
|
|
||||||
except Exception as e:
|
|
||||||
raise RuntimeError("生成w_rid失败:{0}, 函数地址:{1}".format(e, func.__name__))
|
|
||||||
|
|
||||||
return checker
|
class EndpointGenerator:
|
||||||
|
def __init__(self, params: dict):
|
||||||
class EndpointModels:
|
self.params = params
|
||||||
def __init__(self):
|
|
||||||
# 实例化WridManager
|
|
||||||
self.wridmanager = WridManager()
|
|
||||||
# 当前时间戳
|
|
||||||
self.wts = round(time.time())
|
|
||||||
# 固定inter也能获得结果。如果失效见--WridManager().get_inter
|
|
||||||
self.inter = '{"ds":[],"wh":[3557,5674,5],"of":[154,308,154]}'
|
|
||||||
|
|
||||||
# 获取wrid示例 通过uid 生成包含w_rid和wts的字典
|
|
||||||
@Check_gen
|
|
||||||
async def get_wrid_wts_by_uid(self, uid: str) -> dict:
|
|
||||||
params = {
|
|
||||||
'dm_cover_img_str': 'QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ',
|
|
||||||
'dm_img_inter': self.inter,
|
|
||||||
'dm_img_list': [],
|
|
||||||
'dm_img_str': 'V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ',
|
|
||||||
'mid': uid,
|
|
||||||
'platform': 'web',
|
|
||||||
'token': '',
|
|
||||||
'web_location': '1550101',
|
|
||||||
'wts': f'{self.wts}ea1db124af3c7062474693fa704f4ff8'
|
|
||||||
}
|
|
||||||
# 获取w_rid参数
|
|
||||||
w_rid = await self.wridmanager.get_wrid(params=params)
|
|
||||||
reslut = {
|
|
||||||
"w_rid": w_rid,
|
|
||||||
"wts": self.wts
|
|
||||||
}
|
|
||||||
return reslut
|
|
||||||
|
|
||||||
# 获取用户发布视频作品数据 生成enpoint
|
# 获取用户发布视频作品数据 生成enpoint
|
||||||
@Check_gen
|
async def user_post_videos_endpoint(self) -> str:
|
||||||
async def user_post_videos_endpoint(self, uid: str, pn: int, ps: int = 30) -> str:
|
# 添加w_rid
|
||||||
# 编码inter
|
endpoint = await WridManager.wrid_model_endpoint(params=self.params)
|
||||||
new_inter = self.inter.replace(" ", "").replace('{', "%7B").replace("'", "%22").replace("}", "%7D")
|
# 拼接成最终结果并返回
|
||||||
# 构建请求参数
|
final_endpoint = BilibiliAPIEndpoints.USER_POST + '?' + endpoint
|
||||||
params = {
|
return final_endpoint
|
||||||
"dm_cover_img_str": "QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ",
|
|
||||||
"dm_img_inter": self.inter,
|
# 获取视频流地址 生成enpoint
|
||||||
"dm_img_list": [],
|
async def video_playurl_endpoint(self) -> str:
|
||||||
"dm_img_str": "V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ",
|
# 添加w_rid
|
||||||
"keyword": "",
|
endpoint = await WridManager.wrid_model_endpoint(params=self.params)
|
||||||
"mid": uid,
|
# 拼接成最终结果并返回
|
||||||
"order": "pubdate",
|
final_endpoint = BilibiliAPIEndpoints.VIDEO_PLAYURL + '?' + endpoint
|
||||||
"order_avoided": "true",
|
|
||||||
"platform": "web",
|
|
||||||
"pn": pn,
|
|
||||||
"ps": ps,
|
|
||||||
"tid": "0",
|
|
||||||
"web_location": "1550101",
|
|
||||||
"wts": f"{self.wts}ea1db124af3c7062474693fa704f4ff8",
|
|
||||||
}
|
|
||||||
# 获取wrid
|
|
||||||
w_rid = await self.wridmanager.get_wrid(params=params)
|
|
||||||
# 将上面结果拼接成最终结果并返回
|
|
||||||
final_endpoint = f'https://api.bilibili.com/x/space/wbi/arc/search?mid={uid}&ps={ps}&tid=0&pn={pn}&keyword=&order=pubdate&platform=web&web_location=1550101&order_avoided=true&dm_img_list=[]&dm_img_str=V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&dm_cover_img_str=QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ&dm_img_inter={new_inter}&w_rid={w_rid}&wts={self.wts}'
|
|
||||||
return final_endpoint
|
return final_endpoint
|
||||||
|
|
||||||
# 获取指定用户的信息 生成enpoint
|
# 获取指定用户的信息 生成enpoint
|
||||||
@Check_gen
|
async def user_profile_endpoint(self) -> str:
|
||||||
async def user_profile_endpoint(self, uid: str) -> str:
|
# 添加w_rid
|
||||||
# 编码inter
|
endpoint = await WridManager.wrid_model_endpoint(params=self.params)
|
||||||
new_inter = self.inter.replace(" ", "").replace('{', "%7B").replace("'", "%22").replace("}", "%7D")
|
# 拼接成最终结果并返回
|
||||||
# 构建请求参数
|
final_endpoint = BilibiliAPIEndpoints.USER_DETAIL + '?' + endpoint
|
||||||
params = {
|
|
||||||
'dm_cover_img_str': 'QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ',
|
|
||||||
'dm_img_inter': self.inter,
|
|
||||||
'dm_img_list': [],
|
|
||||||
'dm_img_str': 'V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ',
|
|
||||||
'mid': uid,
|
|
||||||
'platform': 'web',
|
|
||||||
'token': '',
|
|
||||||
'web_location': '1550101',
|
|
||||||
'wts': f'{self.wts}ea1db124af3c7062474693fa704f4ff8'
|
|
||||||
}
|
|
||||||
# 获取wrid
|
|
||||||
w_rid = await self.wridmanager.get_wrid(params=params)
|
|
||||||
# 将上面结果拼接成最终字符串并返回
|
|
||||||
final_endpoint = f'https://api.bilibili.com/x/space/wbi/acc/info?mid={uid}&token=&platform=web&web_location=1550101&dm_img_list=[]&dm_img_str=V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&dm_cover_img_str=QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ&dm_img_inter={new_inter}&w_rid={w_rid}&wts={self.wts}'
|
|
||||||
return final_endpoint
|
return final_endpoint
|
||||||
|
|
||||||
# 获取综合热门视频信息 生成enpoint
|
# 获取综合热门视频信息 生成enpoint
|
||||||
@Check_gen
|
async def com_popular_endpoint(self) -> str:
|
||||||
async def com_popular_endpoint(self, pn: int) -> str:
|
# 添加w_rid
|
||||||
# 构建请求参数
|
endpoint = await WridManager.wrid_model_endpoint(params=self.params)
|
||||||
params = {
|
# 拼接成最终结果并返回
|
||||||
"pn": pn,
|
final_endpoint = BilibiliAPIEndpoints.COM_POPULAR + '?' + endpoint
|
||||||
"ps": "20",
|
|
||||||
"web_location": "333.934",
|
|
||||||
"wts": f"{self.wts}ea1db124af3c7062474693fa704f4ff8",
|
|
||||||
}
|
|
||||||
# 获取wrid
|
|
||||||
w_rid = await self.wridmanager.get_wrid(params=params)
|
|
||||||
# 将上面结果拼接成最终结果并返回
|
|
||||||
final_endpoint = f"https://api.bilibili.com/x/web-interface/popular?ps=20&pn={pn}&web_location=333.934&w_rid={w_rid}&wts={self.wts}"
|
|
||||||
return final_endpoint
|
return final_endpoint
|
||||||
|
|
||||||
# 获取指定用户动态
|
# 获取指定用户动态
|
||||||
@Check_gen
|
async def user_dynamic_endpoint(self):
|
||||||
async def user_dynamic_endpoint(self, uid: str, offset: str):
|
# 添加w_rid
|
||||||
# 编码inter
|
endpoint = await WridManager.wrid_model_endpoint(params=self.params)
|
||||||
new_inter = self.inter.replace(" ", "").replace('{', "%7B").replace("'", "%22").replace("}", "%7D")
|
# 拼接成最终结果并返回
|
||||||
# 构建请求参数
|
final_endpoint = BilibiliAPIEndpoints.USER_DYNAMIC + '?' + endpoint
|
||||||
params = {
|
|
||||||
"dm_cover_img_str": "QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ",
|
|
||||||
"dm_img_inter": self.inter,
|
|
||||||
"dm_img_list": [],
|
|
||||||
"dm_img_str": "V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&features=itemOpusStyle%2ClistOnlyfans%2CopusBigCover%2ConlyfansVote%2CdecorationCard%2CforwardListHidden%2CugcDelete",
|
|
||||||
"host_mid": uid,
|
|
||||||
"offset": offset,
|
|
||||||
"platform": "web",
|
|
||||||
"timezone_offset": "-480",
|
|
||||||
"web_location": "333.999",
|
|
||||||
"wts": self.wts,
|
|
||||||
"x-bili-device-req-json": "%7B%22platform%22%3A%22web%22%2C%22device%22%3A%22pc%22%7D",
|
|
||||||
"x-bili-web-req-json": "%7B%22spm_id%22%3A%22333.999%22%7Dea1db124af3c7062474693fa704f4ff8"
|
|
||||||
}
|
|
||||||
# 获取wrid
|
|
||||||
w_rid = await self.wridmanager.get_wrid(params=params)
|
|
||||||
# 将上面结果拼接成最终结果并返回
|
|
||||||
final_endpoint = f'https://api.bilibili.com/x/polymer/web-dynamic/v1/feed/space?offset={offset}&host_mid={uid}&timezone_offset=-480&platform=web&features=itemOpusStyle,listOnlyfans,opusBigCover,onlyfansVote,decorationCard,forwardListHidden,ugcDelete&web_location=333.999&dm_img_list=[]&dm_img_str=V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&dm_cover_img_str=QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ&dm_img_inter={new_inter}&x-bili-device-req-json=%7B%22platform%22:%22web%22,%22device%22:%22pc%22%7D&x-bili-web-req-json=%7B%22spm_id%22:%22333.999%22%7D&w_rid={w_rid}&wts={self.wts}'
|
|
||||||
return final_endpoint
|
return final_endpoint
|
||||||
|
|
||||||
|
|
||||||
class WridManager:
|
class WridManager:
|
||||||
|
@classmethod
|
||||||
def s(self) -> list:
|
async def get_encode_query(cls, params: dict) -> str:
|
||||||
x = random.randint(0, 113)
|
params['wts'] = params['wts'] + "ea1db124af3c7062474693fa704f4ff8"
|
||||||
return [2 * 1488 + 2 * 311 + 3 * x, 4 * 1488 - 311 + x, x]
|
|
||||||
|
|
||||||
def d(self) -> list:
|
|
||||||
x = random.randint(0, 513)
|
|
||||||
return [x, 2 * x, x]
|
|
||||||
|
|
||||||
def get_inter(self) -> dict:
|
|
||||||
return {"ds": [], "wh": self.s(), "of": self.d()}
|
|
||||||
|
|
||||||
async def get_encode_query(self, params: dict) -> str:
|
|
||||||
params = dict(sorted(params.items())) # 按照 key 重排参数
|
params = dict(sorted(params.items())) # 按照 key 重排参数
|
||||||
# 过滤 value 中的 "!'()*" 字符
|
# 过滤 value 中的 "!'()*" 字符
|
||||||
params = {
|
params = {
|
||||||
@ -164,13 +63,18 @@ class WridManager:
|
|||||||
query = urlencode(params) # 序列化参数
|
query = urlencode(params) # 序列化参数
|
||||||
return query
|
return query
|
||||||
|
|
||||||
async def get_wrid(self, params: dict) -> str:
|
@classmethod
|
||||||
encode_query = await self.get_encode_query(params)
|
async def wrid_model_endpoint(cls, params: dict) -> str:
|
||||||
|
wts = params["wts"]
|
||||||
|
encode_query = await cls.get_encode_query(params)
|
||||||
# 获取w_rid参数
|
# 获取w_rid参数
|
||||||
w_rid = wrid.get_wrid(e=encode_query)
|
w_rid = wrid.get_wrid(e=encode_query)
|
||||||
return w_rid
|
params["wts"] = wts
|
||||||
|
params["w_rid"] = w_rid
|
||||||
|
return "&".join(f"{k}={v}" for k, v in params.items())
|
||||||
|
|
||||||
async def bv2av(bv_id:str) -> int:
|
# BV号转为对应av号
|
||||||
|
async def bv2av(bv_id: str) -> int:
|
||||||
table = "fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF"
|
table = "fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF"
|
||||||
s = [11, 10, 3, 8, 4, 6, 2, 9, 5, 7]
|
s = [11, 10, 3, 8, 4, 6, 2, 9, 5, 7]
|
||||||
xor = 177451812
|
xor = 177451812
|
||||||
@ -188,7 +92,6 @@ async def bv2av(bv_id:str) -> int:
|
|||||||
aid = (r - add) ^ xor
|
aid = (r - add) ^ xor
|
||||||
return aid
|
return aid
|
||||||
|
|
||||||
|
|
||||||
# 响应分析
|
# 响应分析
|
||||||
class ResponseAnalyzer:
|
class ResponseAnalyzer:
