mirror of
https://github.com/Evil0ctal/Douyin_TikTok_Download_API.git
synced 2025-04-22 08:20:54 +08:00
Move to new repo: Douyin_Tiktok_Scraper_PyPi
https://github.com/Evil0ctal/Douyin_Tiktok_Scraper_PyPi
This commit is contained in:
parent
fb41b811d3
commit
84c328ded9
21
PyPi/LICENSE
21
PyPi/LICENSE
@ -1,21 +0,0 @@
|
||||
MIT License
|
||||
|
||||
Copyright (c) 2021 Evil0ctal
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
353
PyPi/README.md
353
PyPi/README.md
@ -1,353 +0,0 @@
|
||||
<div align="center">
|
||||
<a href="https://douyin.wtf/" alt="logo" ><img src="./logo/logo192.png" width="120"/></a>
|
||||
</div>
|
||||
<h1 align="center">Douyin_TikTok_Download_API(抖音/TikTok API)</h1>
|
||||
|
||||
<div align="center">
|
||||
|
||||
[English](./README.en.md) | [简体中文](./README.md)
|
||||
|
||||
🚀「Douyin_TikTok_Download_API」是一个开箱即用的高性能异步[抖音](https://www.douyin.com)|[TikTok](https://www.tiktok.com)数据爬取工具,支持API调用,在线批量解析及下载。
|
||||
|
||||
[](LICENSE)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/releases/latest)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/stargazers)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/network/members)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues?q=is%3Aissue+is%3Aclosed)
|
||||

|
||||
<br>
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/#files)
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
<br>
|
||||
[](https://api.douyin.wtf/docs)
|
||||
[](https://api-v2.douyin.wtf/docs)
|
||||
<br>
|
||||
[](https://afdian.net/@evil0ctal)
|
||||
[](https://ko-fi.com/evil0ctal)
|
||||
[](https://www.patreon.com/evil0ctal)
|
||||
|
||||
</div>
|
||||
|
||||
## 👻介绍
|
||||
|
||||
> 🚨如需使用私有服务器运行本项目,请参考部署方式[[Docker部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker), [手动部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-linux)]
|
||||
|
||||
本项目是基于 [PyWebIO](https://github.com/pywebio/PyWebIO),[FastAPI](https://fastapi.tiangolo.com/),[AIOHTTP](https://docs.aiohttp.org/),快速异步的[抖音](https://www.douyin.com/)/[TikTok](https://www.tiktok.com/)数据爬取工具,并通过Web端实现在线批量解析以及下载无水印视频或图集,数据爬取API,iOS快捷指令无水印下载等功能。你可以自己部署或改造本项目实现更多功能,也可以在你的项目中直接调用[scraper.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/Stable/scraper.py)或安装现有的[pip包](https://pypi.org/project/douyin-tiktok-scraper/)作为解析库轻松爬取数据等.....
|
||||
|
||||
*一些简单的运用场景:*
|
||||
|
||||
*下载禁止下载的视频,进行数据分析,iOS无水印下载(搭配[iOS自带的快捷指令APP](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)
|
||||
配合本项目API实现应用内下载或读取剪贴板下载)等.....*
|
||||
|
||||
## 🖥公共站点: 我很脆弱...请勿压测(·•᷄ࡇ•᷅ )
|
||||
|
||||
> **API-V2:** 支持输入`Douyin|TikTok`用户主页爬取该作者[主页视频数据(去水印链接, 已点赞视频列表(权限需为公开), 视频评论数据, 背景音乐视频列表数据, 等等...), 详细信息请查看V2文档, 服务器响应时间有时会变长, 使用时请将`timeout`值设高.
|
||||
|
||||
🍔Web APP: [https://douyin.wtf/](https://douyin.wtf/)
|
||||
|
||||
🍟API-V1: [https://api.douyin.wtf/docs](https://api.douyin.wtf/docs)
|
||||
|
||||
🌭API-V2: [https://api-v2.douyin.wtf/docs](https://api-v2.douyin.wtf/docs)
|
||||
|
||||
💾iOS Shortcut(快捷指令): [Shortcut release](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/discussions/104?sort=top)
|
||||
|
||||
📦️桌面端下载器(仓库推荐):
|
||||
|
||||
- [Tairraos/TikDown](https://github.com/Tairraos/TikDown/)
|
||||
- [Johnserf-Seed/TikTokDownload](https://github.com/Johnserf-Seed/TikTokDownload)
|
||||
- [HFrost0/bilix](https://github.com/HFrost0/bilix)
|
||||
|
||||
## ⚗️技术栈
|
||||
|
||||
* [web_app.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/web_app.py) - [PyWebIO](https://www.pyweb.io/)
|
||||
* [web_api.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/web_api.py) - [FastAPI](https://fastapi.tiangolo.com/)
|
||||
* [scraper.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/scraper.py) - [AIOHTTP](https://docs.aiohttp.org/)
|
||||
|
||||
> ***scraper.py:***
|
||||
|
||||
- 向[Douyin|TikTok]的API提交请求并取回数据,处理后返回字典(dict),支持异步。
|
||||
|
||||
> ***web_api.py:***
|
||||
|
||||
- 获得请求参数并使用`Scraper()`类处理数据后以JSON形式返回,视频下载,配合iOS快捷指令实现快速调用,支持异步。
|
||||
|
||||
> ***web_app.py:***
|
||||
|
||||
- 为`web_api.py`以及`scraper.py`制作的简易Web程序,将网页输入的值进行处理后使用`Scraper()`类处理并配合`web_api.py`的接口输出在网页上(类似前后端分离)
|
||||
|
||||
***以上文件的参数大多可在[config.ini](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/config.ini)中进行修改***
|
||||
|
||||
## 💡项目文件结构
|
||||
|
||||
```
|
||||
.
|
||||
└── Douyin_TikTok_Download_API/
|
||||
├── /static -> (PyWebIO static resources)
|
||||
├── web_app.py -> (Web APP)
|
||||
├── web_api.py -> (API)
|
||||
├── scraper.py -> (Parsing library)
|
||||
├── config.ini -> (configuration file)
|
||||
```
|
||||
|
||||
## ✨功能:
|
||||
|
||||
- 抖音(抖音海外版: TikTok)视频/图片解析
|
||||
- 网页端批量解析(支持抖音/TikTok混合提交)
|
||||
- 网页端解析结果页批量下载无水印视频(V3.0.0暂时移除,请自行部署V2.X版本)
|
||||
- API调用获取链接数据
|
||||
- 制作[pip包](https://pypi.org/project/douyin-tiktok-scraper/)方便快速导入你的项目
|
||||
- [iOS快捷指令快速调用API](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)实现应用内下载无水印视频/图集
|
||||
- 解析作者主页内所有视频([API-V2](https://api-v2.douyin.wtf/docs) 支持抖音/TikTok)
|
||||
- 解析视频内所有评论信息([API-V2](https://api-v2.douyin.wtf/docs) 支持抖音/TikTok)
|
||||
|
||||
---
|
||||
|
||||
## 🤦待办清单:
|
||||
|
||||
> 💡欢迎提出新的建议或将你的思路在issue中与我分享,或直接提交PR至[Development分支](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/tree/Development) ♪(・ω・)ノ)
|
||||
|
||||
- [ ] 编写一个桌面端的下载器实现本地批量下载
|
||||
- [ ] API-V2添加对hash_tag页面的数据爬取 [#101](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/101)
|
||||
- [ ] 对其他短视频平台添加支持,如:抖音火山版,快手,西瓜视频,哔哩哔哩
|
||||
|
||||
---
|
||||
|
||||
## 📦调用解析库:
|
||||
|
||||
> 💡PyPi:[https://pypi.org/project/douyin-tiktok-scraper/](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
|
||||
安装解析库:`pip install douyin-tiktok-scraper`
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from douyin_tiktok_scraper.scraper import Scraper
|
||||
|
||||
api = Scraper()
|
||||
|
||||
async def hybrid_parsing(url: str) -> dict:
|
||||
# Hybrid parsing(Douyin/TikTok URL)
|
||||
result = await api.hybrid_parsing(url)
|
||||
print(f"The hybrid parsing result:\n {result}")
|
||||
return result
|
||||
|
||||
asyncio.run(hybrid_parsing(url=input("Paste Douyin/TikTok share URL here: ")))
|
||||
```
|
||||
|
||||
## 🗺️支持的提交格式:
|
||||
|
||||
> 💡提示:包含但不仅限于以下例子,如果遇到链接解析失败请开启一个新 [issue](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)
|
||||
|
||||
- 抖音分享口令 (APP内复制)
|
||||
|
||||
```text
|
||||
7.43 pda:/ 让你在几秒钟之内记住我 https://v.douyin.com/L5pbfdP/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
```
|
||||
|
||||
- 抖音短网址 (APP内复制)
|
||||
|
||||
```text
|
||||
https://v.douyin.com/L4FJNR3/
|
||||
```
|
||||
|
||||
- 抖音正常网址 (网页版复制)
|
||||
|
||||
```text
|
||||
https://www.douyin.com/video/6914948781100338440
|
||||
```
|
||||
|
||||
- 抖音发现页网址 (APP复制)
|
||||
|
||||
```text
|
||||
https://www.douyin.com/discover?modal_id=7069543727328398622
|
||||
```
|
||||
|
||||
- TikTok短网址 (APP内复制)
|
||||
|
||||
```text
|
||||
https://www.tiktok.com/t/ZTR9nDNWq/
|
||||
```
|
||||
|
||||
- TikTok正常网址 (网页版复制)
|
||||
|
||||
```text
|
||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||
```
|
||||
|
||||
- 抖音/TikTok批量网址(无需使用符合隔开)
|
||||
|
||||
```text
|
||||
https://v.douyin.com/L4NpDJ6/
|
||||
https://www.douyin.com/video/7126745726494821640
|
||||
2.84 nqe:/ 骑白马的也可以是公主%%百万转场变身https://v.douyin.com/L4FJNR3/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
https://www.tiktok.com/t/ZTR9nkkmL/
|
||||
https://www.tiktok.com/t/ZTR9nDNWq/
|
||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||
```
|
||||
|
||||
## 🛰️API文档
|
||||
|
||||
> 💡提示:也可以在web_api.py的代码注释中查看接口文档
|
||||
|
||||
***API-V1文档:***
|
||||
本地:[http://localhost:8000/docs](http://localhost:8000/docs)
|
||||
在线:[https://api.douyin.wtf/docs](https://api.douyin.wtf/docs)
|
||||
|
||||
***API-V2文档:***
|
||||
在线:[https://api-v2.douyin.wtf/docs](https://api-v2.douyin.wtf/docs)
|
||||
|
||||
***API演示:***
|
||||
|
||||
- 爬取视频数据(TikTok或Douyin混合解析)
|
||||
`https://api.douyin.wtf/api?url=[视频链接/Video URL]&minimal=false`
|
||||
- 下载视频/图集(TikTok或Douyin混合解析)
|
||||
`https://api.douyin.wtf/download?url=[视频链接/Video URL]&prefix=true&watermark=false`
|
||||
- 替换域名下载视频/图集
|
||||
|
||||
```
|
||||
[抖音]
|
||||
原始链接:
|
||||
https://www.douyin.com/video/7159502929156705567
|
||||
替换域名:
|
||||
https://api.douyin.wtf/video/7159502929156705567
|
||||
# 返回无水印视频下载响应
|
||||
[TikTok]
|
||||
original link:
|
||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||
Replace Domain:
|
||||
https://api.douyin.wtf/@evil0ctal/video/7156033831819037994
|
||||
# Return No Watermark Video Download Response
|
||||
```
|
||||
|
||||
***更多演示请查看文档内容......***
|
||||
|
||||
## 💻部署(方式一 Linux)
|
||||
|
||||
> 💡提示:最好将本项目部署至美国地区的服务器,否则可能会出现奇怪的BUG。
|
||||
|
||||
- 首先要去安全组开放8080(Web)和8000(API)端口。