|
||||||
# 用户收藏夹信息
|
# 用户收藏夹信息
|
||||||
|
|||||||
@ -1,3 +1,37 @@
|
|||||||
|
# ==============================================================================
|
||||||
|
# Copyright (C) 2021 Evil0ctal
|
||||||
|
#
|
||||||
|
# This file is part of the Douyin_TikTok_Download_API project.
|
||||||
|
#
|
||||||
|
# This project is licensed under the Apache License 2.0 (the "License");
|
||||||
|
# you may not use this file except in compliance with the License.
|
||||||
|
# You may obtain a copy of the License at:
|
||||||
|
# http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
#
|
||||||
|
# Unless required by applicable law or agreed to in writing, software
|
||||||
|
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
# See the License for the specific language governing permissions and
|
||||||
|
# limitations under the License.
|
||||||
|
# ==============================================================================
|
||||||
|
# __
|
||||||
|
# /> フ
|
||||||
|
# | _ _ l
|
||||||
|
# /` ミ_xノ
|
||||||
|
# / | Feed me Stars ⭐ ️
|
||||||
|
# / ヽ ノ
|
||||||
|
# │ | | |
|
||||||
|
# / ̄| | | |
|
||||||
|
# | ( ̄ヽ__ヽ_)__)
|
||||||
|
# \二つ
|
||||||
|
# ==============================================================================
|
||||||
|
#
|
||||||
|
# Contributor Link:
|
||||||
|
#
|
||||||
|
# - https://github.com/Koyomi781
|
||||||
|
#
|
||||||
|
# ==============================================================================
|
||||||
|
|
||||||
import asyncio # 异步I/O
|
import asyncio # 异步I/O
|
||||||
import os # 系统操作
|
import os # 系统操作
|
||||||
import time # 时间操作
|
import time # 时间操作
|
||||||
@ -6,10 +40,10 @@ import yaml # 配置文件
|
|||||||
# 基础爬虫客户端和哔哩哔哩API端点
|
# 基础爬虫客户端和哔哩哔哩API端点
|
||||||
from crawlers.base_crawler import BaseCrawler
|
from crawlers.base_crawler import BaseCrawler
|
||||||
from crawlers.bilibili.web.endpoints import BilibiliAPIEndpoints
|
from crawlers.bilibili.web.endpoints import BilibiliAPIEndpoints
|
||||||
|
|
||||||
# 哔哩哔哩工具类
|
# 哔哩哔哩工具类
|
||||||
from crawlers.bilibili.web.utils import EndpointModels, bv2av, ResponseAnalyzer
|
from crawlers.bilibili.web.utils import EndpointGenerator, bv2av, ResponseAnalyzer
|
||||||
|
# 数据请求模型
|
||||||
|
from crawlers.bilibili.web.models import UserPostVideos, UserProfile, ComPopular, UserDynamic, PlayUrl
|
||||||
|
|
||||||
# 配置文件路径
|
# 配置文件路径
|
||||||
path = os.path.abspath(os.path.dirname(__file__))
|
path = os.path.abspath(os.path.dirname(__file__))
|
||||||
@ -26,17 +60,18 @@ class BilibiliWebCrawler:
|
|||||||
bili_config = config['TokenManager']['bilibili']
|
bili_config = config['TokenManager']['bilibili']
|
||||||
kwargs = {
|
kwargs = {
|
||||||
"headers": {
|
"headers": {
|
||||||
"accept-language": bili_config["headers"]["accept-language"],
|
"accept-language": bili_config["headers"]["accept-language"],
|
||||||
"origin": bili_config["headers"]["origin"],
|
"origin": bili_config["headers"]["origin"],
|
||||||
"referer": bili_config["headers"]["referer"],
|
"referer": bili_config["headers"]["referer"],
|
||||||
"user-agent": bili_config["headers"]["user-agent"],
|
"user-agent": bili_config["headers"]["user-agent"],
|
||||||
"cookie": bili_config["headers"]["cookie"],
|
"cookie": bili_config["headers"]["cookie"],
|
||||||
},
|
},
|
||||||
"proxies": {"http://": bili_config["proxies"]["http"], "https://": bili_config["proxies"]["https"]},
|
"proxies": {"http://": bili_config["proxies"]["http"], "https://": bili_config["proxies"]["https"]},
|
||||||
}
|
}
|
||||||
return kwargs
|
return kwargs
|
||||||
|
|
||||||
"-------------------------------------------------------handler接口列表-------------------------------------------------------"
|
"-------------------------------------------------------handler接口列表-------------------------------------------------------"
|
||||||
|
|
||||||
# 获取单个视频详情信息
|
# 获取单个视频详情信息
|
||||||
async def fetch_one_video(self, bv_id: str) -> dict:
|
async def fetch_one_video(self, bv_id: str) -> dict:
|
||||||
# 获取请求头信息
|
# 获取请求头信息
|
||||||
@ -50,6 +85,22 @@ class BilibiliWebCrawler:
|
|||||||
response = await crawler.fetch_get_json(endpoint)
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
|
# 获取视频流地址
|
||||||
|
async def fetch_video_playurl(self, bv_id: str, cid: str, qn: str = "64") -> dict:
|
||||||
|
# 获取请求头信息
|
||||||
|
kwargs = await self.get_bilibili_headers()
|
||||||
|
# 创建基础爬虫对象
|
||||||
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
|
async with base_crawler as crawler:
|
||||||
|
# 通过模型生成基本请求参数
|
||||||
|
params = PlayUrl(bvid=bv_id, cid=cid, qn=qn)
|
||||||
|
# 创建请求endpoint
|
||||||
|
generator = EndpointGenerator(params.dict())
|
||||||
|
endpoint = await generator.video_playurl_endpoint()
|
||||||
|
# 发送请求,获取请求响应结果
|
||||||
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
|
return response
|
||||||
|
|
||||||
# 获取用户发布视频作品数据
|
# 获取用户发布视频作品数据
|
||||||
async def fetch_user_post_videos(self, uid: str, pn: int) -> dict:
|
async def fetch_user_post_videos(self, uid: str, pn: int) -> dict:
|
||||||
"""
|
"""
|
||||||
@ -62,8 +113,11 @@ class BilibiliWebCrawler:
|
|||||||
# 创建基础爬虫对象
|
# 创建基础爬虫对象
|
||||||
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
|
# 通过模型生成基本请求参数
|
||||||
|
params = UserPostVideos(mid=uid, pn=pn)
|
||||||
# 创建请求endpoint
|
# 创建请求endpoint
|
||||||
endpoint = await EndpointModels().user_post_videos_endpoint(uid=uid, pn=pn)
|
generator = EndpointGenerator(params.dict())
|
||||||
|
endpoint = await generator.user_post_videos_endpoint()
|
||||||
# 发送请求,获取请求响应结果
|
# 发送请求,获取请求响应结果
|
||||||
response = await crawler.fetch_get_json(endpoint)
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
@ -96,8 +150,8 @@ class BilibiliWebCrawler:
|
|||||||
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
# 发送请求,获取请求响应结果
|
# 发送请求,获取请求响应结果
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
endpoint = f"{BilibiliAPIEndpoints.COLLECT_VIDEOS}?media_id={folder_id}&pn={pn}&ps=20&keyword=&order=mtime&type=0&tid=0&platform=web"
|
endpoint = f"{BilibiliAPIEndpoints.COLLECT_VIDEOS}?media_id={folder_id}&pn={pn}&ps=20&keyword=&order=mtime&type=0&tid=0&platform=web"
|
||||||
response = await crawler.fetch_get_json(endpoint)
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
# 获取指定用户的信息
|
# 获取指定用户的信息
|
||||||
@ -107,9 +161,13 @@ class BilibiliWebCrawler:
|
|||||||
# 创建基础爬虫对象
|
# 创建基础爬虫对象
|
||||||
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
|
# 通过模型生成基本请求参数
|
||||||
|
params = UserProfile(mid=uid)
|
||||||
# 创建请求endpoint
|
# 创建请求endpoint
|
||||||
endpoint = await EndpointModels().user_profile_endpoint(uid=uid)
|
generator = EndpointGenerator(params.dict())
|
||||||
response = await crawler.fetch_get_json(endpoint=endpoint)
|
endpoint = await generator.user_profile_endpoint()
|
||||||
|
# 发送请求,获取请求响应结果
|
||||||