|
||||
- 在宝塔面板应用商店内搜索`进程守护`或手动安装`supervisord`:
|
||||
|
||||
```
|
||||
[宝塔面板]
|
||||
https://www.bt.cn/new/download.html
|
||||
[aapanel]
|
||||
https://www.aapanel.com/new/download.html
|
||||
[Supervisor]
|
||||
http://supervisord.org/installing.html
|
||||
```
|
||||
|
||||
- 配置项目[config.ini](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/config.ini)文件
|
||||
- 安装依赖文件`pip install -r requirements.txt`
|
||||
- 设置`supervisord`守护进程
|
||||
- 启动命令:
|
||||
|
||||
```console
|
||||
[Web]
|
||||
python3 web_app.py
|
||||
[API]
|
||||
python3 web_api.py
|
||||
```
|
||||
|
||||
- 程序入口:
|
||||
|
||||
```text
|
||||
[Web]
|
||||
http://localhost:8080
|
||||
[API]
|
||||
http://localhost:8000
|
||||
```
|
||||
|
||||
## 💽部署(方式二 Docker)
|
||||
|
||||
> 💡Docker Image repo: [Docker Hub](https://hub.docker.com/repository/docker/evil0ctal/douyin_tiktok_download_api)
|
||||
|
||||
- 安装docker
|
||||
|
||||
```yaml
|
||||
curl -fsSL get.docker.com -o get-docker.sh&&sh get-docker.sh &&systemctl enable docker&&systemctl start docker
|
||||
```
|
||||
|
||||
- 留下config.int和docker-compose.yml文件即可
|
||||
- 运行命令,让容器在后台运行
|
||||
|
||||
```yaml
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
- 查看容器日志
|
||||
|
||||
```yaml
|
||||
docker logs -f douyin_tiktok_download_api
|
||||
```
|
||||
|
||||
- 删除容器
|
||||
|
||||
```yaml
|
||||
docker rm -f douyin_tiktok_download_api
|
||||
```
|
||||
|
||||
- 更新
|
||||
|
||||
```yaml
|
||||
docker compose pull && docker compose down && docker compose up -d
|
||||
```
|
||||
|
||||
## ❤️ 贡献者
|
||||
|
||||
[](https://github.com/Evil0ctal)
|
||||
[](https://github.com/jw-star)
|
||||
[](https://github.com/Jeffrey-deng)
|
||||
[](https://github.com/chris-ss)
|
||||
[](https://github.com/weixuan00)
|
||||
[](https://github.com/Tairraos)
|
||||
|
||||
## 📸截图
|
||||
|
||||
***API速度测试(对比官方API)***
|
||||
|
||||
<details><summary>🔎点击展开截图</summary>
|
||||
|
||||
抖音官方API:
|
||||

|
||||
|
||||
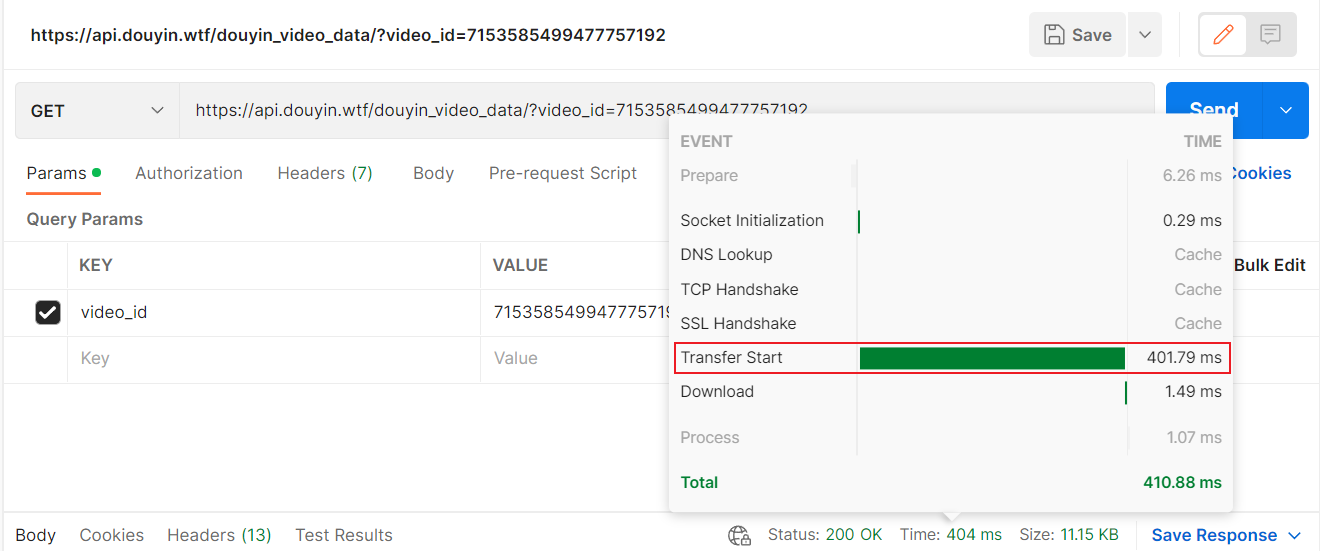
本项目API:
|
||||
|
||||
|
||||
TikTok官方API:
|
||||

|
||||
|
||||
本项目API:
|
||||

|
||||
|
||||
</details>
|
||||
<hr>
|
||||
|
||||
***项目界面***
|
||||
|
||||
<details><summary>🔎点击展开截图</summary>
|
||||
|
||||
Web主界面:
|
||||
|
||||

|
||||
|
||||
Web main interface:
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
<hr>
|
||||
|
||||
## 📜 Star历史
|
||||
|
||||
[](https://star-history.com/#Evil0ctal/Douyin_TikTok_Download_API&Timeline)
|
||||
|
||||
[MIT License](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/Stable/LICENSE)
|
||||
|
||||
> Start: 2021/11/06
|
||||
> GitHub: [@Evil0ctal](https://github.com/Evil0ctal)
|
||||
> Contact: Evil0ctal1985@gmail.com
|
||||
|
||||
|
||||
@ -1,555 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- encoding: utf-8 -*-
|
||||
# @Author: https://github.com/Evil0ctal/
|
||||
# @Time: 2021/11/06
|
||||
# @Update: 2022/12/09
|
||||
# @Version: 3.1.5
|
||||
# @Function:
|
||||
# 核心代码,估值1块(๑•̀ㅂ•́)و✧
|
||||
# 用于爬取Douyin/TikTok数据并以字典形式返回。
|
||||
# input link, output dictionary.
|
||||
|
||||
|
||||
import re
|
||||
import os
|
||||
import random
|
||||
import aiohttp
|
||||
import platform
|
||||
import asyncio
|
||||
import orjson
|
||||
import traceback
|
||||
import configparser
|
||||
|
||||
from typing import Union
|
||||
from tenacity import *
|
||||
|
||||
|
||||
class Scraper:
|
||||
"""
|
||||
简介/Introduction
|
||||
|
||||
Scraper.get_url(text: str) -> Union[str, None]
|
||||
用于检索出文本中的链接并返回/Used to retrieve the link in the text and return it.
|
||||
|
||||
Scraper.convert_share_urls(self, url: str) -> Union[str, None]\n
|
||||
用于转换分享链接为原始链接/Convert share links to original links
|
||||
|
||||
Scraper.get_douyin_video_id(self, original_url: str) -> Union[str, None]\n
|
||||
用于获取抖音视频ID/Get Douyin video ID
|
||||
|
||||
Scraper.get_douyin_video_data(self, video_id: str) -> Union[dict, None]\n
|
||||
用于获取抖音视频数据/Get Douyin video data
|
||||
|
||||
Scraper.get_douyin_live_video_data(self, original_url: str) -> Union[str, None]\n
|
||||
用于获取抖音直播视频数据/Get Douyin live video data
|
||||
|
||||
Scraper.get_tiktok_video_id(self, original_url: str) -> Union[str, None]\n
|
||||
用于获取TikTok视频ID/Get TikTok video ID
|
||||
|
||||
Scraper.get_tiktok_video_data(self, video_id: str) -> Union[dict, None]\n
|
||||
用于获取TikTok视频数据/Get TikTok video data
|
||||
|
||||
Scraper.hybrid_parsing(self, video_url: str) -> dict\n
|
||||
用于混合解析/ Hybrid parsing
|
||||
|
||||
Scraper.hybrid_parsing_minimal(data: dict) -> dict\n
|
||||
用于混合解析最小化/Hybrid parsing minimal
|
||||
"""
|
||||
|
||||
"""__________________________________________⬇️initialization(初始化)⬇️______________________________________"""
|
||||
|
||||
# 初始化/initialization
|
||||
def __init__(self):
|
||||
self.headers = {
|
||||
'User-Agent': "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36 Edg/87.0.664.66"
|
||||
}
|
||||
self.douyin_cookies = {
|
||||
'Cookie': 'msToken=tsQyL2_m4XgtIij2GZfyu8XNXBfTGELdreF1jeIJTyktxMqf5MMIna8m1bv7zYz4pGLinNP2TvISbrzvFubLR8khwmAVLfImoWo3Ecnl_956MgOK9kOBdwM=; odin_tt=6db0a7d68fd2147ddaf4db0b911551e472d698d7b84a64a24cf07c49bdc5594b2fb7a42fd125332977218dd517a36ec3c658f84cebc6f806032eff34b36909607d5452f0f9d898810c369cd75fd5fb15; ttwid=1%7CfhiqLOzu_UksmD8_muF_TNvFyV909d0cw8CSRsmnbr0%7C1662368529%7C048a4e969ec3570e84a5faa3518aa7e16332cfc7fbcb789780135d33a34d94d2'
|
||||
}
|
||||
self.tiktok_api_headers = {
|
||||
'User-Agent': 'com.ss.android.ugc.trill/494+Mozilla/5.0+(Linux;+Android+12;+2112123G+Build/SKQ1.211006.001;+wv)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Version/4.0+Chrome/107.0.5304.105+Mobile+Safari/537.36'
|
||||
}
|
||||
# 判断配置文件是否存在/Check if the configuration file exists
|
||||
if os.path.exists('config.ini'):
|
||||
self.config = configparser.ConfigParser()
|
||||
self.config.read('config.ini', encoding='utf-8')
|
||||
# 判断是否使用代理
|
||||
if self.config['Scraper']['Proxy_switch'] == 'True':
|
||||
# 判断是否区别协议选择代理
|
||||
if self.config['Scraper']['Use_different_protocols'] == 'False':
|
||||
self.proxies = {
|
||||
'all': self.config['Scraper']['All']
|
||||
}
|
||||
else:
|
||||
self.proxies = {
|
||||
'http': self.config['Scraper']['Http_proxy'],
|
||||
'https': self.config['Scraper']['Https_proxy'],
|
||||
}
|
||||
else:
|
||||
self.proxies = None
|
||||
# 配置文件不存在则不使用代理/If the configuration file does not exist, do not use the proxy
|
||||
else:
|
||||
self.proxies = None
|
||||
# 针对Windows系统的异步事件规则/Asynchronous event rules for Windows systems
|
||||
if platform.system() == 'Windows':
|
||||
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
|
||||
|
||||
"""__________________________________________⬇️utils(实用程序)⬇️______________________________________"""
|
||||
|
||||
# 检索字符串中的链接
|
||||
@staticmethod
|
||||
def get_url(text: str) -> Union[str, None]:
|
||||
try:
|
||||
# 从输入文字中提取索引链接存入列表/Extract index links from input text and store in list
|
||||
url = re.findall('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', text)
|
||||
# 判断是否有链接/Check if there is a link
|
||||
if len(url) > 0:
|
||||
return url[0]
|
||||
except Exception as e:
|
||||
print('Error in get_url:', e)
|
||||
return None
|
||||
|
||||
# 转换链接/convert url
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def convert_share_urls(self, url: str) -> Union[str, None]:
|
||||
"""
|
||||
用于将分享链接(短链接)转换为原始链接/Convert share links (short links) to original links
|
||||
:return: 原始链接/Original link
|
||||
"""
|
||||
# 检索字符串中的链接/Retrieve links from string
|
||||
url = self.get_url(url)
|
||||
# 判断是否有链接/Check if there is a link
|
||||
if url is None:
|
||||
print('无法检索到链接/Unable to retrieve link')
|
||||
return None
|
||||
# 判断是否为抖音分享链接/judge if it is a douyin share link
|
||||
if 'douyin' in url:
|
||||
"""
|
||||
抖音视频链接类型(不全):
|
||||
1. https://v.douyin.com/MuKhKn3/
|
||||
2. https://www.douyin.com/video/7157519152863890719
|
||||
3. https://www.iesdouyin.com/share/video/7157519152863890719/?region=CN&mid=7157519152863890719&u_code=ffe6jgjg&titleType=title×tamp=1600000000&utm_source=copy_link&utm_campaign=client_share&utm_medium=android&app=aweme&iid=123456789&share_id=123456789
|
||||
抖音用户链接类型(不全):
|
||||
1. https://www.douyin.com/user/MS4wLjABAAAAbLMPpOhVk441et7z7ECGcmGrK42KtoWOuR0_7pLZCcyFheA9__asY-kGfNAtYqXR?relation=0&vid=7157519152863890719
|
||||
2. https://v.douyin.com/MuKoFP4/
|
||||
抖音直播链接类型(不全):
|
||||
1. https://live.douyin.com/88815422890
|
||||
"""
|
||||
if 'v.douyin' in url:
|
||||
# 转换链接/convert url
|
||||
# 例子/Example: https://v.douyin.com/rLyAJgf/8.74
|
||||
url = re.compile(r'(https://v.douyin.com/)\w+', re.I).match(url).group()
|
||||
print('正在通过抖音分享链接获取原始链接...')