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
# 获取综合热门视频信息
|
# 获取综合热门视频信息
|
||||||
@ -119,9 +177,13 @@ class BilibiliWebCrawler:
|
|||||||
# 创建基础爬虫对象
|
# 创建基础爬虫对象
|
||||||
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
|
# 通过模型生成基本请求参数
|
||||||
|
params = ComPopular(pn=pn)
|
||||||
# 创建请求endpoint
|
# 创建请求endpoint
|
||||||
endpoint = await EndpointModels().com_popular_endpoint(pn=pn)
|
generator = EndpointGenerator(params.dict())
|
||||||
response = await crawler.fetch_get_json(endpoint=endpoint)
|
endpoint = await generator.com_popular_endpoint()
|
||||||
|
# 发送请求,获取请求响应结果
|
||||||
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
# 获取指定视频的评论
|
# 获取指定视频的评论
|
||||||
@ -165,12 +227,29 @@ class BilibiliWebCrawler:
|
|||||||
# 创建基础爬虫对象
|
# 创建基础爬虫对象
|
||||||
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
|
# 通过模型生成基本请求参数
|
||||||
|
params = UserDynamic(host_mid=uid, offset=offset)
|
||||||
# 创建请求endpoint
|
# 创建请求endpoint
|
||||||
endpoint = await EndpointModels().user_dynamic_endpoint(uid=uid, offset=offset)
|
generator = EndpointGenerator(params.dict())
|
||||||
|
endpoint = await generator.user_dynamic_endpoint()
|
||||||
|
print(endpoint)
|
||||||
# 发送请求,获取请求响应结果
|
# 发送请求,获取请求响应结果
|
||||||
response = await crawler.fetch_get_json(endpoint)
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
|
# 获取视频实时弹幕
|
||||||
|
async def fetch_video_danmaku(self, cid: str):
|
||||||
|
# 获取请求头信息
|
||||||
|
kwargs = await self.get_bilibili_headers()
|
||||||
|
# 创建基础爬虫对象
|
||||||
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
|
async with base_crawler as crawler:
|
||||||
|
# 创建请求endpoint
|
||||||
|
endpoint = f"https://comment.bilibili.com/{cid}.xml"
|
||||||
|
# 发送请求,获取请求响应结果
|
||||||
|
response = await crawler.fetch_response(endpoint)
|
||||||
|
return response.text
|
||||||
|
|
||||||
# 获取指定直播间信息
|
# 获取指定直播间信息
|
||||||
async def fetch_live_room_detail(self, room_id: str) -> dict:
|
async def fetch_live_room_detail(self, room_id: str) -> dict:
|
||||||
# 获取请求头信息
|
# 获取请求头信息
|
||||||
@ -185,24 +264,51 @@ class BilibiliWebCrawler:
|
|||||||
return response
|
return response
|
||||||
|
|
||||||
# 获取指定直播间视频流
|
# 获取指定直播间视频流
|
||||||
# async def fetch_live_videos(self, room_id: str) -> dict:
|
async def fetch_live_videos(self, room_id: str) -> dict:
|
||||||
# # 获取请求头信息
|
# 获取请求头信息
|
||||||
# kwargs = await self.get_bilibili_headers()
|
kwargs = await self.get_bilibili_headers()
|
||||||
# # 创建基础爬虫对象
|
# 创建基础爬虫对象
|
||||||
# base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
# async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
# # 创建请求endpoint
|
# 创建请求endpoint
|
||||||
# endpoint = f"{BilibiliAPIEndpoints.LIVE_VIDEOS}?cid={room_id}&quality=4"
|
endpoint = f"{BilibiliAPIEndpoints.LIVE_VIDEOS}?cid={room_id}&quality=4"
|
||||||
# # 发送请求,获取请求响应结果
|
# 发送请求,获取请求响应结果
|
||||||
# response = await crawler.fetch_get_json(endpoint)
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
# return response
|
return response
|
||||||
|
|
||||||
|
# 获取指定分区正在直播的主播
|
||||||
|
async def fetch_live_streamers(self, area_id: str, pn: int):
|
||||||
|
# 获取请求头信息
|
||||||
|
kwargs = await self.get_bilibili_headers()
|
||||||
|
# 创建基础爬虫对象
|
||||||
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
|
async with base_crawler as crawler:
|
||||||
|
# 创建请求endpoint
|
||||||
|
endpoint = f"{BilibiliAPIEndpoints.LIVE_STREAMER}?platform=web&parent_area_id={area_id}&page={pn}"
|
||||||
|
# 发送请求,获取请求响应结果
|
||||||
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
|
return response
|
||||||
|
|
||||||
"-------------------------------------------------------utils接口列表-------------------------------------------------------"
|
"-------------------------------------------------------utils接口列表-------------------------------------------------------"
|
||||||
|
|
||||||
# 通过bv号获得视频aid号
|
# 通过bv号获得视频aid号
|
||||||
async def get_aid(self, bv_id: str) -> int:
|
async def bv_to_aid(self, bv_id: str) -> int:
|
||||||
aid = await bv2av(bv_id=bv_id)
|
aid = await bv2av(bv_id=bv_id)
|
||||||
return aid
|
return aid
|
||||||
|
|
||||||
|
# 通过bv号获得视频分p信息
|
||||||
|
async def fetch_video_parts(self, bv_id: str) -> str:
|
||||||
|
# 获取请求头信息
|
||||||
|
kwargs = await self.get_bilibili_headers()
|
||||||
|
# 创建基础爬虫对象
|
||||||
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
|
async with base_crawler as crawler:
|
||||||
|
# 创建请求endpoint
|
||||||
|
endpoint = f"{BilibiliAPIEndpoints.VIDEO_PARTS}?bvid={bv_id}"
|
||||||
|
# 发送请求,获取请求响应结果
|
||||||
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
|
return response
|
||||||
|
|
||||||
# 获取所有直播分区列表
|
# 获取所有直播分区列表
|
||||||
async def fetch_all_live_areas(self) -> dict:
|
async def fetch_all_live_areas(self) -> dict:
|
||||||
# 获取请求头信息
|
# 获取请求头信息
|
||||||
@ -216,23 +322,24 @@ class BilibiliWebCrawler:
|
|||||||
response = await crawler.fetch_get_json(endpoint)
|
response = await crawler.fetch_get_json(endpoint)
|
||||||
return response
|
return response
|
||||||
|
|
||||||
# 根据uid生成wts及其对应w_rid参数(包含dm_img_inter参数)
|
|
||||||
# (仅示例 不同接口所需要传进去的参数不同)(待改进)
|
|
||||||
async def uid_to_wrid(self, uid: str) -> dict:
|
|
||||||
result = await EndpointModels().get_wrid_wts_by_uid(uid=uid)
|
|
||||||
return result
|
|
||||||
|
|
||||||
"-------------------------------------------------------main-------------------------------------------------------"
|
"-------------------------------------------------------main-------------------------------------------------------"
|
||||||
async def main(self):
|
|
||||||
|
|
||||||
"-------------------------------------------------------handler接口列表-------------------------------------------------------"
|
async def main(self):
|
||||||
|
"""-------------------------------------------------------handler接口列表-------------------------------------------------------"""
|
||||||
|
|
||||||
# 获取单个作品数据
|
# 获取单个作品数据
|
||||||
# bv_id = 'BV1M1421t7hT'
|
# bv_id = 'BV1M1421t7hT'
|
||||||
# result = await self.fetch_one_video(bv_id=bv_id)
|
# result = await self.fetch_one_video(bv_id=bv_id)
|
||||||
# print(result)
|
# print(result)
|
||||||
|
|
||||||
|
# 获取视频流地址
|
||||||
|
# bv_id = 'BV1y7411Q7Eq'
|
||||||
|
# cid = '171776208'
|
||||||
|
# result = await self.fetch_video_playurl(bv_id=bv_id, cid=cid)
|
||||||
|
# print(result)
|
||||||
|
|
||||||
# 获取用户发布作品数据
|
# 获取用户发布作品数据
|
||||||
# uid = '178360345'
|
# uid = '94510621'
|
||||||
# pn = 1
|
# pn = 1
|
||||||
# result = await self.fetch_user_post_videos(uid=uid, pn=pn)
|
# result = await self.fetch_user_post_videos(uid=uid, pn=pn)
|
||||||
# print(result)
|
# print(result)
|
||||||
@ -273,36 +380,46 @@ class BilibiliWebCrawler:
|
|||||||
|
|
||||||
# 获取指定用户动态
|
# 获取指定用户动态
|
||||||
# uid = "16015678"
|
# uid = "16015678"
|
||||||
# offset = "953154282154098691" # 翻页索引,为空即从最新动态开始,可从获得到的动态数据里面获得
|
# offset = "" # 翻页索引,为空即从最新动态开始
|
||||||
# result = await self.fetch_user_dynamic(uid=uid, offset=offset)
|
# result = await self.fetch_user_dynamic(uid=uid, offset=offset)
|
||||||
# print(result)
|
# print(result)
|
||||||
|
|
||||||
|
# 获取视频实时弹幕
|
||||||
|
# cid = "1639235405"
|
||||||
|
# result = await self.fetch_video_danmaku(cid=cid)
|
||||||
|
# print(result)
|
||||||
|
|
||||||
# 获取指定直播间信息
|
# 获取指定直播间信息
|
||||||
# room_id = "22816111"
|
# room_id = "1815229528"
|
||||||
# result = await self.fetch_live_room_detail(room_id=room_id)
|
# result = await self.fetch_live_room_detail(room_id=room_id)
|
||||||
# print(result)
|
# print(result)
|
||||||
|
|
||||||
# 获取直播间视频流
|
# 获取直播间视频流
|
||||||
# room_id = "22816111"
|
# room_id = "1815229528"
|
||||||
# result = await self.fetch_user_live_videos_by_room_id(room_id=room_id)
|
# result = await self.fetch_live_videos(room_id=room_id)
|
||||||
# print(result)
|
# print(result)
|
||||||
|
|
||||||
|
# 获取指定分区正在直播的主播
|
||||||
|
pn = 1
|
||||||
|
area_id = '9'
|
||||||
|
result = await self.fetch_live_streamers(area_id=area_id, pn=pn)
|
||||||
|
print(result)
|
||||||
|
|
||||||
"-------------------------------------------------------utils接口列表-------------------------------------------------------"
|
"-------------------------------------------------------utils接口列表-------------------------------------------------------"
|
||||||
# 通过bv号获得视频aid号
|
# 通过bv号获得视频aid号
|
||||||
# bv_id = 'BV1M1421t7hT'
|
# bv_id = 'BV1M1421t7hT'
|
||||||
# aid = await self.get_aid(bv_id=bv_id)
|
# aid = await self.get_aid(bv_id=bv_id)
|
||||||
# print(aid)
|
# print(aid)
|
||||||
|
|
||||||
|
# 通过bv号获得视频分p信息
|
||||||
|
# bv_id = "BV1vf421i7hV"
|
||||||
|
# result = await self.fetch_video_parts(bv_id=bv_id)
|
||||||
|
# print(result)
|
||||||
|
|
||||||
# 获取所有直播分区列表
|
# 获取所有直播分区列表
|
||||||
# result = await self.fetch_all_live_areas()
|
# result = await self.fetch_all_live_areas()
|
||||||
# print(result)
|
# print(result)
|
||||||
|
|
||||||
# 根据uid生成wts及其对应w_rid参数(包含dm_img_inter参数)
|
|
||||||
# (仅示例 不同接口所需要传进去的参数不同)(待改进)
|
|
||||||
# uid = '178360345'
|
|
||||||
# w_rid = await self.uid_to_wrid(uid=uid)
|
|
||||||
# print(w_rid)
|
|
||||||
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
if __name__ == '__main__':
|
||||||
# 初始化
|
# 初始化
|
||||||
|
|||||||
@ -184,21 +184,3 @@ def get_wrid(e):
|
|||||||
n = None
|
n = None
|
||||||
i = twords_to_bytes(o(e, n))
|
i = twords_to_bytes(o(e, n))
|
||||||
return tbytes_to_hex(i)
|
return tbytes_to_hex(i)
|
||||||
|
|
||||||
# def test():
|
|
||||||
# e = "dm_cover_img_str=QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ&dm_img_inter=%7B%22ds%22%3A%5B%5D%2C%22wh%22%3A%5B3697%2C5674%2C33%5D%2C%22of%22%3A%5B222%2C444%2C222%5D%7D&dm_img_list=%5B%5D&dm_img_str=V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&mid=3546666038725258&platform=web&token=&web_location=1550101&wts=1723867512ea1db124af3c7062474693fa704f4ff8"
|
|
||||||
# n = None
|
|
||||||
# x = o(e, n)
|
|
||||||
# i = twords_to_bytes(x)
|
|
||||||
# return tbytes_to_hex(i)
|
|
||||||
|
|
||||||
# if __name__ == '__main__':
|
|
||||||
# # test()
|
|
||||||
# encode_query = "dm_cover_img_str=QU5HTEUgKE5WSURJQSwgTlZJRElBIEdlRm9yY2UgUlRYIDMwNTAgTGFwdG9wIEdQVSAoMHgwMDAwMjVBMikgRGlyZWN0M0QxMSB2c181XzAgcHNfNV8wLCBEM0QxMSlHb29nbGUgSW5jLiAoTlZJRElBKQ&dm_img_inter=%7B%22ds%22%3A%5B%5D%2C%22wh%22%3A%5B3697%2C5674%2C33%5D%2C%22of%22%3A%5B222%2C444%2C222%5D%7D&dm_img_list=%5B%5D&dm_img_str=V2ViR0wgMS4wIChPcGVuR0wgRVMgMi4wIENocm9taXVtKQ&mid=3546666038725258&platform=web&token=&web_location=1550101&wts=1723867512ea1db124af3c7062474693fa704f4ff8"
|
|
||||||
# wrid1 = main(encode_query)
|
|
||||||
# print(wrid1)
|
|
||||||
#
|
|
||||||
# js1 = open('./wrid.js', 'r', encoding='utf-8').read()
|
|
||||||
# wrid2 = execjs.compile(js1).call('main', encode_query)
|
|
||||||
# print(wrid2)
|
|
||||||
|
|
||||||
|
|||||||
@ -2,15 +2,21 @@ TokenManager:
|
|||||||
douyin:
|
douyin:
|
||||||
headers:
|
headers:
|
||||||
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
|
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
|
||||||
|
# 不要这里的修改User-Agent,请保持默认,否则会导致请求失败。
|
||||||
|
# Do not modify User-Agent here, please keep the default, otherwise it will cause request failure.
|
||||||
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
|
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
|
||||||
Referer: https://www.douyin.com/
|
Referer: https://www.douyin.com/
|
||||||
Cookie: __ac_nonce=06688805800feabd0488; __ac_signature=_02B4Z6wo00f01uD9yLQAAIDDPIRXALVKsdrg3cwAAN7Fb0; ttwid=1%7CY3tr3NnjDAbW8n6XjSF31tTHDzCCcFEz5Bq12tRDG3o%7C1720221784%7Ca7d14bd093d22c7cb9238cceaf7f4d4e0966eeaa566fc7dea03a1018c76c35bf; UIFID_TEMP=3c3e9d4a635845249e00419877a3730e2149197a63ddb1d8525033ea2b3354c2e4e209d591bdd0dd678a41489f74bacd5643d8ac82c61f801e7d08895f95074527d26a84ac51fd07414c893b452b25a6; douyin.com; device_web_cpu_core=32; device_web_memory_size=8; architecture=amd64; IsDouyinActive=true; home_can_add_dy_2_desktop=%220%22; dy_swidth=1463; dy_sheight=915; stream_recommend_feed_params=%22%7B%5C%22cookie_enabled%5C%22%3Atrue%2C%5C%22screen_width%5C%22%3A1463%2C%5C%22screen_height%5C%22%3A915%2C%5C%22browser_online%5C%22%3Atrue%2C%5C%22cpu_core_num%5C%22%3A32%2C%5C%22device_memory%5C%22%3A8%2C%5C%22downlink%5C%22%3A10%2C%5C%22effective_type%5C%22%3A%5C%224g%5C%22%2C%5C%22round_trip_time%5C%22%3A50%7D%22; strategyABtestKey=%221720221787.528%22; fpk1=U2FsdGVkX1/PHJWrr34dlQOtMNbk1POhDsZytNmw7q3nzP6RO1++Ta+Gl7eZ+ZFizEL6AlisgxzYy90lV16jDw==; fpk2=f1f6b29a6cc1f79a0fea05b885aa33d0; stream_player_status_params=%22%7B%5C%22is_auto_play%5C%22%3A0%2C%5C%22is_full_screen%5C%22%3A0%2C%5C%22is_full_webscreen%5C%22%3A0%2C%5C%22is_mute%5C%22%3A1%2C%5C%22is_speed%5C%22%3A1%2C%5C%22is_visible%5C%22%3A1%7D%22; volume_info=%7B%22isUserMute%22%3Afalse%2C%22isMute%22%3Atrue%2C%22volume%22%3A0.5%7D; csrf_session_id=6f34e666e71445c9d39d8d06a347a13f; passport_csrf_token=c0ace937a38083a0abf5e537a4d21094; passport_csrf_token_default=c0ace937a38083a0abf5e537a4d21094; FORCE_LOGIN=%7B%22videoConsumedRemainSeconds%22%3A180%7D; odin_tt=e7c9f6ae63907dbd47a55d0d7ab8c1f63e4a39bba773e7aa74002644b636d0c3ec88b980caceb1c125a4191f01228ecb440d627c627680b5d2f7ad4868289321df8da3e73abc0b27a8ef47ecad5d2913; biz_trace_id=21e3deea; xgplayer_user_id=236721600851; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWl0ZXJhdGlvbi12ZXJzaW9uIjoxLCJiZC10aWNrZXQtZ3VhcmQtcmVlLXB1YmxpYy1rZXkiOiJCQWdPWlV1QSs5VmViK3B3M09xSFhJR0tBWmMzQS85emVjeUFnd2FkZHRuYUtWdjJLZUhZVjEzZHc0ZlhndXdBdGtjRDVUYW9QZHBqcnAvcjAwemNLVjg9IiwiYmQtdGlja2V0LWd1YXJkLXdlYi12ZXJzaW9uIjoxfQ%3D%3D; bd_ticket_guard_client_web_domain=2; s_v_web_id=verify_ly9bn3e2_K5nh68iF_eJRa_48Fq_80mp_dUR4VkUIOrFr