|
||||
try:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url, headers=self.headers, proxy=self.proxies, allow_redirects=False,
|
||||
timeout=10) as response:
|
||||
if response.status == 302:
|
||||
url = response.headers['Location'].split('?')[0] if '?' in response.headers[
|
||||
'Location'] else \
|
||||
response.headers['Location']
|
||||
print('获取原始链接成功, 原始链接为: {}'.format(url))
|
||||
return url
|
||||
except Exception as e:
|
||||
print('获取原始链接失败!')
|
||||
print(e)
|
||||
return None
|
||||
else:
|
||||
print('该链接为原始链接,无需转换,原始链接为: {}'.format(url))
|
||||
return url
|
||||
# 判断是否为TikTok分享链接/judge if it is a TikTok share link
|
||||
elif 'tiktok' in url:
|
||||
"""
|
||||
TikTok视频链接类型(不全):
|
||||
1. https://www.tiktok.com/@tiktok/video/6950000000000000000
|
||||
2. https://www.tiktok.com/t/ZTRHcXS2C/
|
||||
TikTok用户链接类型(不全):
|
||||
1. https://www.tiktok.com/@tiktok
|
||||
"""
|
||||
if '@' in url:
|
||||
print('该链接为原始链接,无需转换,原始链接为: {}'.format(url))
|
||||
return url
|
||||
else:
|
||||
print('正在通过TikTok分享链接获取原始链接...')
|
||||
try:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url, headers=self.headers, proxy=self.proxies, allow_redirects=False,
|
||||
timeout=10) as response:
|
||||
if response.status == 301:
|
||||
url = response.headers['Location'].split('?')[0] if '?' in response.headers[
|
||||
'Location'] else \
|
||||
response.headers['Location']
|
||||
print('获取原始链接成功, 原始链接为: {}'.format(url))
|
||||
return url
|
||||
except Exception as e:
|
||||
print('获取原始链接失败!')
|
||||
print(e)
|
||||
return None
|
||||
|
||||
"""__________________________________________⬇️Douyin methods(抖音方法)⬇️______________________________________"""
|
||||
|
||||
# 获取抖音视频ID/Get Douyin video ID
|
||||
async def get_douyin_video_id(self, original_url: str) -> Union[str, None]:
|
||||
"""
|
||||
获取视频id
|
||||
:param original_url: 视频链接
|
||||
:return: 视频id
|
||||
"""
|
||||
# 正则匹配出视频ID
|
||||
try:
|
||||
video_url = await self.convert_share_urls(original_url)
|
||||
# 链接类型:
|
||||
# 视频页 https://www.douyin.com/video/7086770907674348841
|
||||
if '/video/' in video_url:
|
||||
key = re.findall('/video/(\d+)?', video_url)[0]
|
||||
print('获取到的抖音视频ID为: {}'.format(key))
|
||||
return key
|
||||
# 发现页 https://www.douyin.com/discover?modal_id=7086770907674348841
|
||||
elif 'discover?' in video_url:
|
||||
key = re.findall('modal_id=(\d+)', video_url)[0]
|
||||
print('获取到的抖音视频ID为: {}'.format(key))
|
||||
return key
|
||||
# 直播页
|
||||
elif 'live.douyin' in video_url:
|
||||
# https://live.douyin.com/1000000000000000000
|
||||
key = video_url.replace('https://live.douyin.com/', '')
|
||||
print('获取到的抖音直播ID为: {}'.format(key))
|
||||
return key
|
||||
# note
|
||||
elif 'note' in video_url:
|
||||
# https://www.douyin.com/note/7086770907674348841
|
||||
key = re.findall('/note/(\d+)?', video_url)[0]
|
||||
print('获取到的抖音笔记ID为: {}'.format(key))
|
||||
return key
|
||||
except Exception as e:
|
||||
print('获取抖音视频ID出错了:{}'.format(e))
|
||||
return None
|
||||
|
||||
# 获取单个抖音视频数据/Get single Douyin video data
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def get_douyin_video_data(self, video_id: str) -> Union[dict, None]:
|
||||
"""
|
||||
:param video_id: str - 抖音视频id
|
||||
:return:dict - 包含信息的字典
|
||||
"""
|
||||
print('正在获取抖音视频数据...')
|
||||
try:
|
||||
# 构造访问链接/Construct the access link
|
||||
api_url = f"https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={video_id}"
|
||||
# 访问API/Access API
|
||||
print("正在获取视频数据API: {}".format(api_url))
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(api_url, headers=self.headers, proxy=self.proxies, timeout=10) as response:
|
||||
response = await response.json()
|
||||
# 获取视频数据/Get video data
|
||||
video_data = response['item_list'][0]
|
||||
print('获取视频数据成功!')
|
||||
# print("抖音API返回数据: {}".format(video_data))
|
||||
return video_data
|
||||
except Exception as e:
|
||||
print('获取抖音视频数据失败!原因:{}'.format(e))
|
||||
return None
|
||||
|
||||
# 获取单个抖音直播视频数据/Get single Douyin Live video data
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def get_douyin_live_video_data(self, web_rid: str) -> Union[dict, None]:
|
||||
print('正在获取抖音视频数据...')
|
||||
try:
|
||||
# 构造访问链接/Construct the access link
|
||||
api_url = f"https://live.douyin.com/webcast/web/enter/?aid=6383&web_rid={web_rid}"
|
||||
# 访问API/Access API
|
||||
print("正在获取视频数据API: {}".format(api_url))
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(api_url, headers=self.douyin_cookies, proxy=self.proxies, timeout=10) as response:
|
||||
response = await response.json()
|
||||
# 获取返回的json数据/Get the returned json data
|
||||
data = orjson.loads(response.text)
|
||||
# 获取视频数据/Get video data
|
||||
video_data = data['data']
|
||||
print('获取视频数据成功!')
|
||||
# print("抖音API返回数据: {}".format(video_data))
|
||||
return video_data
|
||||
except Exception as e:
|
||||
print('获取抖音视频数据失败!原因:{}'.format(e))
|
||||
return None
|
||||
|
||||
"""__________________________________________⬇️TikTok methods(TikTok方法)⬇️______________________________________"""
|
||||
|
||||
# 获取TikTok视频ID/Get TikTok video ID
|
||||
async def get_tiktok_video_id(self, original_url: str) -> Union[str, None]:
|
||||
"""
|
||||
获取视频id
|
||||
:param original_url: 视频链接
|
||||
:return: 视频id
|
||||
"""
|
||||
try:
|
||||
# 转换链接/Convert link
|
||||
original_url = await self.convert_share_urls(original_url)
|
||||
# 获取视频ID/Get video ID
|
||||
if '.html' in original_url:
|
||||
video_id = original_url.replace('.html', '')
|
||||
elif '/video/' in original_url:
|
||||
video_id = re.findall('/video/(\d+)', original_url)[0]
|
||||
elif '/v/' in original_url:
|
||||
video_id = re.findall('/v/(\d+)', original_url)[0]
|
||||
print('获取到的TikTok视频ID是{}'.format(video_id))
|
||||
# 返回视频ID/Return video ID
|
||||
return video_id
|
||||
except Exception as e:
|
||||
print('获取TikTok视频ID出错了:{}'.format(e))
|
||||
return None
|
||||
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def get_tiktok_video_data(self, video_id: str) -> Union[dict, None]:
|
||||
"""
|
||||
获取单个视频信息
|
||||
:param video_id: 视频id
|
||||
:return: 视频信息
|
||||
"""
|
||||
print('正在获取TikTok视频数据...')
|
||||
try:
|
||||
# 构造访问链接/Construct the access link
|
||||
api_url = f'https://api16-normal-c-useast1a.tiktokv.com/aweme/v1/feed/?aweme_id={video_id}&iid=6165993682518218889&device_id={random.randint(10*10*10, 9*10**10)}&aid=1180'
|
||||
print("正在获取视频数据API: {}".format(api_url))
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(api_url, headers=self.tiktok_api_headers, proxy=self.proxies, timeout=10) as response:
|
||||
response = await response.json()
|
||||
video_data = response['aweme_list'][0]
|
||||
print('获取视频信息成功!')
|
||||
return video_data
|
||||
except Exception as e:
|
||||
print('获取视频信息失败!原因:{}'.format(e))
|
||||
return None
|
||||
|
||||
"""__________________________________________⬇️Hybrid methods(混合方法)⬇️______________________________________"""
|
||||
|
||||
# 自定义获取数据/Custom data acquisition
|
||||
async def hybrid_parsing(self, video_url: str) -> dict:
|
||||
# URL平台判断/Judge URL platform
|
||||
url_platform = 'douyin' if 'douyin' in video_url else 'tiktok'
|
||||
print('当前链接平台为:{}'.format(url_platform))
|
||||
# 获取视频ID/Get video ID
|
||||
print("正在获取视频ID...")
|
||||
video_id = await self.get_douyin_video_id(
|
||||
video_url) if url_platform == 'douyin' else await self.get_tiktok_video_id(
|
||||
video_url)
|
||||
if video_id:
|
||||
print("获取视频ID成功,视频ID为:{}".format(video_id))
|
||||
# 获取视频数据/Get video data
|
||||
print("正在获取视频数据...")
|
||||
data = await self.get_douyin_video_data(
|
||||
video_id) if url_platform == 'douyin' else await self.get_tiktok_video_data(
|
||||
video_id)
|
||||
if data:
|
||||
print("获取视频数据成功,正在判断数据类型...")
|
||||
url_type_code = data['aweme_type']
|
||||
"""以下为抖音/TikTok类型代码/Type code for Douyin/TikTok"""
|
||||
url_type_code_dict = {
|
||||
# 抖音/Douyin
|
||||
2: 'image',
|
||||
4: 'video',
|
||||
# TikTok
|
||||
0: 'video',
|
||||
51: 'video',
|
||||
55: 'video',
|
||||
58: 'video',
|
||||
61: 'video',
|
||||
150: 'image'
|
||||
}
|
||||
# 获取视频类型/Get video type
|
||||
# 如果类型代码不存在,则默认为视频类型/If the type code does not exist, it is assumed to be a video type
|
||||
print("数据类型代码: {}".format(url_type_code))
|
||||
# 判断链接类型/Judge link type
|
||||
url_type = url_type_code_dict.get(url_type_code, 'video')
|
||||
print("数据类型: {}".format(url_type))
|
||||
print("准备开始判断并处理数据...")
|
||||
|
||||
"""
|
||||
以下为(视频||图片)数据处理的四个方法,如果你需要自定义数据处理请在这里修改.
|
||||
The following are four methods of (video || image) data processing.
|
||||
If you need to customize data processing, please modify it here.
|
||||
"""
|
||||
|
||||
"""
|
||||
创建已知数据字典(索引相同),稍后使用.update()方法更新数据
|
||||
Create a known data dictionary (index the same),
|
||||
and then use the .update() method to update the data
|
||||
"""
|
||||
|
||||
result_data = {
|
||||
'status': 'success',
|
||||
'message': "更多接口请查看(More API see): https://api-v2.douyin.wtf/docs",
|
||||
'type': url_type,
|
||||
'platform': url_platform,
|
||||
'aweme_id': video_id,
|
||||
'official_api_url':
|
||||
{
|
||||
"User-Agent": self.headers["User-Agent"],
|
||||
"api_url": f"https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={video_id}"
|
||||
} if url_platform == 'douyin'
|
||||
else
|
||||
{
|
||||
"User-Agent": self.tiktok_api_headers["User-Agent"],
|
||||
"api_url": f'https://api16-normal-c-useast1a.tiktokv.com/aweme/v1/feed/?aweme_id={video_id}&iid=6165993682518218889&device_id={random.randint(10*10*10, 9*10**10)}&aid=1180'
|
||||
},
|
||||
'desc': data.get("desc"),
|
||||
'create_time': data.get("create_time"),
|
||||
'author': data.get("author"),
|
||||
'music': data.get("music"),
|
||||
'statistics': data.get("statistics"),
|
||||
'cover_data': {
|
||||
'cover': data.get("video").get("cover"),
|
||||
'origin_cover': data.get("video").get("origin_cover"),
|
||||
'dynamic_cover': data.get("video").get("dynamic_cover")
|
||||
},
|
||||
'hashtags': data.get('text_extra'),
|
||||
}
|
||||
# 创建一个空变量,稍后使用.update()方法更新数据/Create an empty variable and use the .update() method to update the data
|
||||
api_data = None
|
||||
# 判断链接类型并处理数据/Judge link type and process data
|
||||
try:
|
||||
# 抖音数据处理/Douyin data processing
|
||||
if url_platform == 'douyin':
|
||||
# 抖音视频数据处理/Douyin video data processing
|
||||
if url_type == 'video':
|
||||
print("正在处理抖音视频数据...")
|
||||
# 将信息储存在字典中/Store information in a dictionary
|
||||
uri = data['video']['play_addr']['uri']
|
||||
wm_video_url = data['video']['play_addr']['url_list'][0]
|
||||
wm_video_url_HQ = f"https://aweme.snssdk.com/aweme/v1/playwm/?video_id={uri}&radio=1080p&line=0"
|
||||
nwm_video_url = wm_video_url.replace('playwm', 'play')
|
||||
nwm_video_url_HQ = f"https://aweme.snssdk.com/aweme/v1/play/?video_id={uri}&ratio=1080p&line=0"
|
||||
api_data = {
|
||||
'video_data':
|
||||
{
|
||||
'wm_video_url': wm_video_url,
|
||||
'wm_video_url_HQ': wm_video_url_HQ,
|
||||
'nwm_video_url': nwm_video_url,
|
||||
'nwm_video_url_HQ': nwm_video_url_HQ
|
||||
}
|
||||
}
|
||||
# 抖音图片数据处理/Douyin image data processing
|
||||
elif url_type == 'image':
|
||||
print("正在处理抖音图片数据...")
|
||||
# 无水印图片列表/No watermark image list
|
||||
no_watermark_image_list = []
|
||||
# 有水印图片列表/With watermark image list
|
||||
watermark_image_list = []
|
||||
# 遍历图片列表/Traverse image list
|
||||
for i in data['images']:
|
||||
no_watermark_image_list.append(i['url_list'][0])
|
||||
watermark_image_list.append(i['download_url_list'][0])
|
||||
api_data = {
|
||||
'image_data':
|
||||
{
|
||||
'no_watermark_image_list': no_watermark_image_list,
|
||||
'watermark_image_list': watermark_image_list
|
||||
}
|
||||
}
|
||||
# TikTok数据处理/TikTok data processing
|
||||
elif url_platform == 'tiktok':
|
||||
# TikTok视频数据处理/TikTok video data processing
|
||||
if url_type == 'video':
|
||||
print("正在处理TikTok视频数据...")
|
||||
# 将信息储存在字典中/Store information in a dictionary
|
||||
wm_video = data['video']['download_addr']['url_list'][0]
|
||||
api_data = {
|
||||
'video_data':
|
||||
{
|
||||
'wm_video_url': wm_video,
|
||||
'wm_video_url_HQ': wm_video,
|
||||
'nwm_video_url': data['video']['play_addr']['url_list'][0],
|
||||
'nwm_video_url_HQ': data['video']['bit_rate'][0]['play_addr']['url_list'][0]
|
||||
}
|
||||
}
|
||||
# TikTok图片数据处理/TikTok image data processing
|
||||
elif url_type == 'image':
|
||||
print("正在处理TikTok图片数据...")
|
||||
# 无水印图片列表/No watermark image list
|
||||
no_watermark_image_list = []
|
||||
# 有水印图片列表/With watermark image list
|
||||
watermark_image_list = []
|
||||
for i in data['image_post_info']['images']:
|
||||
no_watermark_image_list.append(i['display_image']['url_list'][0])
|
||||
watermark_image_list.append(i['owner_watermark_image']['url_list'][0])
|
||||
api_data = {
|
||||
'image_data':
|
||||
{
|
||||
'no_watermark_image_list': no_watermark_image_list,
|
||||
'watermark_image_list': watermark_image_list
|
||||
}
|
||||
}
|
||||
# 更新数据/Update data
|
||||
result_data.update(api_data)
|
||||
# print("数据处理完成,最终数据: \n{}".format(result_data))
|
||||
# 返回数据/Return data
|
||||
return result_data
|
||||
except Exception as e:
|
||||
traceback.print_exc()
|
||||
print("数据处理失败!")
|
||||
return {'status': 'failed', 'message': '数据处理失败!/Data processing failed!'}
|
||||
else:
|
||||
print("[抖音|TikTok方法]返回数据为空,无法处理!")
|
||||
return {'status': 'failed',
|
||||
'message': '返回数据为空,无法处理!/Return data is empty and cannot be processed!'}
|
||||
else:
|
||||
print('获取视频ID失败!')
|
||||
return {'status': 'failed', 'message': '获取视频ID失败!/Failed to get video ID!'}
|
||||
|
||||
# 处理数据方便快捷指令使用/Process data for easy-to-use shortcuts
|
||||
@staticmethod
|
||||
def hybrid_parsing_minimal(data: dict) -> dict:
|
||||
# 如果数据获取成功/If the data is successfully obtained
|
||||
if data['status'] == 'success':
|
||||
result = {
|
||||
'status': 'success',
|
||||
'message': data.get('message'),
|
||||
'platform': data.get('platform'),
|
||||
'type': data.get('type'),
|
||||
'desc': data.get('desc'),
|
||||
'wm_video_url': data['video_data']['wm_video_url'] if data['type'] == 'video' else None,
|
||||
'wm_video_url_HQ': data['video_data']['wm_video_url_HQ'] if data['type'] == 'video' else None,
|
||||
'nwm_video_url': data['video_data']['nwm_video_url'] if data['type'] == 'video' else None,
|
||||
'nwm_video_url_HQ': data['video_data']['nwm_video_url_HQ'] if data['type'] == 'video' else None,
|
||||
'no_watermark_image_list': data['image_data']['no_watermark_image_list'] if data[
|
||||
'type'] == 'image' else None,
|
||||
'watermark_image_list': data['image_data']['watermark_image_list'] if data['type'] == 'image' else None
|
||||
}
|
||||
return result
|
||||
else:
|
||||
return data
|
||||
|
||||
|
||||
"""__________________________________________⬇️Test methods(测试方法)⬇️______________________________________"""
|
||||
|
||||
|
||||
async def async_test(douyin_url: str = None, tiktok_url: str = None) -> None:
|
||||
# 异步测试/Async test
|
||||
start_time = time.time()
|
||||
print("正在进行异步测试...")
|
||||
|
||||
print("正在测试异步获取抖音视频ID方法...")
|
||||
douyin_id = await api.get_douyin_video_id(douyin_url)
|
||||
print("正在测试异步获取抖音视频数据方法...")
|
||||
douyin_data = await api.get_douyin_video_data(douyin_id)
|
||||
|
||||
print("正在测试异步获取TikTok视频ID方法...")
|
||||
tiktok_id = await api.get_tiktok_video_id(tiktok_url)
|
||||
print("正在测试异步获取TikTok视频数据方法...")
|
||||
tiktok_data = await api.get_tiktok_video_data(tiktok_id)
|
||||
|
||||
print("正在测试异步混合解析方法...")
|
||||
douyin_hybrid_data = await api.hybrid_parsing(douyin_url)
|
||||
tiktok_hybrid_data = await api.hybrid_parsing(tiktok_url)
|
||||
|
||||
# 总耗时/Total time
|
||||
total_time = round(time.time() - start_time, 2)
|
||||
print("异步测试完成,总耗时: {}s".format(total_time))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
api = Scraper()
|
||||
# 运行测试
|
||||
douyin_url = 'https://v.douyin.com/rLyrQxA/6.66'
|
||||
tiktok_url = 'https://vt.tiktok.com/ZSRwWXtdr/'
|
||||
asyncio.run(async_test(douyin_url=douyin_url, tiktok_url=tiktok_url))
|
||||
@ -1,31 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- encoding: utf-8 -*-
|
||||
# @Author: https://github.com/Evil0ctal/
|
||||
# @Time: 2021/11/13
|
||||
# @Description: Douyin/TikTok async data scraper demo.
|
||||
# PyPi: https://pypi.org/project/douyin-tiktok-scraper/
|
||||
|
||||
|
||||
import asyncio
|
||||
# pip install douyin-tiktok-scraper
|
||||
from douyin_tiktok_scraper.scraper import Scraper
|
||||
|
||||
api = Scraper()
|
||||
|
||||
|
||||
async def async_test(url: str):
|
||||
if 'douyin' in url: # 抖音数据爬取
|
||||
douyin_url = await api.convert_share_urls(url)
|
||||
douyin_id = await api.get_douyin_video_id(douyin_url)
|
||||
douyin_data = await api.get_douyin_video_data(douyin_id)
|
||||
print(f"视频URL:{douyin_url}\n视频ID:{douyin_id}\n视频数据:{douyin_data}\n")
|
||||
elif 'tiktok' in url: # TikTok data scraper
|
||||
tiktok_url = await api.convert_share_urls(url)
|
||||
tiktok_id = await api.get_tiktok_video_id(tiktok_url)
|
||||
tiktok_data = await api.get_tiktok_video_data(tiktok_id)
|
||||
print(f"Video URL:{tiktok_url}\nVideo ID:{tiktok_id}\nVideo Data:{tiktok_data}\n")
|
||||
# Hybrid parsing(Any platform URL)
|
||||
hybrid_data = await api.hybrid_parsing(url)
|
||||
|
||||
|
||||
asyncio.run(async_test(url=input("Paste Douyin/TikTok share URL here: ")))
|
||||
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.0.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.0.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.1.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.1.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.2.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.2.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.3.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.3.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.4.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.4.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.5.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.5.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.6.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.6.tar.gz
vendored
Binary file not shown.
Binary file not shown.