|
# 你唯一需要修改的地方就是这里的Cookie,然后保存后重启程序即可。
|
||||||
|
# The only place you need to modify is the Cookie here, and then save and restart the program.
|
||||||
|
Cookie: __ac_nonce=067d687ac00d70af16eab; __ac_signature=_02B4Z6wo00f018O6kmgAAIDAR1H8JrcivBPDi5bAAJdBcf; ttwid=1%7C46sVJ6G5zO0ZRKBqbFef2B13U3CqP9gLwQEH8IV2y6A%7C1742112685%7Cae649397cca7dde21884d5f8e3e3d53eb2361aa64af04cd6889fa71d7f23344b; UIFID_TEMP=986fab8dfc2c74111fac2b883dbdee67777473ded35e2c4bebbf68cc8b91739da61f6b365ad9795b0aa3a8bddce6cc3e39c5d4fd4bad667aaefd3d3ec08baac66fe3b215343f12d8aae84e0a24048f44; douyin.com; device_web_cpu_core=16; device_web_memory_size=-1; architecture=amd64; hevc_supported=true; IsDouyinActive=true; home_can_add_dy_2_desktop=%220%22; dy_swidth=1835; dy_sheight=1147; stream_recommend_feed_params=%22%7B%5C%22cookie_enabled%5C%22%3Atrue%2C%5C%22screen_width%5C%22%3A1835%2C%5C%22screen_height%5C%22%3A1147%2C%5C%22browser_online%5C%22%3Atrue%2C%5C%22cpu_core_num%5C%22%3A16%2C%5C%22device_memory%5C%22%3A0%2C%5C%22downlink%5C%22%3A%5C%22%5C%22%2C%5C%22effective_type%5C%22%3A%5C%22%5C%22%2C%5C%22round_trip_time%5C%22%3A0%7D%22; strategyABtestKey=%221742112685.842%22; volume_info=%7B%22isUserMute%22%3Afalse%2C%22isMute%22%3Afalse%2C%22volume%22%3A0.5%7D; stream_player_status_params=%22%7B%5C%22is_auto_play%5C%22%3A0%2C%5C%22is_full_screen%5C%22%3A0%2C%5C%22is_full_webscreen%5C%22%3A0%2C%5C%22is_mute%5C%22%3A0%2C%5C%22is_speed%5C%22%3A1%2C%5C%22is_visible%5C%22%3A1%7D%22; xgplayer_user_id=835787001711; fpk1=U2FsdGVkX19Ke0llbjXpGOOr1Jeel/2GnaSJz41VO3mAFs271jC0hG7gdWlk+2pYLM4GF8TVGtwClCJIXsTKUw==; fpk2=2333b8d335abc6e14aef1caed0ae26fc; s_v_web_id=verify_m8bcww86_XfwSCnmj_5i3F_4Joq_8edO_9gRH9JENh07f; csrf_session_id=6f34e666e71445c9d39d8d06a347a13f; FORCE_LOGIN=%7B%22videoConsumedRemainSeconds%22%3A180%7D; biz_trace_id=c34e5eaf; passport_csrf_token=ab84b3e39ad78e719b236035a27379c0; passport_csrf_token_default=ab84b3e39ad78e719b236035a27379c0; __security_mc_1_s_sdk_crypt_sdk=ac2d56c3-44cd-a161; __security_mc_1_s_sdk_cert_key=ccf2bd2d-4718-b8de; __security_mc_1_s_sdk_sign_data_key_web_protect=9995d368-4e45-b17f; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWl0ZXJhdGlvbi12ZXJzaW9uIjoxLCJiZC10aWNrZXQtZ3VhcmQtcmVlLXB1YmxpYy1rZXkiOiJCUHR2ZDlUeGU4UlhPaWdIczFqaStJWityQlF4UWZMKytiL2drbXlYUmNrelNua1lQUjJTRVZHVlo4MWFCU0EvSW4xSnBmbzN3TFlvSnhIZTZTV29DTmc9IiwiYmQtdGlja2V0LWd1YXJkLXdlYi12ZXJzaW9uIjoyfQ%3D%3D; bd_ticket_guard_client_web_domain=2; xg_device_score=8.208487995540095; sdk_source_info=7e276470716a68645a606960273f276364697660272927676c715a6d6069756077273f276364697660272927666d776a68605a607d71606b766c6a6b5a7666776c7571273f275e58272927666a6b766a69605a696c6061273f27636469766027292762696a6764695a7364776c6467696076273f275e5827292771273f27303035353c3337343437313234272927676c715a75776a716a666a69273f2763646976602778; bit_env=LVdHnIescW9BCGpo5gGuqIlwNfgj757SBdMhdZXBSWjPWbxp9Nv_B2vUt_LtEvr-ioRv0E9b8N8HWiOHe20JqcUhO4YmpIM6gB83hjgqZfmAhYEbzJR7z2bRViJaPg4xeoyGhwdjwK_Bzogp6uoUs4ov-P4JYzMh78i7jaY5Pzd6h3CaVO-eUKnTiFfUlJo_jmhSfHXGdwkurXwR4lO_UnU4Loqa0YlmDiyi0fPxURFIN5t4Ny6Ua8LLSYcUrBXHlXoQ5G4bQN4XqwuWwT9YauexXbkotU1Jv8pMJUiAhlFIMjbvfTutTSnOXJLoH_JsR_doifURl0wf8CIa_OcYw-A2VglrpbaFU6HDVTKbSRKovzIMY9bUwl_4EAiLBf87g2BU0Uz1MHd_lGNdH3ImEWpLtdRvUsW_KD7q87rPsEGVTceyQ5U3ZlETqoEOwOiggNGu5lL_1O8lt8_7eydeGA%3D%3D; gulu_source_res=eyJwX2luIjoiM2Y3NGJhZDgxMzc3OThkNmVkN2U5ZjM3NDMzNGJkYjMwNzRhYjI0ZWJhMDZkMzdmYWNiNjgzNTY2ZjY0OGUyNCJ9; passport_auth_mix_state=c534f2qcgpohqv4juisp74wq28e90snz
|
||||||
|
|
||||||
proxies:
|
proxies:
|
||||||
http:
|
http:
|
||||||
https:
|
https:
|
||||||
|
|
||||||
msToken:
|
msToken:
|
||||||
|
# 不要修改下面的内容。
|
||||||
|
# Do not modify the content below.
|
||||||
url: https://mssdk.bytedance.com/web/report
|
url: https://mssdk.bytedance.com/web/report
|
||||||
magic: 538969122
|
magic: 538969122
|
||||||
version: 1
|
version: 1
|
||||||
@ -19,5 +25,7 @@ TokenManager:
|
|||||||
User-Agent: 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47
|
User-Agent: 5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47
|
||||||
|
|
||||||
ttwid:
|
ttwid:
|
||||||
|
# 不要修改下面的内容。
|
||||||
|
# Do not modify the content below.
|
||||||
url: https://ttwid.bytedance.com/ttwid/union/register/
|
url: https://ttwid.bytedance.com/ttwid/union/register/
|
||||||
data: '{"region":"cn","aid":1768,"needFid":false,"service":"www.ixigua.com","migrate_info":{"ticket":"","source":"node"},"cbUrlProtocol":"https","union":true}'
|
data: '{"region":"cn","aid":1768,"needFid":false,"service":"www.ixigua.com","migrate_info":{"ticket":"","source":"node"},"cbUrlProtocol":"https","union":true}'
|
||||||
@ -10,27 +10,35 @@ class BaseRequestModel(BaseModel):
|
|||||||
aid: str = "6383"
|
aid: str = "6383"
|
||||||
channel: str = "channel_pc_web"
|
channel: str = "channel_pc_web"
|
||||||
pc_client_type: int = 1
|
pc_client_type: int = 1
|
||||||
version_code: str = "190500"
|
version_code: str = "290100"
|
||||||
version_name: str = "19.5.0"
|
version_name: str = "29.1.0"
|
||||||
cookie_enabled: str = "true"
|
cookie_enabled: str = "true"
|
||||||
screen_width: int = 1920
|
screen_width: int = 1920
|
||||||
screen_height: int = 1080
|
screen_height: int = 1080
|
||||||
browser_language: str = "zh-CN"
|
browser_language: str = "zh-CN"
|
||||||
browser_platform: str = "Win32"
|
browser_platform: str = "Win32"
|
||||||
browser_name: str = "Firefox"
|
browser_name: str = "Chrome"
|
||||||
browser_version: str = "124.0"
|
browser_version: str = "130.0.0.0"
|
||||||
browser_online: str = "true"
|
browser_online: str = "true"
|
||||||
engine_name: str = "Gecko"
|
engine_name: str = "Blink"
|
||||||
engine_version: str = "122.0.0.0"
|
engine_version: str = "130.0.0.0"
|
||||||
os_name: str = "Windows"
|
os_name: str = "Windows"
|
||||||
os_version: str = "10"
|
os_version: str = "10"
|
||||||
cpu_core_num: int = 12
|
cpu_core_num: int = 12
|
||||||
device_memory: int = 8
|
device_memory: int = 8
|
||||||
platform: str = "PC"
|
platform: str = "PC"
|
||||||
# webid: str = "7388296161008862738"
|
downlink: str = "10"
|
||||||
# downlink: int = 10
|
effective_type: str = "4g"
|
||||||
# effective_type: str = "4g"
|
from_user_page: str = "1"
|
||||||
# round_trip_time: int = 100
|
locate_query: str = "false"
|
||||||
|
need_time_list: str = "1"
|
||||||
|
pc_libra_divert: str = "Windows"
|
||||||
|
publish_video_strategy_type: str = "2"
|
||||||
|
round_trip_time: str = "0"
|
||||||
|
show_live_replay_strategy: str = "1"
|
||||||
|
time_list_query: str = "0"
|
||||||
|
whale_cut_token: str = ""
|
||||||
|
update_version_code: str = "170400"
|
||||||
msToken: str = TokenManager.gen_real_msToken()
|
msToken: str = TokenManager.gen_real_msToken()
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -406,6 +406,7 @@ class SecUserIdFetcher:
|
|||||||
class AwemeIdFetcher:
|
class AwemeIdFetcher:
|
||||||
# 预编译正则表达式
|
# 预编译正则表达式
|
||||||
_DOUYIN_VIDEO_URL_PATTERN = re.compile(r"video/([^/?]*)")
|
_DOUYIN_VIDEO_URL_PATTERN = re.compile(r"video/([^/?]*)")
|
||||||
|
_DOUYIN_VIDEO_URL_PATTERN_NEW = re.compile(r"[?&]vid=(\d+)")
|
||||||