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.7.tar.gz
vendored
BIN
PyPi/dist/douyin_tiktok_scraper-1.0.7.tar.gz
vendored
Binary file not shown.
@ -1,376 +0,0 @@
|
||||
Metadata-Version: 2.1
|
||||
Name: douyin-tiktok-scraper
|
||||
Version: 1.0.6
|
||||
Summary: Douyin/TikTok async data scraper.
|
||||
Home-page: https://github.com/Evil0ctal/Douyin_TikTok_Download_API
|
||||
Author: Evil0ctal
|
||||
Author-email: Evil0ctal1985@gmail.com
|
||||
License: MIT License
|
||||
Keywords: TikTok,Douyin,抖音,Scraper,Crawler,API,Download,Video,No Watermark,Async
|
||||
Platform: UNKNOWN
|
||||
Classifier: Programming Language :: Python :: 3
|
||||
Classifier: Programming Language :: Python :: 3.6
|
||||
Classifier: Programming Language :: Python :: 3.7
|
||||
Classifier: Programming Language :: Python :: 3.8
|
||||
Classifier: Programming Language :: Python :: 3.9
|
||||
Classifier: Programming Language :: Python :: 3.10
|
||||
Classifier: Programming Language :: Python :: 3 :: Only
|
||||
Requires-Python: >=3.6
|
||||
Description-Content-Type: text/markdown
|
||||
License-File: LICENSE
|
||||
|
||||
<div align="center">
|
||||
<a href="https://douyin.wtf/" alt="logo" ><img src="./logo/logo192.png" width="120"/></a>
|
||||
</div>
|
||||
<h1 align="center">Douyin_TikTok_Download_API(抖音/TikTok API)</h1>
|
||||
|
||||
<div align="center">
|
||||
|
||||
[English](./README.en.md) | [简体中文](./README.md)
|
||||
|
||||
🚀「Douyin_TikTok_Download_API」是一个开箱即用的高性能异步[抖音](https://www.douyin.com)|[TikTok](https://www.tiktok.com)数据爬取工具,支持API调用,在线批量解析及下载。
|
||||
|
||||
[](LICENSE)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/releases/latest)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/stargazers)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/network/members)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)
|
||||
[](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues?q=is%3Aissue+is%3Aclosed)
|
||||

|
||||
<br>
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/#files)
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
[](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
<br>
|
||||
[](https://api.douyin.wtf/docs)
|
||||
[](https://api-v2.douyin.wtf/docs)
|
||||
<br>
|
||||
[](https://afdian.net/@evil0ctal)
|
||||
[](https://ko-fi.com/evil0ctal)
|
||||
[](https://www.patreon.com/evil0ctal)
|
||||
|
||||
</div>
|
||||
|
||||
## 👻介绍
|
||||
|
||||
> 🚨如需使用私有服务器运行本项目,请参考部署方式[[Docker部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%BA%8C-docker), [手动部署](./README.md#%E9%83%A8%E7%BD%B2%E6%96%B9%E5%BC%8F%E4%B8%80-linux)]
|
||||
|
||||
本项目是基于 [PyWebIO](https://github.com/pywebio/PyWebIO),[FastAPI](https://fastapi.tiangolo.com/),[AIOHTTP](https://docs.aiohttp.org/),快速异步的[抖音](https://www.douyin.com/)/[TikTok](https://www.tiktok.com/)数据爬取工具,并通过Web端实现在线批量解析以及下载无水印视频或图集,数据爬取API,iOS快捷指令无水印下载等功能。你可以自己部署或改造本项目实现更多功能,也可以在你的项目中直接调用[scraper.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/Stable/scraper.py)或安装现有的[pip包](https://pypi.org/project/douyin-tiktok-scraper/)作为解析库轻松爬取数据等.....
|
||||
|
||||
*一些简单的运用场景:*
|
||||
|
||||
*下载禁止下载的视频,进行数据分析,iOS无水印下载(搭配[iOS自带的快捷指令APP](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)
|
||||
配合本项目API实现应用内下载或读取剪贴板下载)等.....*
|
||||
|
||||
## 🖥公共站点: 我很脆弱...请勿压测(·•᷄ࡇ•᷅ )
|
||||
|
||||
> **API-V2:** 支持输入`Douyin|TikTok`用户主页爬取该作者[主页视频数据(去水印链接, 已点赞视频列表(权限需为公开), 视频评论数据, 背景音乐视频列表数据, 等等...), 详细信息请查看V2文档, 服务器响应时间有时会变长, 使用时请将`timeout`值设高.
|
||||
|
||||
🍔Web APP: [https://douyin.wtf/](https://douyin.wtf/)
|
||||
|
||||
🍟API-V1: [https://api.douyin.wtf/docs](https://api.douyin.wtf/docs)
|
||||
|
||||
🌭API-V2: [https://api-v2.douyin.wtf/docs](https://api-v2.douyin.wtf/docs)
|
||||
|
||||
💾iOS Shortcut(快捷指令): [Shortcut release](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/discussions/104?sort=top)
|
||||
|
||||
📦️桌面端下载器(仓库推荐):
|
||||
|
||||
- [Tairraos/TikDown](https://github.com/Tairraos/TikDown/)
|
||||
- [Johnserf-Seed/TikTokDownload](https://github.com/Johnserf-Seed/TikTokDownload)
|
||||
- [HFrost0/bilix](https://github.com/HFrost0/bilix)
|
||||
|
||||
## ⚗️技术栈
|
||||
|
||||
* [web_app.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/web_app.py) - [PyWebIO](https://www.pyweb.io/)
|
||||
* [web_api.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/web_api.py) - [FastAPI](https://fastapi.tiangolo.com/)
|
||||
* [scraper.py](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/scraper.py) - [AIOHTTP](https://docs.aiohttp.org/)
|
||||
|
||||
> ***scraper.py:***
|
||||
|
||||
- 向[Douyin|TikTok]的API提交请求并取回数据,处理后返回字典(dict),支持异步。
|
||||
|
||||
> ***web_api.py:***
|
||||
|
||||
- 获得请求参数并使用`Scraper()`类处理数据后以JSON形式返回,视频下载,配合iOS快捷指令实现快速调用,支持异步。
|
||||
|
||||
> ***web_app.py:***
|
||||
|
||||
- 为`web_api.py`以及`scraper.py`制作的简易Web程序,将网页输入的值进行处理后使用`Scraper()`类处理并配合`web_api.py`的接口输出在网页上(类似前后端分离)
|
||||
|
||||
***以上文件的参数大多可在[config.ini](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/config.ini)中进行修改***
|
||||
|
||||
## 💡项目文件结构
|
||||
|
||||
```
|
||||
.
|
||||
└── Douyin_TikTok_Download_API/
|
||||
├── /static -> (PyWebIO static resources)
|
||||
├── web_app.py -> (Web APP)
|
||||
├── web_api.py -> (API)
|
||||
├── scraper.py -> (Parsing library)
|
||||
├── config.ini -> (configuration file)
|
||||
```
|
||||
|
||||
## ✨功能:
|
||||
|
||||
- 抖音(抖音海外版: TikTok)视频/图片解析
|
||||
- 网页端批量解析(支持抖音/TikTok混合提交)
|
||||
- 网页端解析结果页批量下载无水印视频(V3.0.0暂时移除,请自行部署V2.X版本)
|
||||
- API调用获取链接数据
|
||||
- 制作[pip包](https://pypi.org/project/douyin-tiktok-scraper/)方便快速导入你的项目
|
||||
- [iOS快捷指令快速调用API](https://apps.apple.com/cn/app/%E5%BF%AB%E6%8D%B7%E6%8C%87%E4%BB%A4/id915249334)实现应用内下载无水印视频/图集
|
||||
- 解析作者主页内所有视频([API-V2](https://api-v2.douyin.wtf/docs) 支持抖音/TikTok)
|
||||
- 解析视频内所有评论信息([API-V2](https://api-v2.douyin.wtf/docs) 支持抖音/TikTok)
|
||||
|
||||
---
|
||||
|
||||
## 🤦待办清单:
|
||||
|
||||
> 💡欢迎提出新的建议或将你的思路在issue中与我分享,或直接提交PR至[Development分支](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/tree/Development) ♪(・ω・)ノ)
|
||||
|
||||
- [ ] 编写一个桌面端的下载器实现本地批量下载
|
||||
- [ ] API-V2添加对hash_tag页面的数据爬取 [#101](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/101)
|
||||
- [ ] 对其他短视频平台添加支持,如:抖音火山版,快手,西瓜视频,哔哩哔哩
|
||||
|
||||
---
|
||||
|
||||
## 📦调用解析库:
|
||||
|
||||
> 💡PyPi:[https://pypi.org/project/douyin-tiktok-scraper/](https://pypi.org/project/douyin-tiktok-scraper/)
|
||||
|
||||
安装解析库:`pip install douyin-tiktok-scraper`
|
||||
|
||||
```python
|
||||
import asyncio
|
||||
from douyin_tiktok_scraper.scraper import Scraper
|
||||
|
||||
api = Scraper()
|
||||
|
||||
async def hybrid_parsing(url: str) -> dict:
|
||||
# Hybrid parsing(Douyin/TikTok URL)
|
||||
result = await api.hybrid_parsing(url)
|
||||
print(f"The hybrid parsing result:\n {result}")
|
||||
return result
|
||||
|
||||
asyncio.run(hybrid_parsing(url=input("Paste Douyin/TikTok share URL here: ")))
|
||||
```
|
||||
|
||||
## 🗺️支持的提交格式:
|
||||
|
||||
> 💡提示:包含但不仅限于以下例子,如果遇到链接解析失败请开启一个新 [issue](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues)
|
||||
|
||||
- 抖音分享口令 (APP内复制)
|
||||
|
||||
```text
|
||||
7.43 pda:/ 让你在几秒钟之内记住我 https://v.douyin.com/L5pbfdP/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
```
|
||||
|
||||
- 抖音短网址 (APP内复制)
|
||||
|
||||
```text
|
||||
https://v.douyin.com/L4FJNR3/
|
||||
```
|
||||
|
||||
- 抖音正常网址 (网页版复制)
|
||||
|
||||
```text
|
||||
https://www.douyin.com/video/6914948781100338440
|
||||
```
|
||||
|
||||
- 抖音发现页网址 (APP复制)
|
||||
|
||||
```text
|
||||
https://www.douyin.com/discover?modal_id=7069543727328398622
|
||||
```
|
||||
|
||||
- TikTok短网址 (APP内复制)
|
||||
|
||||
```text
|
||||
https://www.tiktok.com/t/ZTR9nDNWq/
|
||||
```
|
||||
|
||||
- TikTok正常网址 (网页版复制)
|
||||
|
||||
```text
|
||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||
```
|
||||
|
||||
- 抖音/TikTok批量网址(无需使用符合隔开)
|
||||
|
||||
```text
|
||||
https://v.douyin.com/L4NpDJ6/
|
||||
https://www.douyin.com/video/7126745726494821640
|
||||
2.84 nqe:/ 骑白马的也可以是公主%%百万转场变身https://v.douyin.com/L4FJNR3/ 复制此链接,打开Dou音搜索,直接观看视频!
|
||||
https://www.tiktok.com/t/ZTR9nkkmL/
|
||||
https://www.tiktok.com/t/ZTR9nDNWq/
|
||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||
```
|
||||
|
||||
## 🛰️API文档
|
||||
|
||||
> 💡提示:也可以在web_api.py的代码注释中查看接口文档
|
||||
|
||||
***API-V1文档:***
|
||||
本地:[http://localhost:8000/docs](http://localhost:8000/docs)
|
||||
在线:[https://api.douyin.wtf/docs](https://api.douyin.wtf/docs)
|
||||
|
||||
***API-V2文档:***
|
||||
在线:[https://api-v2.douyin.wtf/docs](https://api-v2.douyin.wtf/docs)
|
||||
|
||||
***API演示:***
|
||||
|
||||
- 爬取视频数据(TikTok或Douyin混合解析)
|
||||
`https://api.douyin.wtf/api?url=[视频链接/Video URL]&minimal=false`
|
||||
- 下载视频/图集(TikTok或Douyin混合解析)
|
||||
`https://api.douyin.wtf/download?url=[视频链接/Video URL]&prefix=true&watermark=false`
|
||||
- 替换域名下载视频/图集
|
||||
|
||||
```
|
||||
[抖音]
|
||||
原始链接:
|
||||
https://www.douyin.com/video/7159502929156705567
|
||||
替换域名:
|
||||
https://api.douyin.wtf/video/7159502929156705567
|
||||
# 返回无水印视频下载响应
|
||||
[TikTok]
|
||||
original link:
|
||||
https://www.tiktok.com/@evil0ctal/video/7156033831819037994
|
||||
Replace Domain:
|
||||
https://api.douyin.wtf/@evil0ctal/video/7156033831819037994
|
||||
# Return No Watermark Video Download Response
|
||||
```
|
||||
|
||||
***更多演示请查看文档内容......***
|
||||
|
||||
## 💻部署(方式一 Linux)
|
||||
|
||||
> 💡提示:最好将本项目部署至美国地区的服务器,否则可能会出现奇怪的BUG。
|
||||
|
||||
- 首先要去安全组开放8080(Web)和8000(API)端口。
|
||||
- 在宝塔面板应用商店内搜索`进程守护`或手动安装`supervisord`:
|
||||
|
||||
```
|
||||
[宝塔面板]
|
||||
https://www.bt.cn/new/download.html
|
||||
[aapanel]
|
||||
https://www.aapanel.com/new/download.html
|
||||
[Supervisor]
|
||||
http://supervisord.org/installing.html
|
||||
```
|
||||
|
||||
- 配置项目[config.ini](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/main/config.ini)文件
|
||||
- 安装依赖文件`pip install -r requirements.txt`
|
||||
- 设置`supervisord`守护进程
|
||||
- 启动命令:
|
||||
|
||||
```console
|
||||
[Web]
|
||||
python3 web_app.py
|
||||
[API]
|
||||
python3 web_api.py
|
||||
```
|
||||
|
||||
- 程序入口:
|
||||
|
||||
```text
|
||||
[Web]
|
||||
http://localhost:8080
|
||||
[API]
|
||||
http://localhost:8000
|
||||
```
|
||||
|
||||
## 💽部署(方式二 Docker)
|
||||
|
||||
> 💡Docker Image repo: [Docker Hub](https://hub.docker.com/repository/docker/evil0ctal/douyin_tiktok_download_api)
|
||||
|
||||
- 安装docker
|
||||
|
||||
```yaml
|
||||
curl -fsSL get.docker.com -o get-docker.sh&&sh get-docker.sh &&systemctl enable docker&&systemctl start docker
|
||||
```
|
||||
|
||||
- 留下config.int和docker-compose.yml文件即可
|
||||
- 运行命令,让容器在后台运行
|
||||
|
||||
```yaml
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
- 查看容器日志
|
||||
|
||||
```yaml
|
||||
docker logs -f douyin_tiktok_download_api
|
||||
```
|
||||
|
||||
- 删除容器
|
||||
|
||||
```yaml
|
||||
docker rm -f douyin_tiktok_download_api
|
||||
```
|
||||
|
||||
- 更新
|
||||
|
||||
```yaml
|
||||
docker compose pull && docker compose down && docker compose up -d
|
||||
```
|
||||
|
||||
## ❤️ 贡献者
|
||||
|
||||
[](https://github.com/Evil0ctal)
|
||||
[](https://github.com/jw-star)
|
||||
[](https://github.com/Jeffrey-deng)
|
||||
[](https://github.com/chris-ss)
|
||||
[](https://github.com/weixuan00)
|
||||
[](https://github.com/Tairraos)
|
||||
|
||||
## 📸截图
|
||||
|
||||
***API速度测试(对比官方API)***
|
||||
|
||||
<details><summary>🔎点击展开截图</summary>
|
||||
|
||||
抖音官方API:
|
||||

|
||||
|
||||
本项目API:
|
||||

|
||||
|
||||
TikTok官方API:
|
||||

|
||||
|
||||
本项目API:
|
||||

|
||||
|
||||
</details>
|
||||
<hr>
|
||||
|
||||
***项目界面***
|
||||
|
||||
<details><summary>🔎点击展开截图</summary>
|
||||
|
||||
Web主界面:
|
||||
|
||||

|
||||
|
||||
Web main interface:
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
<hr>
|
||||
|
||||
## 📜 Star历史
|
||||
|
||||
[](https://star-history.com/#Evil0ctal/Douyin_TikTok_Download_API&Timeline)
|
||||
|
||||
[MIT License](https://github.com/Evil0ctal/Douyin_TikTok_Download_API/blob/Stable/LICENSE)
|
||||
|
||||
> Start: 2021/11/06
|
||||
> GitHub: [@Evil0ctal](https://github.com/Evil0ctal)
|
||||
> Contact: Evil0ctal1985@gmail.com
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,10 +0,0 @@
|
||||
LICENSE
|
||||
README.md
|
||||
setup.py
|
||||
douyin_tiktok_scraper/__init__.py
|
||||
douyin_tiktok_scraper/scraper.py
|
||||
douyin_tiktok_scraper.egg-info/PKG-INFO
|
||||
douyin_tiktok_scraper.egg-info/SOURCES.txt
|
||||
douyin_tiktok_scraper.egg-info/dependency_links.txt
|
||||
douyin_tiktok_scraper.egg-info/requires.txt
|
||||
douyin_tiktok_scraper.egg-info/top_level.txt
|
||||
@ -1,3 +0,0 @@
|
||||
aiohttp
|
||||
orjson
|
||||
tenacity
|
||||
@ -1 +0,0 @@
|
||||
douyin_tiktok_scraper
|
||||
@ -1,555 +0,0 @@
|
||||
#!/usr/bin/env python
|
||||
# -*- encoding: utf-8 -*-
|
||||
# @Author: https://github.com/Evil0ctal/
|
||||
# @Time: 2021/11/06
|
||||
# @Update: 2022/12/09
|
||||
# @Version: 3.1.5
|
||||
# @Function:
|
||||
# 核心代码,估值1块(๑•̀ㅂ•́)و✧
|
||||
# 用于爬取Douyin/TikTok数据并以字典形式返回。
|
||||
# input link, output dictionary.
|
||||
|
||||
|
||||
import re
|
||||
import os
|
||||
import random
|
||||
import aiohttp
|
||||
import platform
|
||||
import asyncio
|
||||
import orjson
|
||||
import traceback
|
||||
import configparser
|
||||
|
||||
from typing import Union
|
||||
from tenacity import *
|
||||
|
||||
|
||||
class Scraper:
|
||||
"""
|
||||
简介/Introduction
|
||||
|
||||
Scraper.get_url(text: str) -> Union[str, None]
|
||||
用于检索出文本中的链接并返回/Used to retrieve the link in the text and return it.
|
||||
|
||||
Scraper.convert_share_urls(self, url: str) -> Union[str, None]\n
|
||||
用于转换分享链接为原始链接/Convert share links to original links
|
||||
|
||||
Scraper.get_douyin_video_id(self, original_url: str) -> Union[str, None]\n
|
||||
用于获取抖音视频ID/Get Douyin video ID
|
||||
|
||||
Scraper.get_douyin_video_data(self, video_id: str) -> Union[dict, None]\n
|
||||
用于获取抖音视频数据/Get Douyin video data
|
||||
|
||||
Scraper.get_douyin_live_video_data(self, original_url: str) -> Union[str, None]\n
|
||||
用于获取抖音直播视频数据/Get Douyin live video data
|
||||
|
||||
Scraper.get_tiktok_video_id(self, original_url: str) -> Union[str, None]\n
|
||||
用于获取TikTok视频ID/Get TikTok video ID
|
||||
|
||||
Scraper.get_tiktok_video_data(self, video_id: str) -> Union[dict, None]\n
|
||||
用于获取TikTok视频数据/Get TikTok video data
|
||||
|
||||
Scraper.hybrid_parsing(self, video_url: str) -> dict\n
|
||||
用于混合解析/ Hybrid parsing
|
||||
|
||||
Scraper.hybrid_parsing_minimal(data: dict) -> dict\n
|
||||
用于混合解析最小化/Hybrid parsing minimal
|
||||
"""
|
||||
|
||||
"""__________________________________________⬇️initialization(初始化)⬇️______________________________________"""
|
||||
|
||||
# 初始化/initialization
|
||||
def __init__(self):
|
||||
self.headers = {
|
||||
'User-Agent': "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Mobile Safari/537.36 Edg/87.0.664.66"
|
||||
}
|
||||
self.douyin_cookies = {
|
||||
'Cookie': 'msToken=tsQyL2_m4XgtIij2GZfyu8XNXBfTGELdreF1jeIJTyktxMqf5MMIna8m1bv7zYz4pGLinNP2TvISbrzvFubLR8khwmAVLfImoWo3Ecnl_956MgOK9kOBdwM=; odin_tt=6db0a7d68fd2147ddaf4db0b911551e472d698d7b84a64a24cf07c49bdc5594b2fb7a42fd125332977218dd517a36ec3c658f84cebc6f806032eff34b36909607d5452f0f9d898810c369cd75fd5fb15; ttwid=1%7CfhiqLOzu_UksmD8_muF_TNvFyV909d0cw8CSRsmnbr0%7C1662368529%7C048a4e969ec3570e84a5faa3518aa7e16332cfc7fbcb789780135d33a34d94d2'
|
||||
}
|
||||
self.tiktok_api_headers = {
|
||||
'User-Agent': 'com.ss.android.ugc.trill/494+Mozilla/5.0+(Linux;+Android+12;+2112123G+Build/SKQ1.211006.001;+wv)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Version/4.0+Chrome/107.0.5304.105+Mobile+Safari/537.36'
|
||||
}
|
||||
# 判断配置文件是否存在/Check if the configuration file exists
|
||||
if os.path.exists('config.ini'):
|
||||
self.config = configparser.ConfigParser()
|
||||
self.config.read('config.ini', encoding='utf-8')
|
||||
# 判断是否使用代理
|
||||
if self.config['Scraper']['Proxy_switch'] == 'True':
|
||||
# 判断是否区别协议选择代理
|
||||
if self.config['Scraper']['Use_different_protocols'] == 'False':
|
||||
self.proxies = {
|
||||
'all': self.config['Scraper']['All']
|
||||
}
|
||||
else:
|
||||
self.proxies = {
|
||||
'http': self.config['Scraper']['Http_proxy'],
|
||||
'https': self.config['Scraper']['Https_proxy'],
|
||||
}
|
||||
else:
|
||||
self.proxies = None
|
||||
# 配置文件不存在则不使用代理/If the configuration file does not exist, do not use the proxy
|
||||
else:
|
||||
self.proxies = None
|
||||
# 针对Windows系统的异步事件规则/Asynchronous event rules for Windows systems
|
||||
if platform.system() == 'Windows':
|
||||
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
|
||||
|
||||
"""__________________________________________⬇️utils(实用程序)⬇️______________________________________"""
|
||||
|
||||
# 检索字符串中的链接
|
||||
@staticmethod
|
||||
def get_url(text: str) -> Union[str, None]:
|
||||
try:
|
||||
# 从输入文字中提取索引链接存入列表/Extract index links from input text and store in list
|
||||
url = re.findall('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', text)
|
||||
# 判断是否有链接/Check if there is a link
|
||||
if len(url) > 0:
|
||||
return url[0]
|
||||
except Exception as e:
|
||||
print('Error in get_url:', e)
|
||||
return None
|
||||
|
||||
# 转换链接/convert url
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def convert_share_urls(self, url: str) -> Union[str, None]:
|
||||
"""
|
||||
用于将分享链接(短链接)转换为原始链接/Convert share links (short links) to original links
|
||||
:return: 原始链接/Original link
|
||||
"""
|
||||
# 检索字符串中的链接/Retrieve links from string
|
||||
url = self.get_url(url)
|
||||
# 判断是否有链接/Check if there is a link
|
||||
if url is None:
|
||||
print('无法检索到链接/Unable to retrieve link')
|
||||
return None
|
||||
# 判断是否为抖音分享链接/judge if it is a douyin share link
|
||||
if 'douyin' in url:
|
||||
"""
|
||||
抖音视频链接类型(不全):
|
||||
1. https://v.douyin.com/MuKhKn3/
|
||||
2. https://www.douyin.com/video/7157519152863890719
|
||||
3. https://www.iesdouyin.com/share/video/7157519152863890719/?region=CN&mid=7157519152863890719&u_code=ffe6jgjg&titleType=title×tamp=1600000000&utm_source=copy_link&utm_campaign=client_share&utm_medium=android&app=aweme&iid=123456789&share_id=123456789
|
||||
抖音用户链接类型(不全):
|
||||
1. https://www.douyin.com/user/MS4wLjABAAAAbLMPpOhVk441et7z7ECGcmGrK42KtoWOuR0_7pLZCcyFheA9__asY-kGfNAtYqXR?relation=0&vid=7157519152863890719
|
||||
2. https://v.douyin.com/MuKoFP4/
|
||||
抖音直播链接类型(不全):
|
||||
1. https://live.douyin.com/88815422890
|
||||
"""
|
||||
if 'v.douyin' in url:
|
||||
# 转换链接/convert url
|
||||
# 例子/Example: https://v.douyin.com/rLyAJgf/8.74
|
||||
url = re.compile(r'(https://v.douyin.com/)\w+', re.I).match(url).group()
|
||||
print('正在通过抖音分享链接获取原始链接...')