_DOUYIN_NOTE_URL_PATTERN = re.compile(r"note/([^/?]*)")
|
_DOUYIN_NOTE_URL_PATTERN = re.compile(r"note/([^/?]*)")
|
||||||
_DOUYIN_DISCOVER_URL_PATTERN = re.compile(r"modal_id=([0-9]+)")
|
_DOUYIN_DISCOVER_URL_PATTERN = re.compile(r"modal_id=([0-9]+)")
|
||||||
|
|
||||||
@ -418,62 +419,44 @@ class AwemeIdFetcher:
|
|||||||
url (str): 输入的url (Input url)
|
url (str): 输入的url (Input url)
|
||||||
|
|
||||||
Returns:
|
Returns:
|
||||||
str: 匹配到的aweme_id (Matched aweme_id)。
|
str: 匹配到的aweme_id (Matched aweme_id)
|
||||||
"""
|
"""
|
||||||
|
|
||||||
if not isinstance(url, str):
|
if not isinstance(url, str):
|
||||||
raise TypeError("参数必须是字符串类型")
|
raise TypeError("参数必须是字符串类型")
|
||||||
|
|
||||||
# 提取有效URL
|
|
||||||
url = extract_valid_urls(url)
|
|
||||||
|
|
||||||
if url is None:
|
|
||||||
raise (
|
|
||||||
APINotFoundError("输入的URL不合法。类名:{0}".format(cls.__name__))
|
|
||||||
)
|
|
||||||
|
|
||||||
# 重定向到完整链接
|
# 重定向到完整链接
|
||||||
transport = httpx.AsyncHTTPTransport(retries=5)
|
transport = httpx.AsyncHTTPTransport(retries=5)
|
||||||
async with httpx.AsyncClient(
|
async with httpx.AsyncClient(
|
||||||
transport=transport, proxies=TokenManager.proxies, timeout=10
|
transport=transport, proxy=None, timeout=10
|
||||||
) as client:
|
) as client:
|
||||||
try:
|
try:
|
||||||
response = await client.get(url, follow_redirects=True)
|
response = await client.get(url, follow_redirects=True)
|
||||||
response.raise_for_status()
|
response.raise_for_status()
|
||||||
|
|
||||||
video_pattern = cls._DOUYIN_VIDEO_URL_PATTERN
|
response_url = str(response.url)
|
||||||
note_pattern = cls._DOUYIN_NOTE_URL_PATTERN
|
|
||||||
discover_pattern = cls._DOUYIN_DISCOVER_URL_PATTERN
|
|
||||||
|
|
||||||
# 2024-4-22
|
# 按顺序尝试匹配视频ID
|
||||||
# 嵌套如果超过3层需要修改此处代码 (If the nesting exceeds 3 layers, you need to modify this code)
|
for pattern in [
|
||||||
match = video_pattern.search(str(response.url))
|
cls._DOUYIN_VIDEO_URL_PATTERN,
|
||||||
if video_pattern.search(str(response.url)):
|
cls._DOUYIN_VIDEO_URL_PATTERN_NEW,
|
||||||
aweme_id = match.group(1)
|
cls._DOUYIN_NOTE_URL_PATTERN,
|
||||||
else:
|
cls._DOUYIN_DISCOVER_URL_PATTERN
|
||||||
match = note_pattern.search(str(response.url))
|
]:
|
||||||
|
match = pattern.search(response_url)
|
||||||
if match:
|
if match:
|
||||||
aweme_id = match.group(1)
|
return match.group(1)
|
||||||
else:
|
|
||||||
match = discover_pattern.search(str(response.url))
|
raise APIResponseError("未在响应的地址中找到 aweme_id,检查链接是否为作品页")
|
||||||
if match:
|
|
||||||
aweme_id = match.group(1)
|
|
||||||
else:
|
|
||||||
raise APIResponseError(
|
|
||||||
"未在响应的地址中找到aweme_id,检查链接是否为作品页"
|
|
||||||
)
|
|
||||||
return aweme_id
|
|
||||||
|
|
||||||
except httpx.RequestError as exc:
|
except httpx.RequestError as exc:
|
||||||
# 捕获所有与 httpx 请求相关的异常情况 (Captures all httpx request-related exceptions)
|
raise APIConnectionError(
|
||||||
raise APIConnectionError("请求端点失败,请检查当前网络环境。 链接:{0},代理:{1},异常类名:{2},异常详细信息:{3}"
|
f"请求端点失败,请检查当前网络环境。链接:{url},代理:{TokenManager.proxies},异常类名:{cls.__name__},异常详细信息:{exc}"
|
||||||
.format(url, TokenManager.proxies, cls.__name__, exc)
|
)
|
||||||
)
|
|
||||||
|
|
||||||
except httpx.HTTPStatusError as e:
|
except httpx.HTTPStatusError as e:
|
||||||
raise APIResponseError("链接:{0},状态码 {1}:{2} ".format(
|
raise APIResponseError(
|
||||||
e.response.url, e.response.status_code, e.response.text
|
f"链接:{e.response.url},状态码 {e.response.status_code}:{e.response.text}"
|
||||||
)
|
|
||||||
)
|
)
|
||||||
|
|
||||||
@classmethod
|
@classmethod
|
||||||
|
|||||||
@ -164,7 +164,13 @@ class HybridCrawler:
|
|||||||
if url_type == 'video':
|
if url_type == 'video':
|
||||||
# 将信息储存在字典中/Store information in a dictionary
|
# 将信息储存在字典中/Store information in a dictionary
|
||||||
# wm_video = data['video']['downloadAddr']
|
# wm_video = data['video']['downloadAddr']
|
||||||
wm_video = data['video']['download_addr']['url_list'][0]
|
# wm_video = data['video']['download_addr']['url_list'][0]
|
||||||
|
wm_video = (
|
||||||
|
data.get('video', {})
|
||||||
|
.get('download_addr', {})
|
||||||
|
.get('url_list', [None])[0]
|
||||||
|
)
|
||||||
|
|
||||||
api_data = {
|
api_data = {
|
||||||
'video_data':
|
'video_data':
|
||||||
{
|
{
|
||||||
@ -199,7 +205,8 @@ class HybridCrawler:
|
|||||||
async def main(self):
|
async def main(self):
|
||||||
# 测试混合解析单一视频接口/Test hybrid parsing single video endpoint
|
# 测试混合解析单一视频接口/Test hybrid parsing single video endpoint
|
||||||
# url = "https://v.douyin.com/L4FJNR3/"
|
# url = "https://v.douyin.com/L4FJNR3/"
|
||||||
url = "https://www.tiktok.com/@taylorswift/video/7359655005701311786"
|
# url = "https://www.tiktok.com/@taylorswift/video/7359655005701311786"
|
||||||
|
url = "https://www.tiktok.com/@flukegk83/video/7360734489271700753"
|
||||||
# url = "https://www.tiktok.com/@minecraft/photo/7369296852669205791"
|
# url = "https://www.tiktok.com/@minecraft/photo/7369296852669205791"
|
||||||
minimal = True
|
minimal = True
|
||||||
result = await self.hybrid_parsing_single_video(url, minimal=minimal)
|
result = await self.hybrid_parsing_single_video(url, minimal=minimal)
|
||||||
|
|||||||
@ -43,6 +43,9 @@ from crawlers.base_crawler import BaseCrawler
|
|||||||
from crawlers.tiktok.app.endpoints import TikTokAPIEndpoints
|
from crawlers.tiktok.app.endpoints import TikTokAPIEndpoints
|
||||||
from crawlers.utils.utils import model_to_query_string
|
from crawlers.utils.utils import model_to_query_string
|
||||||
|
|
||||||
|
# 重试机制
|
||||||
|
from tenacity import *
|
||||||
|
|
||||||
# TikTok接口数据请求模型
|
# TikTok接口数据请求模型
|
||||||
from crawlers.tiktok.app.models import (
|
from crawlers.tiktok.app.models import (
|
||||||
BaseRequestModel, FeedVideoDetail
|
BaseRequestModel, FeedVideoDetail
|
||||||
@ -71,7 +74,8 @@ class TikTokAPPCrawler:
|
|||||||
"Cookie": tiktok_config["headers"]["Cookie"],
|
"Cookie": tiktok_config["headers"]["Cookie"],
|
||||||
"x-ladon": "Hello From Evil0ctal!",
|
"x-ladon": "Hello From Evil0ctal!",
|
||||||
},
|
},
|
||||||
"proxies": {"http://": None, "https://": None},
|
"proxies": {"http://": tiktok_config["proxies"]["http"],
|
||||||
|
"https://": tiktok_config["proxies"]["https"]}
|
||||||
}
|
}
|
||||||
return kwargs
|
return kwargs
|
||||||
|
|
||||||
@ -79,6 +83,7 @@ class TikTokAPPCrawler:
|
|||||||
|
|
||||||
# 获取单个作品数据
|
# 获取单个作品数据
|
||||||
# @deprecated("TikTok APP fetch_one_video is deprecated and will be removed in a future release. Use Web API instead. | TikTok APP fetch_one_video 已弃用,将在将来的版本中删除。请改用Web API。")
|
# @deprecated("TikTok APP fetch_one_video is deprecated and will be removed in a future release. Use Web API instead. | TikTok APP fetch_one_video 已弃用,将在将来的版本中删除。请改用Web API。")
|
||||||
|
@retry(stop=stop_after_attempt(10), wait=wait_fixed(1))
|
||||||
async def fetch_one_video(self, aweme_id: str):
|
async def fetch_one_video(self, aweme_id: str):
|
||||||
# 获取TikTok的实时Cookie
|
# 获取TikTok的实时Cookie
|
||||||
kwargs = await self.get_tiktok_headers()
|
kwargs = await self.get_tiktok_headers()
|
||||||
|
|||||||
@ -3,6 +3,8 @@ TokenManager:
|
|||||||
headers:
|
headers:
|
||||||
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
|
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36
|
||||||
Referer: https://www.tiktok.com/
|
Referer: https://www.tiktok.com/
|
||||||
|
# 你唯一需要修改的地方就是这里的Cookie,然后保存后重启程序即可。
|
||||||
|
# The only place you need to modify is the Cookie here, and then save and restart the program.
|
||||||
Cookie: tt_csrf_token=bwnaRGd9-B-0ce8ntqw9jtGzAdvzTRKNpBl0; ak_bmsc=75A1956756DE42FD14ED069AAE7A8780~000000000000000000000000000000~YAAQXCw+F8jpmBGQAQAAIfGsFBj+ZEGzR/ZeiuPpMtItu0QQUQRmjBX2kADliy6QA9rZSfrxRUZc9zuRrI4/xbIrAwA/nkdguGpa+v3QSn/1sk5uP2aqLVm0eYB/SGNafa2h2QvIPbLNiSCRhgq1GalZJL4+udqDnyBRJWE74nin74bZwrVDvCX1s8M2hWqZ9/jTkdm4sfwON9MdJIEtjAPlddQ4gxoqjPoWhfnrm24dhPT4OjL1B8QP1mgurj7zJGspqD53VcjkAl65gHVxp3dwZ5WbPYpqrh9j8wo2u/Wh6uhX+0HWmkv5yVZyTyYQTl3/ilPp9G4CuIUi84gaPLjNYea9AEnphNX0ywzDa6/yegfqyE6r3wqBBDCrR1xRM98YEB4A5PV7pw==; tt_chain_token=ljZFLdRDfyfDflXMg5XGpg==; tiktok_webapp_theme_auto_dark_ab=1; tiktok_webapp_theme=dark; perf_feed_cache={%22expireTimestamp%22:1718503200000%2C%22itemIds%22:[%227348816520216186158%22%2C%227356022137678810410%22%2C%227349561209340857630%22]}; s_v_web_id=verify_lxe3l432_JnDE5WWo_URef_4WrS_88IM_fd1CqEXZs4dZ; passport_csrf_token=af197f073ed95f4dc2636f24d55566a6; passport_csrf_token_default=af197f073ed95f4dc2636f24d55566a6; ttwid=1%7CuNT4GcgvvOjH8rTETh9d9xti_QDJjlcnSK2V7djIpuc%7C1718333954%7Cf81b989a495aedff91302da4d0a3ab6055dea486fb203a4326b37d5a5346ad0c; msToken=1Mhpyi8MlaZjM6bbLDVUhCj_6C0kEO_1_Nb62ByXLg7wy_vLnBxdMFpKclhf4HYnEjCghk2Gq47ZM5jPj3L1yFxQUZvq4oPLo1b2Wfe_33RE94uIxdiR-eSueWbcYDDgOj1Pn9Wyid5Uf5fzBQ7xxFA=; bm_sv=9ADBA7BE06EC41817F117E2279F1410C~YAAQXCw+F8bsmBGQAQAAzSewFBg2fP3Zd0aky2x7S13D97O64xi8EXhoKORBnPQyCHlh0iSlh63FFjoy6peDWaF3lkWaTly3Z7I7WvWk1GCntnYzpJaSCE5EO2OL38zPWpHcgGWuekluvptHXsheedNEefN4SUHVMt4jJynWNeTKrao0RmNLkH4zGs7QO6+MPCt94QFvNfLjBRr0wVcXlN/hx9m6kcvCyzsBBqEnpugoYvZ0SMA+INsKI5PDfQz1~1; msToken=449_l3kdcLmnEHdDP0uACa5EcPVL1NbpjyVv8yah61EwxIPZRDlGwpGIkpIjH0Tk-CDtoKwFrDdP1v2AOpwmdoIz5oQzPEXCdyfGzcVXCHbwMX1fwPxMHpea5yFPUYEDlNWaCFlgLnejRdWeN5sB_lE=
|
Cookie: tt_csrf_token=bwnaRGd9-B-0ce8ntqw9jtGzAdvzTRKNpBl0; ak_bmsc=75A1956756DE42FD14ED069AAE7A8780~000000000000000000000000000000~YAAQXCw+F8jpmBGQAQAAIfGsFBj+ZEGzR/ZeiuPpMtItu0QQUQRmjBX2kADliy6QA9rZSfrxRUZc9zuRrI4/xbIrAwA/nkdguGpa+v3QSn/1sk5uP2aqLVm0eYB/SGNafa2h2QvIPbLNiSCRhgq1GalZJL4+udqDnyBRJWE74nin74bZwrVDvCX1s8M2hWqZ9/jTkdm4sfwON9MdJIEtjAPlddQ4gxoqjPoWhfnrm24dhPT4OjL1B8QP1mgurj7zJGspqD53VcjkAl65gHVxp3dwZ5WbPYpqrh9j8wo2u/Wh6uhX+0HWmkv5yVZyTyYQTl3/ilPp9G4CuIUi84gaPLjNYea9AEnphNX0ywzDa6/yegfqyE6r3wqBBDCrR1xRM98YEB4A5PV7pw==; tt_chain_token=ljZFLdRDfyfDflXMg5XGpg==; tiktok_webapp_theme_auto_dark_ab=1; tiktok_webapp_theme=dark; perf_feed_cache={%22expireTimestamp%22:1718503200000%2C%22itemIds%22:[%227348816520216186158%22%2C%227356022137678810410%22%2C%227349561209340857630%22]}; s_v_web_id=verify_lxe3l432_JnDE5WWo_URef_4WrS_88IM_fd1CqEXZs4dZ; passport_csrf_token=af197f073ed95f4dc2636f24d55566a6; passport_csrf_token_default=af197f073ed95f4dc2636f24d55566a6; ttwid=1%7CuNT4GcgvvOjH8rTETh9d9xti_QDJjlcnSK2V7djIpuc%7C1718333954%7Cf81b989a495aedff91302da4d0a3ab6055dea486fb203a4326b37d5a5346ad0c; msToken=1Mhpyi8MlaZjM6bbLDVUhCj_6C0kEO_1_Nb62ByXLg7wy_vLnBxdMFpKclhf4HYnEjCghk2Gq47ZM5jPj3L1yFxQUZvq4oPLo1b2Wfe_33RE94uIxdiR-eSueWbcYDDgOj1Pn9Wyid5Uf5fzBQ7xxFA=; bm_sv=9ADBA7BE06EC41817F117E2279F1410C~YAAQXCw+F8bsmBGQAQAAzSewFBg2fP3Zd0aky2x7S13D97O64xi8EXhoKORBnPQyCHlh0iSlh63FFjoy6peDWaF3lkWaTly3Z7I7WvWk1GCntnYzpJaSCE5EO2OL38zPWpHcgGWuekluvptHXsheedNEefN4SUHVMt4jJynWNeTKrao0RmNLkH4zGs7QO6+MPCt94QFvNfLjBRr0wVcXlN/hx9m6kcvCyzsBBqEnpugoYvZ0SMA+INsKI5PDfQz1~1; msToken=449_l3kdcLmnEHdDP0uACa5EcPVL1NbpjyVv8yah61EwxIPZRDlGwpGIkpIjH0Tk-CDtoKwFrDdP1v2AOpwmdoIz5oQzPEXCdyfGzcVXCHbwMX1fwPxMHpea5yFPUYEDlNWaCFlgLnejRdWeN5sB_lE=
|
||||||
|
|
||||||
proxies:
|
proxies:
|
||||||
@ -10,6 +12,8 @@ TokenManager:
|
|||||||
https:
|
https:
|
||||||
|
|
||||||
msToken:
|
msToken:
|
||||||
|
# 不要修改下面的内容。
|
||||||
|
# Do not modify the content below.
|
||||||
url: https://mssdk.tiktokw.us/web/report?msToken=1Ab-7YxR9lUHSem0PraI_XzdKmpHb6j50L8AaXLAd2aWTdoJCYLfX_67rVQFE4UwwHVHmyG_NfIipqrlLT3kCXps-5PYlNAqtdwEg7TrDyTAfCKyBrOLmhMUjB55oW8SPZ4_EkNxNFUdV7MquA==
|
url: https://mssdk.tiktokw.us/web/report?msToken=1Ab-7YxR9lUHSem0PraI_XzdKmpHb6j50L8AaXLAd2aWTdoJCYLfX_67rVQFE4UwwHVHmyG_NfIipqrlLT3kCXps-5PYlNAqtdwEg7TrDyTAfCKyBrOLmhMUjB55oW8SPZ4_EkNxNFUdV7MquA==
|
||||||
magic: 538969122
|
magic: 538969122
|
||||||
version: 1
|
version: 1
|
||||||
@ -18,6 +22,8 @@ TokenManager:
|
|||||||
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
|
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36
|
||||||
|
|
||||||
ttwid:
|
ttwid:
|
||||||
|
# 不要修改下面的内容。
|
||||||
|
# Do not modify the content below.
|
||||||
url: https://www.tiktok.com/ttwid/check/
|
url: https://www.tiktok.com/ttwid/check/
|
||||||
data: '{"aid":1988,"service":"www.tiktok.com","union":false,"unionHost":"","needFid":false,"fid":"","migrate_priority":0}'
|
data: '{"aid":1988,"service":"www.tiktok.com","union":false,"unionHost":"","needFid":false,"fid":"","migrate_priority":0}'
|
||||||
cookie: tt_csrf_token=YmksDB6a-h4cT2fF7JpORI2O9UBMCWjsntIc; ttwid=1%7C0FVb9fFc-sjDG2UdJwdC1AirqYozQ0xfbAS4N72vN2Y%7C1713886256%7C78a9d83445b82b73ca8d4e0cf024ea6cdf1329b7f3866c826b0a69a300ebce46; ak_bmsc=51B1D53481A3A4E4D0CEFF2BCF622DA2~000000000000000000000000000000~YAAQ7uIsF6c4j+SOAQAAANmUCxfRGVXZ4D9xnO97l1yDw0OWyomnVkNY7IUKaggUja0kQzFQ+WG4xaxBcPt0AN0n26KeHXGGKgHYpHPUMUBHGHQGDtE4RLyy7U+LPbSJCqVaSDiPuzxHht0YUIbWogvrFmBfkP4ohcmjkZxWtEI9qQ4Whaobb2CFHGdKNt0zlVNBjJQ3uYRAvUe12zSBynQB18y6QhE8goneRkCEw9VIeft2pFIwNQ8tkWWEjDt6wHNaqeND7eASg5WLzYskWbTt6bPAOhSNRLJ38HZrOB5QNg+xxN5uuCSYmjMXCl8SkvQr91pInmOng+V898FLLBQtefs95whvbpfE0mKwBk5Cz2TkkHcUJa/IoC0CLmNqoEk3AtKxpw/J; tt_chain_token=46Xkv2ukMzyJ2e7XU7y0AQ==; bm_sv=A2E67B998DE8E6A4F1C2C02485467446~YAAQ7uIsF6g4j+SOAQAABdqUCxf1J/K4dYG0k7bbw2m5rFujdlSqMoCKDubu4R602nFvbY6zWC5puJczBv3IXwJJRpQxxR03wDCMVlKTCqjQvgDs8BoCuoNQxfY2fdS+F3bKut2lxXPQ2qctqz4kHBrgspJArHn/zu/IuKCIeSzmV4KcyxW6Zvw3/xMRA0MeHgyuHsTRBS+VrFk8Ju2NbJWWC8uSHbLCM/dhFT7/ktw8RE30r24XpQmhLpVTsUSC~1; tiktok_webapp_theme=light; msToken=ySXERzKCE0QUG0cCg6TWLw3wfEB-6kh6kAfuzhzjcQvmV1jBFloSgIsT9xk-QXFVdI99U1Fqb9mhUpIOldoDkjdZwskB8rvt66MHZaHnvBRZRtOKtTYsWT8osDyQXDVZWdPkvyE598h9; passport_csrf_token=1a47d95ebf68fc3648b0018ee75afc9f; passport_csrf_token_default=1a47d95ebf68fc3648b0018ee75afc9f; perf_feed_cache={%22expireTimestamp%22:1714057200000%2C%22itemIds%22:[%227346425092966206766%22%2C%227353812964207594795%22%2C%227343343741916171563%22]}; msToken=yWwG-ITrCnjJbx5ltBa9FTXdCImOJrl-wtQJSQH3afeEumWZcbo_qcrF6F7-NjYcrG6JVxtJiOU208REZeCSgXEZrrs5_65K741fQ7PSzCGOhz6vUyycq3Xvj4Mu-S0kJ6SqyltHnpJp
|