|
||||
try:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url, headers=self.headers, proxy=self.proxies, allow_redirects=False,
|
||||
timeout=10) as response:
|
||||
if response.status == 302:
|
||||
url = response.headers['Location'].split('?')[0] if '?' in response.headers[
|
||||
'Location'] else \
|
||||
response.headers['Location']
|
||||
print('获取原始链接成功, 原始链接为: {}'.format(url))
|
||||
return url
|
||||
except Exception as e:
|
||||
print('获取原始链接失败!')
|
||||
print(e)
|
||||
return None
|
||||
else:
|
||||
print('该链接为原始链接,无需转换,原始链接为: {}'.format(url))
|
||||
return url
|
||||
# 判断是否为TikTok分享链接/judge if it is a TikTok share link
|
||||
elif 'tiktok' in url:
|
||||
"""
|
||||
TikTok视频链接类型(不全):
|
||||
1. https://www.tiktok.com/@tiktok/video/6950000000000000000
|
||||
2. https://www.tiktok.com/t/ZTRHcXS2C/
|
||||
TikTok用户链接类型(不全):
|
||||
1. https://www.tiktok.com/@tiktok
|
||||
"""
|
||||
if '@' in url:
|
||||
print('该链接为原始链接,无需转换,原始链接为: {}'.format(url))
|
||||
return url
|
||||
else:
|
||||
print('正在通过TikTok分享链接获取原始链接...')
|
||||
try:
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(url, headers=self.headers, proxy=self.proxies, allow_redirects=False,
|
||||
timeout=10) as response:
|
||||
if response.status == 301:
|
||||
url = response.headers['Location'].split('?')[0] if '?' in response.headers[
|
||||
'Location'] else \
|
||||
response.headers['Location']
|
||||
print('获取原始链接成功, 原始链接为: {}'.format(url))
|
||||
return url
|
||||
except Exception as e:
|
||||
print('获取原始链接失败!')
|
||||
print(e)
|
||||
return None
|
||||
|
||||
"""__________________________________________⬇️Douyin methods(抖音方法)⬇️______________________________________"""
|
||||
|
||||
# 获取抖音视频ID/Get Douyin video ID
|
||||
async def get_douyin_video_id(self, original_url: str) -> Union[str, None]:
|
||||
"""
|
||||
获取视频id
|
||||
:param original_url: 视频链接
|
||||
:return: 视频id
|
||||
"""
|
||||
# 正则匹配出视频ID
|
||||
try:
|
||||
video_url = await self.convert_share_urls(original_url)
|
||||
# 链接类型:
|
||||
# 视频页 https://www.douyin.com/video/7086770907674348841
|
||||
if '/video/' in video_url:
|
||||
key = re.findall('/video/(\d+)?', video_url)[0]
|
||||
print('获取到的抖音视频ID为: {}'.format(key))
|
||||
return key
|
||||
# 发现页 https://www.douyin.com/discover?modal_id=7086770907674348841
|
||||
elif 'discover?' in video_url:
|
||||
key = re.findall('modal_id=(\d+)', video_url)[0]
|
||||
print('获取到的抖音视频ID为: {}'.format(key))
|
||||
return key
|
||||
# 直播页
|
||||
elif 'live.douyin' in video_url:
|
||||
# https://live.douyin.com/1000000000000000000
|
||||
key = video_url.replace('https://live.douyin.com/', '')
|
||||
print('获取到的抖音直播ID为: {}'.format(key))
|
||||
return key
|
||||
# note
|
||||
elif 'note' in video_url:
|
||||
# https://www.douyin.com/note/7086770907674348841
|
||||
key = re.findall('/note/(\d+)?', video_url)[0]
|
||||
print('获取到的抖音笔记ID为: {}'.format(key))
|
||||
return key
|
||||
except Exception as e:
|
||||
print('获取抖音视频ID出错了:{}'.format(e))
|
||||
return None
|
||||
|
||||
# 获取单个抖音视频数据/Get single Douyin video data
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def get_douyin_video_data(self, video_id: str) -> Union[dict, None]:
|
||||
"""
|
||||
:param video_id: str - 抖音视频id
|
||||
:return:dict - 包含信息的字典
|
||||
"""
|
||||
print('正在获取抖音视频数据...')
|
||||
try:
|
||||
# 构造访问链接/Construct the access link
|
||||
api_url = f"https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={video_id}"
|
||||
# 访问API/Access API
|
||||
print("正在获取视频数据API: {}".format(api_url))
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(api_url, headers=self.headers, proxy=self.proxies, timeout=10) as response:
|
||||
response = await response.json()
|
||||
# 获取视频数据/Get video data
|
||||
video_data = response['item_list'][0]
|
||||
print('获取视频数据成功!')
|
||||
# print("抖音API返回数据: {}".format(video_data))
|
||||
return video_data
|
||||
except Exception as e:
|
||||
print('获取抖音视频数据失败!原因:{}'.format(e))
|
||||
return None
|
||||
|
||||
# 获取单个抖音直播视频数据/Get single Douyin Live video data
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def get_douyin_live_video_data(self, web_rid: str) -> Union[dict, None]:
|
||||
print('正在获取抖音视频数据...')
|
||||
try:
|
||||
# 构造访问链接/Construct the access link
|
||||
api_url = f"https://live.douyin.com/webcast/web/enter/?aid=6383&web_rid={web_rid}"
|
||||
# 访问API/Access API
|
||||
print("正在获取视频数据API: {}".format(api_url))
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(api_url, headers=self.douyin_cookies, proxy=self.proxies, timeout=10) as response:
|
||||
response = await response.json()
|
||||
# 获取返回的json数据/Get the returned json data
|
||||
data = orjson.loads(response.text)
|
||||
# 获取视频数据/Get video data
|
||||
video_data = data['data']
|
||||
print('获取视频数据成功!')
|
||||
# print("抖音API返回数据: {}".format(video_data))
|
||||
return video_data
|
||||
except Exception as e:
|
||||
print('获取抖音视频数据失败!原因:{}'.format(e))
|
||||
return None
|
||||
|
||||
"""__________________________________________⬇️TikTok methods(TikTok方法)⬇️______________________________________"""
|
||||
|
||||
# 获取TikTok视频ID/Get TikTok video ID
|
||||
async def get_tiktok_video_id(self, original_url: str) -> Union[str, None]:
|
||||
"""
|
||||
获取视频id
|
||||
:param original_url: 视频链接
|
||||
:return: 视频id
|
||||
"""
|
||||
try:
|
||||
# 转换链接/Convert link
|
||||
original_url = await self.convert_share_urls(original_url)
|
||||
# 获取视频ID/Get video ID
|
||||
if '.html' in original_url:
|
||||
video_id = original_url.replace('.html', '')
|
||||
elif '/video/' in original_url:
|
||||
video_id = re.findall('/video/(\d+)', original_url)[0]
|
||||
elif '/v/' in original_url:
|
||||
video_id = re.findall('/v/(\d+)', original_url)[0]
|
||||
print('获取到的TikTok视频ID是{}'.format(video_id))
|
||||
# 返回视频ID/Return video ID
|
||||
return video_id
|
||||
except Exception as e:
|
||||
print('获取TikTok视频ID出错了:{}'.format(e))
|
||||
return None
|
||||
|
||||
@retry(stop=stop_after_attempt(3), wait=wait_random(min=1, max=2))
|
||||
async def get_tiktok_video_data(self, video_id: str) -> Union[dict, None]:
|
||||
"""
|
||||
获取单个视频信息
|
||||
:param video_id: 视频id
|
||||
:return: 视频信息
|
||||
"""
|
||||
print('正在获取TikTok视频数据...')
|
||||
try:
|
||||
# 构造访问链接/Construct the access link
|
||||
api_url = f'https://api16-normal-c-useast1a.tiktokv.com/aweme/v1/feed/?aweme_id={video_id}&iid=6165993682518218889&device_id={random.randint(10*10*10, 9*10**10)}&aid=1180'
|
||||
print("正在获取视频数据API: {}".format(api_url))
|
||||
async with aiohttp.ClientSession() as session:
|
||||
async with session.get(api_url, headers=self.tiktok_api_headers, proxy=self.proxies, timeout=10) as response:
|
||||
response = await response.json()
|
||||
video_data = response['aweme_list'][0]
|
||||
print('获取视频信息成功!')
|
||||
return video_data
|
||||
except Exception as e:
|
||||
print('获取视频信息失败!原因:{}'.format(e))
|
||||
return None
|
||||
|
||||
"""__________________________________________⬇️Hybrid methods(混合方法)⬇️______________________________________"""
|
||||
|
||||
# 自定义获取数据/Custom data acquisition
|
||||
async def hybrid_parsing(self, video_url: str) -> dict:
|
||||
# URL平台判断/Judge URL platform
|
||||
url_platform = 'douyin' if 'douyin' in video_url else 'tiktok'
|
||||
print('当前链接平台为:{}'.format(url_platform))
|
||||
# 获取视频ID/Get video ID
|
||||
print("正在获取视频ID...")
|
||||
video_id = await self.get_douyin_video_id(
|
||||
video_url) if url_platform == 'douyin' else await self.get_tiktok_video_id(
|
||||
video_url)
|
||||
if video_id:
|
||||
print("获取视频ID成功,视频ID为:{}".format(video_id))
|
||||
# 获取视频数据/Get video data
|
||||
print("正在获取视频数据...")
|
||||
data = await self.get_douyin_video_data(
|
||||
video_id) if url_platform == 'douyin' else await self.get_tiktok_video_data(
|
||||
video_id)
|
||||
if data:
|
||||
print("获取视频数据成功,正在判断数据类型...")
|
||||
url_type_code = data['aweme_type']
|
||||
"""以下为抖音/TikTok类型代码/Type code for Douyin/TikTok"""
|
||||
url_type_code_dict = {
|
||||
# 抖音/Douyin
|
||||
2: 'image',
|
||||
4: 'video',
|
||||
# TikTok
|
||||
0: 'video',
|
||||
51: 'video',
|
||||
55: 'video',
|
||||
58: 'video',
|
||||
61: 'video',
|
||||
150: 'image'
|
||||
}
|
||||
# 获取视频类型/Get video type
|
||||
# 如果类型代码不存在,则默认为视频类型/If the type code does not exist, it is assumed to be a video type
|
||||
print("数据类型代码: {}".format(url_type_code))
|
||||
# 判断链接类型/Judge link type
|
||||
url_type = url_type_code_dict.get(url_type_code, 'video')
|
||||
print("数据类型: {}".format(url_type))
|
||||
print("准备开始判断并处理数据...")
|
||||
|
||||
"""
|
||||
以下为(视频||图片)数据处理的四个方法,如果你需要自定义数据处理请在这里修改.
|
||||
The following are four methods of (video || image) data processing.
|
||||
If you need to customize data processing, please modify it here.
|
||||
"""
|
||||
|
||||
"""
|
||||
创建已知数据字典(索引相同),稍后使用.update()方法更新数据
|
||||
Create a known data dictionary (index the same),
|
||||
and then use the .update() method to update the data
|
||||
"""
|
||||
|
||||
result_data = {
|
||||
'status': 'success',
|
||||
'message': "更多接口请查看(More API see): https://api-v2.douyin.wtf/docs",
|
||||
'type': url_type,
|
||||
'platform': url_platform,
|
||||
'aweme_id': video_id,
|
||||
'official_api_url':
|
||||
{
|
||||
"User-Agent": self.headers["User-Agent"],
|
||||
"api_url": f"https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={video_id}"
|
||||
} if url_platform == 'douyin'
|
||||
else
|
||||
{
|
||||
"User-Agent": self.tiktok_api_headers["User-Agent"],
|
||||
"api_url": f'https://api16-normal-c-useast1a.tiktokv.com/aweme/v1/feed/?aweme_id={video_id}&iid=6165993682518218889&device_id={random.randint(10*10*10, 9*10**10)}&aid=1180'
|
||||
},
|
||||
'desc': data.get("desc"),
|
||||
'create_time': data.get("create_time"),
|
||||
'author': data.get("author"),
|
||||
'music': data.get("music"),
|
||||
'statistics': data.get("statistics"),
|
||||
'cover_data': {
|
||||
'cover': data.get("video").get("cover"),
|
||||
'origin_cover': data.get("video").get("origin_cover"),
|
||||
'dynamic_cover': data.get("video").get("dynamic_cover")
|
||||
},
|
||||
'hashtags': data.get('text_extra'),
|
||||
}
|
||||
# 创建一个空变量,稍后使用.update()方法更新数据/Create an empty variable and use the .update() method to update the data
|
||||
api_data = None
|
||||
# 判断链接类型并处理数据/Judge link type and process data
|
||||
try:
|
||||
# 抖音数据处理/Douyin data processing
|
||||
if url_platform == 'douyin':
|
||||
# 抖音视频数据处理/Douyin video data processing
|
||||
if url_type == 'video':
|
||||
print("正在处理抖音视频数据...")
|
||||
# 将信息储存在字典中/Store information in a dictionary
|
||||
uri = data['video']['play_addr']['uri']
|
||||
wm_video_url = data['video']['play_addr']['url_list'][0]
|
||||
wm_video_url_HQ = f"https://aweme.snssdk.com/aweme/v1/playwm/?video_id={uri}&radio=1080p&line=0"
|
||||
nwm_video_url = wm_video_url.replace('playwm', 'play')
|
||||
nwm_video_url_HQ = f"https://aweme.snssdk.com/aweme/v1/play/?video_id={uri}&ratio=1080p&line=0"
|
||||
api_data = {
|
||||
'video_data':
|
||||
{
|
||||
'wm_video_url': wm_video_url,
|
||||
'wm_video_url_HQ': wm_video_url_HQ,
|
||||
'nwm_video_url': nwm_video_url,
|
||||
'nwm_video_url_HQ': nwm_video_url_HQ
|
||||
}
|
||||
}
|
||||
# 抖音图片数据处理/Douyin image data processing
|
||||
elif url_type == 'image':
|
||||
print("正在处理抖音图片数据...")
|
||||
# 无水印图片列表/No watermark image list
|
||||
no_watermark_image_list = []
|
||||
# 有水印图片列表/With watermark image list
|
||||
watermark_image_list = []
|
||||
# 遍历图片列表/Traverse image list
|
||||
for i in data['images']:
|
||||
no_watermark_image_list.append(i['url_list'][0])
|
||||
watermark_image_list.append(i['download_url_list'][0])
|
||||
api_data = {
|
||||
'image_data':
|
||||
{
|
||||
'no_watermark_image_list': no_watermark_image_list,
|
||||
'watermark_image_list': watermark_image_list
|
||||
}
|
||||
}
|
||||
# TikTok数据处理/TikTok data processing
|
||||
elif url_platform == 'tiktok':
|
||||
# TikTok视频数据处理/TikTok video data processing
|
||||
if url_type == 'video':
|
||||
print("正在处理TikTok视频数据...")
|
||||
# 将信息储存在字典中/Store information in a dictionary
|
||||
wm_video = data['video']['download_addr']['url_list'][0]
|
||||
api_data = {
|
||||
'video_data':
|
||||
{
|
||||
'wm_video_url': wm_video,
|
||||
'wm_video_url_HQ': wm_video,
|
||||
'nwm_video_url': data['video']['play_addr']['url_list'][0],
|
||||
'nwm_video_url_HQ': data['video']['bit_rate'][0]['play_addr']['url_list'][0]
|
||||
}
|
||||
}
|
||||
# TikTok图片数据处理/TikTok image data processing
|
||||
elif url_type == 'image':
|
||||
print("正在处理TikTok图片数据...")
|
||||
# 无水印图片列表/No watermark image list
|
||||
no_watermark_image_list = []
|
||||
# 有水印图片列表/With watermark image list
|
||||
watermark_image_list = []
|
||||
for i in data['image_post_info']['images']:
|
||||
no_watermark_image_list.append(i['display_image']['url_list'][0])
|
||||
watermark_image_list.append(i['owner_watermark_image']['url_list'][0])
|
||||
api_data = {
|
||||
'image_data':
|
||||
{
|
||||
'no_watermark_image_list': no_watermark_image_list,
|
||||
'watermark_image_list': watermark_image_list
|
||||
}
|
||||
}
|
||||
# 更新数据/Update data
|
||||
result_data.update(api_data)
|
||||
# print("数据处理完成,最终数据: \n{}".format(result_data))
|
||||
# 返回数据/Return data
|
||||
return result_data
|
||||
except Exception as e:
|
||||
traceback.print_exc()
|
||||
print("数据处理失败!")
|
||||
return {'status': 'failed', 'message': '数据处理失败!/Data processing failed!'}
|
||||
else:
|
||||
print("[抖音|TikTok方法]返回数据为空,无法处理!")
|
||||
return {'status': 'failed',
|
||||
'message': '返回数据为空,无法处理!/Return data is empty and cannot be processed!'}
|
||||
else:
|
||||
print('获取视频ID失败!')
|
||||
return {'status': 'failed', 'message': '获取视频ID失败!/Failed to get video ID!'}
|
||||
|
||||
# 处理数据方便快捷指令使用/Process data for easy-to-use shortcuts
|
||||
@staticmethod
|
||||
def hybrid_parsing_minimal(data: dict) -> dict:
|
||||
# 如果数据获取成功/If the data is successfully obtained
|
||||
if data['status'] == 'success':
|
||||
result = {
|
||||
'status': 'success',
|
||||
'message': data.get('message'),
|
||||
'platform': data.get('platform'),
|
||||
'type': data.get('type'),
|
||||
'desc': data.get('desc'),
|
||||
'wm_video_url': data['video_data']['wm_video_url'] if data['type'] == 'video' else None,
|
||||
'wm_video_url_HQ': data['video_data']['wm_video_url_HQ'] if data['type'] == 'video' else None,
|
||||
'nwm_video_url': data['video_data']['nwm_video_url'] if data['type'] == 'video' else None,
|
||||
'nwm_video_url_HQ': data['video_data']['nwm_video_url_HQ'] if data['type'] == 'video' else None,
|
||||
'no_watermark_image_list': data['image_data']['no_watermark_image_list'] if data[
|
||||
'type'] == 'image' else None,
|
||||
'watermark_image_list': data['image_data']['watermark_image_list'] if data['type'] == 'image' else None
|
||||
}
|
||||
return result
|
||||
else:
|
||||
return data
|
||||
|
||||
|
||||
"""__________________________________________⬇️Test methods(测试方法)⬇️______________________________________"""
|
||||
|
||||
|
||||
async def async_test(douyin_url: str = None, tiktok_url: str = None) -> None:
|
||||
# 异步测试/Async test
|
||||
start_time = time.time()
|
||||
print("正在进行异步测试...")
|
||||
|
||||
print("正在测试异步获取抖音视频ID方法...")
|
||||
douyin_id = await api.get_douyin_video_id(douyin_url)
|
||||
print("正在测试异步获取抖音视频数据方法...")
|
||||
douyin_data = await api.get_douyin_video_data(douyin_id)
|
||||
|
||||
print("正在测试异步获取TikTok视频ID方法...")
|
||||
tiktok_id = await api.get_tiktok_video_id(tiktok_url)
|
||||
print("正在测试异步获取TikTok视频数据方法...")
|
||||
tiktok_data = await api.get_tiktok_video_data(tiktok_id)
|
||||
|
||||
print("正在测试异步混合解析方法...")
|
||||
douyin_hybrid_data = await api.hybrid_parsing(douyin_url)
|
||||
tiktok_hybrid_data = await api.hybrid_parsing(tiktok_url)
|
||||
|
||||
# 总耗时/Total time
|
||||
total_time = round(time.time() - start_time, 2)
|
||||
print("异步测试完成,总耗时: {}s".format(total_time))
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
api = Scraper()
|
||||
# 运行测试
|
||||
douyin_url = 'https://v.douyin.com/rLyrQxA/6.66'
|
||||
tiktok_url = 'https://vt.tiktok.com/ZSRwWXtdr/'
|
||||
asyncio.run(async_test(douyin_url=douyin_url, tiktok_url=tiktok_url))
|
||||
@ -1,42 +0,0 @@
|
||||
#! /usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# RUN Command Line:
|
||||
# 1.Build-check dist folder
|
||||
# python setup.py sdist bdist_wheel
|
||||
# 2.Upload to PyPi
|
||||
# twine upload dist/*
|
||||
|
||||
import setuptools
|
||||
|
||||
with open("README.md", "r", encoding='utf8') as fh:
|
||||
long_description = fh.read()
|
||||
|
||||
setuptools.setup(
|
||||
name='douyin_tiktok_scraper',
|
||||
author='Evil0ctal',
|
||||
version='1.0.7',
|
||||
license='MIT License',
|
||||
description='Douyin/TikTok async data scraper.',
|
||||
long_description=long_description,
|
||||
long_description_content_type="text/markdown",
|
||||
author_email='Evil0ctal1985@gmail.com',
|
||||
url='https://github.com/Evil0ctal/Douyin_TikTok_Download_API',
|
||||
packages=setuptools.find_packages(),
|
||||
keywords='TikTok, Douyin, 抖音, Scraper, Crawler, API, Download, Video, No Watermark, Async',
|
||||
# 依赖包
|
||||
install_requires=[
|
||||
'aiohttp',
|
||||
"orjson",
|
||||
"tenacity",
|
||||
],
|
||||
classifiers=[
|
||||
"Programming Language :: Python :: 3",
|
||||
"Programming Language :: Python :: 3.6",
|
||||
"Programming Language :: Python :: 3.7",
|
||||
"Programming Language :: Python :: 3.8",
|
||||
"Programming Language :: Python :: 3.9",
|
||||
"Programming Language :: Python :: 3.10",
|
||||
"Programming Language :: Python :: 3 :: Only",
|
||||
],
|
||||
python_requires='>=3.6',
|
||||
)
|
||||
Loading…
x
Reference in New Issue
Block a user