cookie: tt_csrf_token=YmksDB6a-h4cT2fF7JpORI2O9UBMCWjsntIc; ttwid=1%7C0FVb9fFc-sjDG2UdJwdC1AirqYozQ0xfbAS4N72vN2Y%7C1713886256%7C78a9d83445b82b73ca8d4e0cf024ea6cdf1329b7f3866c826b0a69a300ebce46; ak_bmsc=51B1D53481A3A4E4D0CEFF2BCF622DA2~000000000000000000000000000000~YAAQ7uIsF6c4j+SOAQAAANmUCxfRGVXZ4D9xnO97l1yDw0OWyomnVkNY7IUKaggUja0kQzFQ+WG4xaxBcPt0AN0n26KeHXGGKgHYpHPUMUBHGHQGDtE4RLyy7U+LPbSJCqVaSDiPuzxHht0YUIbWogvrFmBfkP4ohcmjkZxWtEI9qQ4Whaobb2CFHGdKNt0zlVNBjJQ3uYRAvUe12zSBynQB18y6QhE8goneRkCEw9VIeft2pFIwNQ8tkWWEjDt6wHNaqeND7eASg5WLzYskWbTt6bPAOhSNRLJ38HZrOB5QNg+xxN5uuCSYmjMXCl8SkvQr91pInmOng+V898FLLBQtefs95whvbpfE0mKwBk5Cz2TkkHcUJa/IoC0CLmNqoEk3AtKxpw/J; tt_chain_token=46Xkv2ukMzyJ2e7XU7y0AQ==; bm_sv=A2E67B998DE8E6A4F1C2C02485467446~YAAQ7uIsF6g4j+SOAQAABdqUCxf1J/K4dYG0k7bbw2m5rFujdlSqMoCKDubu4R602nFvbY6zWC5puJczBv3IXwJJRpQxxR03wDCMVlKTCqjQvgDs8BoCuoNQxfY2fdS+F3bKut2lxXPQ2qctqz4kHBrgspJArHn/zu/IuKCIeSzmV4KcyxW6Zvw3/xMRA0MeHgyuHsTRBS+VrFk8Ju2NbJWWC8uSHbLCM/dhFT7/ktw8RE30r24XpQmhLpVTsUSC~1; tiktok_webapp_theme=light; msToken=ySXERzKCE0QUG0cCg6TWLw3wfEB-6kh6kAfuzhzjcQvmV1jBFloSgIsT9xk-QXFVdI99U1Fqb9mhUpIOldoDkjdZwskB8rvt66MHZaHnvBRZRtOKtTYsWT8osDyQXDVZWdPkvyE598h9; passport_csrf_token=1a47d95ebf68fc3648b0018ee75afc9f; passport_csrf_token_default=1a47d95ebf68fc3648b0018ee75afc9f; perf_feed_cache={%22expireTimestamp%22:1714057200000%2C%22itemIds%22:[%227346425092966206766%22%2C%227353812964207594795%22%2C%227343343741916171563%22]}; msToken=yWwG-ITrCnjJbx5ltBa9FTXdCImOJrl-wtQJSQH3afeEumWZcbo_qcrF6F7-NjYcrG6JVxtJiOU208REZeCSgXEZrrs5_65K741fQ7PSzCGOhz6vUyycq3Xvj4Mu-S0kJ6SqyltHnpJp
|
||||||
|
|||||||
@ -23,6 +23,7 @@ class BaseRequestModel(BaseModel):
|
|||||||
channel: str = "tiktok_web"
|
channel: str = "tiktok_web"
|
||||||
cookie_enabled: str = "true"
|
cookie_enabled: str = "true"
|
||||||
device_id: int = 7380187414842836523
|
device_id: int = 7380187414842836523
|
||||||
|
odinId: int = 7404669909585003563
|
||||||
device_platform: str = "web_pc"
|
device_platform: str = "web_pc"
|
||||||
focus_state: str = "true"
|
focus_state: str = "true"
|
||||||
from_page: str = "user"
|
from_page: str = "user"
|
||||||
@ -49,11 +50,47 @@ class UserProfile(BaseRequestModel):
|
|||||||
uniqueId: str
|
uniqueId: str
|
||||||
|
|
||||||
|
|
||||||
class UserPost(BaseRequestModel):
|
class UserPost(BaseModel):
|
||||||
|
WebIdLastTime: str = "1714385892"
|
||||||
|
aid: str = "1988"
|
||||||
|
app_language: str = "zh-Hans"
|
||||||
|
app_name: str = "tiktok_web"
|
||||||
|
browser_language: str = "zh-CN"
|
||||||
|
browser_name: str = "Mozilla"
|
||||||
|
browser_online: str = "true"
|
||||||
|
browser_platform: str = "Win32"
|
||||||
|
browser_version: str = "5.0%20%28Windows%29"
|
||||||
|
channel: str = "tiktok_web"
|
||||||
|
cookie_enabled: str = "true"
|
||||||
|
count: int = 20
|
||||||
coverFormat: int = 2
|
coverFormat: int = 2
|
||||||
count: int = 35
|
|
||||||
cursor: int = 0
|
cursor: int = 0
|
||||||
|
data_collection_enabled: str = "true"
|
||||||
|
device_id: str = "7380187414842836523"
|
||||||
|
device_platform: str = "web_pc"
|
||||||
|
focus_state: str = "true"
|
||||||
|
from_page: str = "user"
|
||||||
|
history_len: str = "3"
|
||||||
|
is_fullscreen: str = "false"
|
||||||
|
is_page_visible: str = "true"
|
||||||
|
language: str = "zh-Hans"
|
||||||
|
locate_item_id: str = ""
|
||||||
|
needPinnedItemIds: str = "true"
|
||||||
|
odinId: str = "7404669909585003563"
|
||||||
|
os: str = "windows"
|
||||||
|
# 0:默认排序,1:热门排序,2:最旧排序
|
||||||
|
post_item_list_request_type: int = 0
|
||||||
|
priority_region: str = "US"
|
||||||
|
referer: str = ""
|
||||||
|
region: str = "US"
|
||||||
|
screen_height: str = "827"
|
||||||
|
screen_width: str = "1323"
|
||||||
secUid: str
|
secUid: str
|
||||||
|
tz_name: str = "America%2FLos_Angeles"
|
||||||
|
user_is_login: str = "true"
|
||||||
|
webcast_language: str = "zh-Hans"
|
||||||
|
msToken: str = "SXtP7K0MMFlQmzpuWfZoxAlAaKqt-2p8oAbOHFBw-k3TA2g4jE_FXrFKf3i38lR-xNh_bV1_qfTPRnj4PXbkBfrVD2iAazeUkASIASHT0pu-Bx2_POx7O3nBBHZe2SI7CPsanerdclxHht1hcoUTlg%3D%3D"
|
||||||
|
_signature: str = "_02B4Z6wo000017oyWOQAAIDD9xNhTSnfaDu6MFxAAIlj23"
|
||||||
|
|
||||||
|
|
||||||
class UserLike(BaseRequestModel):
|
class UserLike(BaseRequestModel):
|
||||||
|
|||||||
@ -89,7 +89,8 @@ class TikTokWebCrawler:
|
|||||||
"Referer": tiktok_config["headers"]["Referer"],
|
"Referer": tiktok_config["headers"]["Referer"],
|
||||||
"Cookie": tiktok_config["headers"]["Cookie"],
|
"Cookie": tiktok_config["headers"]["Cookie"],
|
||||||
},
|
},
|
||||||
"proxies": {"http://": None, "https://": None},
|
"proxies": {"http://": tiktok_config["proxies"]["http"],
|
||||||
|
"https://": tiktok_config["proxies"]["https"]}
|
||||||
}
|
}
|
||||||
return kwargs
|
return kwargs
|
||||||
|
|
||||||
@ -133,7 +134,7 @@ class TikTokWebCrawler:
|
|||||||
kwargs = await self.get_tiktok_headers()
|
kwargs = await self.get_tiktok_headers()
|
||||||
# proxies = {"http://": 'http://43.159.29.191:24144', "https://": 'http://43.159.29.191:24144'}
|
# proxies = {"http://": 'http://43.159.29.191:24144', "https://": 'http://43.159.29.191:24144'}
|
||||||
# 创建一个基础爬虫
|
# 创建一个基础爬虫
|
||||||
base_crawler = BaseCrawler(proxies=None, crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
# 创建一个用户作品的BaseModel参数
|
# 创建一个用户作品的BaseModel参数
|
||||||
params = UserPost(secUid=secUid, cursor=cursor, count=count, coverFormat=coverFormat)
|
params = UserPost(secUid=secUid, cursor=cursor, count=count, coverFormat=coverFormat)
|
||||||
@ -216,7 +217,7 @@ class TikTokWebCrawler:
|
|||||||
kwargs = await self.get_tiktok_headers()
|
kwargs = await self.get_tiktok_headers()
|
||||||
# proxies = {"http://": 'http://43.159.18.174:25263', "https://": 'http://43.159.18.174:25263'}
|
# proxies = {"http://": 'http://43.159.18.174:25263', "https://": 'http://43.159.18.174:25263'}
|
||||||
# 创建一个基础爬虫
|
# 创建一个基础爬虫
|
||||||
base_crawler = BaseCrawler(proxies=None, crawler_headers=kwargs["headers"])
|
base_crawler = BaseCrawler(proxies=kwargs["proxies"], crawler_headers=kwargs["headers"])
|
||||||
async with base_crawler as crawler:
|
async with base_crawler as crawler:
|
||||||
# 创建一个作品评论的BaseModel参数
|
# 创建一个作品评论的BaseModel参数
|
||||||
params = PostComment(aweme_id=aweme_id, cursor=cursor, count=count, current_region=current_region)
|
params = PostComment(aweme_id=aweme_id, cursor=cursor, count=count, current_region=current_region)
|
||||||
@ -343,9 +344,9 @@ class TikTokWebCrawler:
|
|||||||
|
|
||||||
async def main(self):
|
async def main(self):
|
||||||
# 获取单个作品数据
|
# 获取单个作品数据
|
||||||
item_id = "7369296852669205791"
|
# item_id = "7369296852669205791"
|
||||||
response = await self.fetch_one_video(item_id)
|
# response = await self.fetch_one_video(item_id)
|
||||||
print(response)
|
# print(response)
|
||||||
|
|
||||||
# 获取用户的个人信息
|
# 获取用户的个人信息
|
||||||
# secUid = "MS4wLjABAAAAfDPs6wbpBcMMb85xkvDGdyyyVAUS2YoVCT9P6WQ1bpuwEuPhL9eFtTmGvxw1lT2C"
|
# secUid = "MS4wLjABAAAAfDPs6wbpBcMMb85xkvDGdyyyVAUS2YoVCT9P6WQ1bpuwEuPhL9eFtTmGvxw1lT2C"
|
||||||
|
|||||||
@ -34,4 +34,5 @@ ua-parser==0.18.0
|
|||||||
user-agents==2.2.0
|
user-agents==2.2.0
|
||||||
uvicorn==0.29.0
|
uvicorn==0.29.0
|
||||||
websockets==12.0
|
websockets==12.0
|
||||||
gmssl==3.2.2
|
gmssl==3.2.2
|
||||||
|
tenacity~=9.0.0
|
||||||
Loading…
x
Reference in New Issue
Block a user